湖仓一体电商项目:编写写入DM层业务代码
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了湖仓一体电商项目:编写写入DM层业务代码相关的知识,希望对你有一定的参考价值。

文章目录
编写写入DM层业务代码
DM层主要是报表数据,针对实时业务将DM层设置在Clickhouse中,在此业务中DM层主要存储的是通过Flink读取Kafka “KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC” topic中的数据进行设置窗口分析,每隔10s设置滚动窗口统计该窗口内访问商品及商品一级、二级分类分析结果,实时写入到Clickhouse中。
一、代码编写
具体代码参照“ProcessBrowseLogInfoToDM.scala”,大体代码逻辑如下:
object ProcessBrowseLogInfoToDM
def main(args: Array[String]): Unit =
//1.准备环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
env.enableCheckpointing(5000)
import org.apache.flink.streaming.api.scala._
/**
* 2.创建 Kafka Connector,连接消费Kafka dwd中数据
*
*/
tblEnv.executeSql(
"""
|create table kafka_dws_user_login_wide_tbl (
| user_id string,
| product_name string,
| first_category_name string,
| second_category_name string,
| obtain_points string
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DWS-BROWSE-LOG-WIDE-TOPIC',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='earliest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
/**
* 3.实时统计每个用户最近10s浏览的商品次数和商品一级、二级种类次数,存入到Clickhouse
*/
val dwsTbl:Table = tblEnv.sqlQuery(
"""
| select user_id,product_name,first_category_name,second_category_name from kafka_dws_user_login_wide_tbl
""".stripMargin)
//4.将Row 类型数据转换成对象类型操作
val browseDS: DataStream[BrowseLogWideInfo] = tblEnv.toAppendStream[Row](dwsTbl)
.map(row =>
val user_id: String = row.getField(0).toString
val product_name: String = row.getField(1).toString
val first_category_name: String = row.getField(2).toString
val second_category_name: String = row.getField(3).toString
BrowseLogWideInfo(null, user_id, null, product_name, null, null, first_category_name, second_category_name, null)
)
val dwsDS: DataStream[ProductVisitInfo] = browseDS.keyBy(info =>
info.first_category_name + "-" + info.second_category_name + "-" + info.product_name
)
.timeWindow(Time.seconds(10))
.process(new ProcessWindowFunction[BrowseLogWideInfo, ProductVisitInfo, String, TimeWindow]
override def process(key: String, context: Context, elements: Iterable[BrowseLogWideInfo], out: Collector[ProductVisitInfo]): Unit =
val currentDt: String = DateUtil.getDateYYYYMMDD(context.window.getStart.toString)
val startTime: String = DateUtil.getDateYYYYMMDDHHMMSS(context.window.getStart.toString)
val endTime: String = DateUtil.getDateYYYYMMDDHHMMSS(context.window.getEnd.toString)
val arr: Array[String] = key.split("-")
val firstCatName: String = arr(0)
val secondCatName: String = arr(1)
val productName: String = arr(2)
val cnt: Int = elements.toList.size
out.collect(ProductVisitInfo(currentDt, startTime, endTime, firstCatName, secondCatName, productName, cnt))
)
/**
* 5.将以上结果写入到Clickhouse表 dm_product_visit_info 表中
* create table dm_product_visit_info(
* current_dt String,
* window_start String,
* window_end String,
* first_cat String,
* second_cat String,
* product String,
* product_cnt UInt32
* ) engine = MergeTree() order by current_dt
*
*/
//准备向ClickHouse中插入数据的sql
val insertIntoCkSql = "insert into dm_product_visit_info (current_dt,window_start,window_end,first_cat,second_cat,product,product_cnt) values (?,?,?,?,?,?,?)"
val ckSink: SinkFunction[ProductVisitInfo] = MyClickHouseUtil.clickhouseSink[ProductVisitInfo](insertIntoCkSql,new JdbcStatementBuilder[ProductVisitInfo]
override def accept(pst: PreparedStatement, productVisitInfo: ProductVisitInfo): Unit =
pst.setString(1,productVisitInfo.currentDt)
pst.setString(2,productVisitInfo.windowStart)
pst.setString(3,productVisitInfo.windowEnd)
pst.setString(4,productVisitInfo.firstCat)
pst.setString(5,productVisitInfo.secondCat)
pst.setString(6,productVisitInfo.product)
pst.setLong(7,productVisitInfo.productCnt)
)
//针对数据加入sink
dwsDS.addSink(ckSink)
env.execute()
二、创建Clickhouse-DM层表
代码在执行之前需要在Clickhouse中创建对应的DM层商品浏览信息表dm_product_visit_info,clickhouse建表语句如下:
#node1节点启动clickhouse
[root@node1 bin]# service clickhouse-server start
#node1节点进入clickhouse
[root@node1 bin]# clickhouse-client -m
#node1节点创建clickhouse-DM层表
create table dm_product_visit_info(
current_dt String,
window_start String,
window_end String,
first_cat String,
second_cat String,
product String,
product_cnt UInt32
) engine = MergeTree() order by current_dt;三、代码测试
以上代码编写完成后,代码执行测试步骤如下:
1、将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动向日志采集接口模拟生产日志代码“RTMockUserLogData.java”,需要启动日志采集接口及Flume。
2、执行代码,查看对应结果
以上代码执行后在,在Clickhouse-DM层中表“dm_product_visit_info”中查看对应数据结果如下:
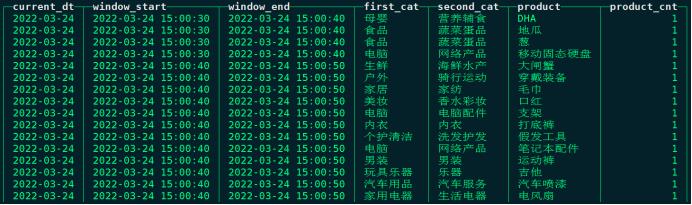
四、架构图
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于湖仓一体电商项目:编写写入DM层业务代码的主要内容,如果未能解决你的问题,请参考以下文章