湖仓一体电商项目:项目数据种类与采集
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了湖仓一体电商项目:项目数据种类与采集相关的知识,希望对你有一定的参考价值。

文章目录
1、首先停止mysql,然后在mysql节点配置my.ini文件
项目数据种类与采集
实时数仓项目中的数据分为两类,一类是业务系统产生的业务数据,这部分数据存储在mysql数据库中,另一类是实时用户日志行为数据,这部分数据是用户登录系统产生的日志数据。
针对MySQL日志数据我们采用maxwell全量或者增量实时采集到大数据平台中,针对用户日志数据,通过log4j日志将数据采集到目录中,再通过Flume实时同步到大数据平台,总体数据采集思路如下图所示:
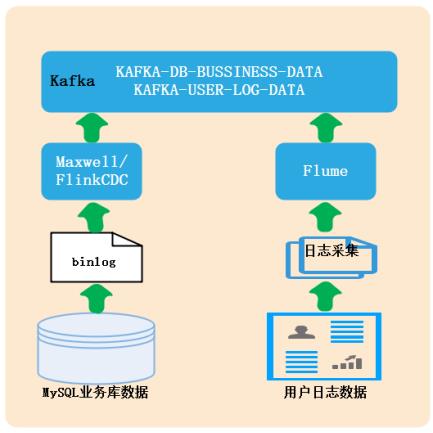
针对MySQL业务数据和用户日志数据构建离线+实时湖仓一体数据分析平台,我们暂时划分为会员主题和商品主题。下面了解下主题各类表情况。
一、MySQL业务数据
1、配置MySQL支持UTF8编码
在node2节点上配“/etc/my.cnf”文件,在对应的标签下加入如下配置,更改mysql数据库编码格式为utf-8:
[mysqld]
character-set-server=utf8
[client]
default-character-set = utf8修改完成之后重启mysql即可。
2、MySQL数据表
MySQL业务数据存储在库“lakehousedb”中,此数据库中的业务数据表如下:
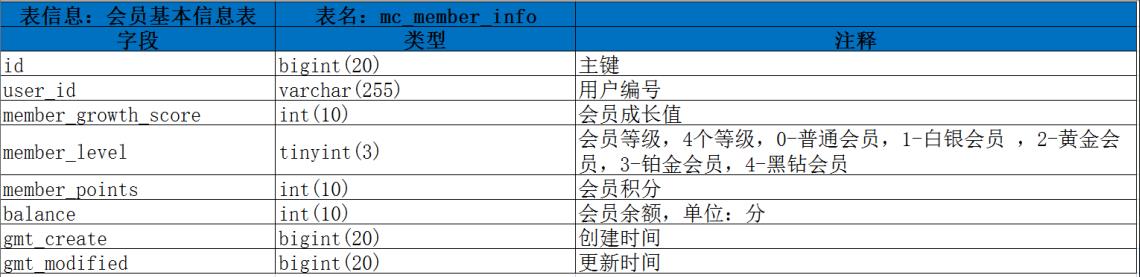
2.1、会员基本信息表 : mc_member_info
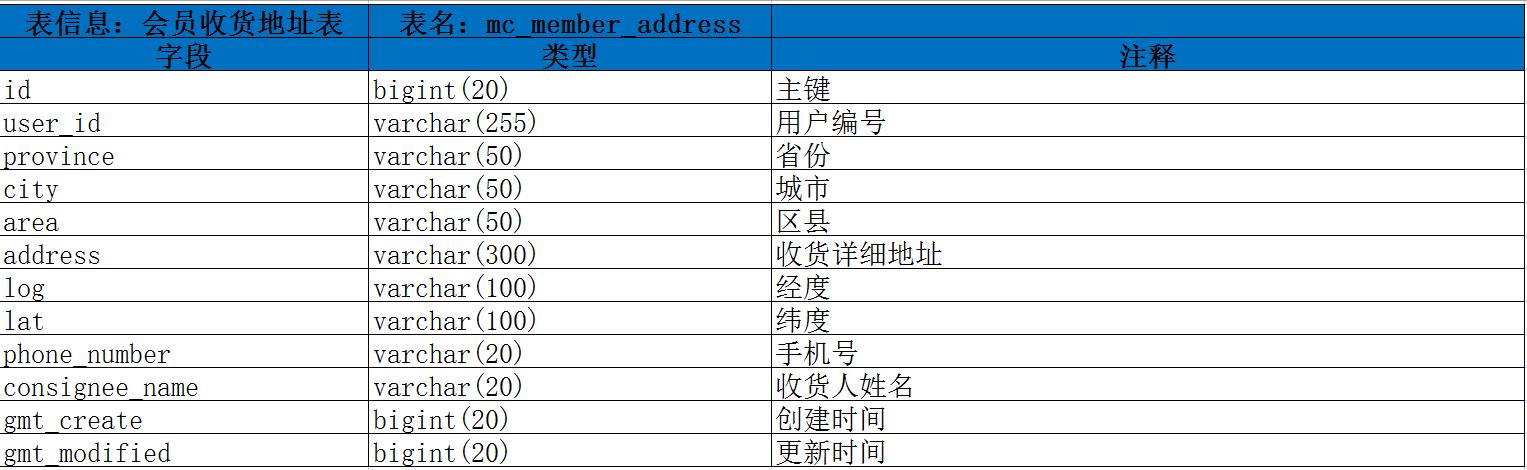
2.2、 会员收货地址表 : mc_member_address
2.3、用户登录数据表 : mc_user_login

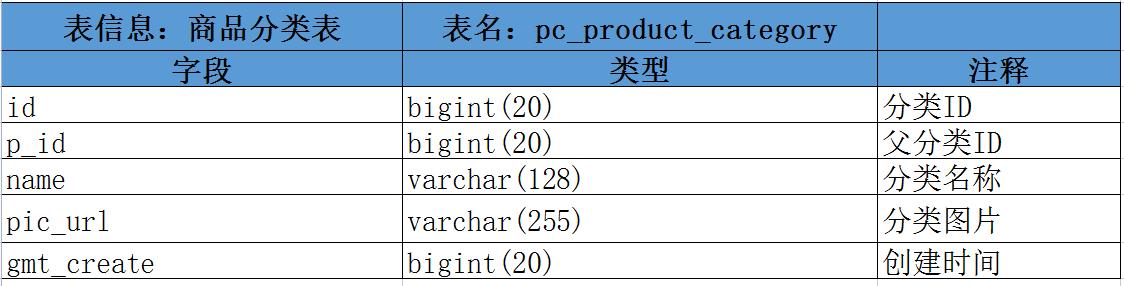
2.4、商品分类表 : pc_product_category
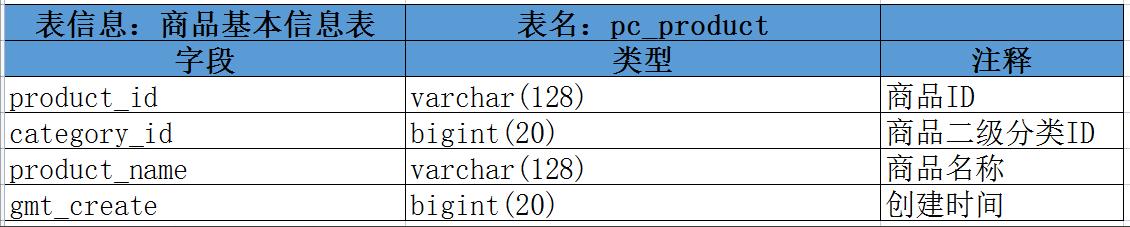
2.5、商品基本信息表 : pc_product
3、MySQL业务数据采集
我们通过maxwell数据同步工具监控MySQL binlog日志将MySQL日志数据同步到Kafka topic “KAFKA-DB-BUSSINESS-DATA”中,详细步骤如下:
3.1、配置maxwell config.properties文件
进入node3“/software/maxwell-1.28.2”目录,配置config.properties文件,主要是配置监控mysql日志数据对应的Kafka topic,配置详细内容如下:
producer=kafka
kafka.bootstrap.servers=node1:9092,node2:9092,node3:9092
kafka_topic=KAFKA-DB-BUSSINESS-DATA
#设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]
producer_partition_by=table
#mysql 节点
host=node2
#连接mysql用户名和密码
user=maxwell
password=maxwell
#指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用
client_id=maxwell_first
3.2、启动kafka,创建Kafka topic,并监控Kafka topic
启动Zookeeper集群、Kafka 集群,创建topic“KAFKA-DB-BUSSINESS-DATA” topic:
#进入Kafka路径,创建对应topic
[root@node1 ~]# cd /software/kafka_2.11-0.11.0.3/bin/
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DB-BUSSINESS-DATA --partitions 3 --replication-factor 3
#监控Kafak topic 中的数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DB-BUSSINESS-DATA3.3、启动maxwell
#在node3节点上启动maxwell
[root@node3 ~]# cd /software/maxwell-1.28.2/bin/
[root@node3 bin]# maxwell --config ../config.properties3.4、在mysql中创建“lakehousedb”并导入数据
#进入mysql ,创建数据库lakehousedb
[root@node2 ~]# mysql -u root -p123456
mysql> create database lakehousedb;打开“Navicat”工具,将资料中的“lakehousedb.sql”文件导入到MySQL数据库“lakehousedb”中,我们可以看到在对应的kafka topic “KAFKA-DB-BUSSINESS-DATA”中会有数据被采集过来。

二、用户日志数据
1、用户日志数据
目前用户日志数据只有“会员浏览商品日志数据”,其详细信息如下:
- 接口地址:/collector/common/browselog
- 请求方式:post
- 请求数据类型:application/json
- 接口描述:用户登录系统后,会有当前登录时间信息及当前用户登录后浏览商品,跳转链接、浏览所获积分等信息
- 请求示例:
"logTime": 1646393162044,
"userId": "uid53439497",
"userIp": "216.36.11.233",
"frontProductUrl": "https://fo0z7oZj/rInrtrb/ui",
"browseProductUrl": "https://2/5Rwwx/SqqwwwOUsK4",
"browseProductTpCode": "202",
"browseProductCode": "q6HCcpwfdgfgfxd2I",
"obtainPoints": 16,
- 请求参数解释如下:
| 参数名称 | 参数说明 |
| logTime | 浏览日志时间 |
| userId | 用户编号 |
| userIp | 浏览Ip地址 |
| frontProductUrl | 跳转前URL地址,有为null,有的不为null |
| browseProductUrl | 浏览商品URL |
| browseProductTpCode | 浏览商品二级分类 |
| browseProductCode | 浏览商品编号 |
| obtainPoints | 浏览商品所获积分 |
2、用户日志数据采集
日志数据采集是通过log4j日志配置来将用户的日志数据集中获取,这里我们编写日志采集接口项目“LogCollector”来采集用户日志数据。
当用户浏览网站触发对应的接口时,日志采集接口根据配合的log4j将用户浏览信息写入对应的目录中,然后通过Flume监控对应的日志目录,将用户日志数据采集到Kafka topic “KAFKA-USER-LOG-DATA”中。
这里我们自己模拟用户浏览日志数据,将用户浏览日志数据采集到Kafka中,详细步骤如下:
2.1、将日志采集接口项目打包,上传到node5节点
将日志采集接口项目“LogCollector”项目配置成生产环境prod,打包,上传到node5节点目录/software下。
2.2、编写Flume 配置文件a.properties
将a.properties存放在node5节点/software目录下,文件配置内容如下:
#设置source名称
a.sources = r1
#设置channel的名称
a.channels = c1
#设置sink的名称
a.sinks = k1
# For each one of the sources, the type is defined
#设置source类型为TAILDIR,监控目录下的文件
#Taildir Source可实时监控目录一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题
a.sources.r1.type = TAILDIR
#文件的组,可以定义多种
a.sources.r1.filegroups = f1
#第一组监控的是对应文件夹中的什么文件:.log文件
a.sources.r1.filegroups.f1 = /software/lakehouselogs/userbrowse/.*log
# The channel can be defined as follows.
#设置source的channel名称
a.sources.r1.channels = c1
a.sources.r1.max-line-length = 1000000
#a.sources.r1.eventSize = 512000000
# Each channel's type is defined.
#设置channel的类型
a.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
#设置channel道中最大可以存储的event数量
a.channels.c1.capacity = 1000
#每次最大从source获取或者发送到sink中的数据量
a.channels.c1.transcationCapacity=100
# Each sink's type must be defined
#设置Kafka接收器
a.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
a.sinks.k1.brokerList=node1:9092,node2:9092,node3:9092
#设置Kafka的Topic
a.sinks.k1.topic=KAFKA-USER-LOG-DATA
#设置序列化方式
a.sinks.k1.serializer.class=kafka.serializer.StringEncoder
#Specify the channel the sink should use
#设置sink的channel名称
a.sinks.k1.channel = c12.3、在Kafka中创建对应的topic并监控
#进入Kafka路径,创建对应topic
[root@node1 ~]# cd /software/kafka_2.11-0.11.0.3/bin/
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-USER-LOG-DATA --partitions 3 --replication-factor 3
#监控Kafak topic 中的数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-USER-LOG-DATA2.4、启动日志采集接口
在node5节点上启动日志采集接口,启动命令如下:
[root@node5 ~]# cd /software/
[root@node5 software]# java -jar ./logcollector-0.0.1-SNAPSHOT.jar 启动之后,根据日志采集接口配置会在“/software/lakehouselogs/userbrowse”目录中汇集用户浏览商品日志数据。
2.5、 启动Flume,监控用户日志数据到Kafka
在node5节点上启动Flume,监控用户浏览日志数据到Kafka “KAFKA-USER-LOG-DATA” topic。
[root@node5 ~]# cd /software/
[root@node5 software]# flume-ng agent --name a -f /software/a.properties -Dflume.root.logger=INFO,console2.6、启动模拟用户浏览日志代码,向日志采集接口生产数据
在window本地启动“LakeHouseMockData”项目下的“RTMockUserLogData”代码,向日志采集接口中生产用户浏览商品日志数据。
启动代码后,我们会在Kafka “KAFKA-USER-LOG-DATA” topic 中看到监控到的用户日志数据。

三、错误解决
如果在向mysql中创建库及表时有如下错误:
[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
以上错误是由于MySQL sql_mode引起,对于group by聚合操作,如果在select中的列没有在group by中出现,那么这个SQL是不合法的。按照以下步骤来处理。
1、首先停止mysql,然后在mysql节点配置my.ini文件
[root@node2 ~]# service mysqld stop打开/etc/my.cnf文件,在[mysqld]标签下配置如下内容:
[mysqld]
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
2、重启mysql即可解决
[root@node2 ~]# service mysqld start- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于湖仓一体电商项目:项目数据种类与采集的主要内容,如果未能解决你的问题,请参考以下文章
湖仓一体电商项目(十六):业务实现之编写写入ODS层业务代码