湖仓一体电商项目:业务实现之编写写入ODS层业务代码
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了湖仓一体电商项目:业务实现之编写写入ODS层业务代码相关的知识,希望对你有一定的参考价值。

文章目录
二、创建Iceberg-ODS层表
业务实现之编写写入ODS层业务代码
ODS层在湖仓一体架构中主要是存储原始数据,这里主要是读取Kafka “KAFKA-DB-BUSSINESS-DATA”topic中的数据实现如下两个方面功能:
- 将mysql业务数据原封不动的存储在Iceberg-ODS层中方便项目临时业务需求使用。
- 将事实数据和维度数据进行分离,分别存储Kafka对应的topic中
以上两个方面中第一个方面需要再Hive中预先创建对应的Iceberg表,才能写入,第二个方面不好分辨topic“KAFKA-DB-BUSSINESS-DATA”中哪些binlog数据是事实数据哪些binlog是维度数据,所以这里我们在mysql 配置表“lakehousedb.dim_tbl_config_info”中写入表信息,这样通过Flink获取此表维度表信息进行广播与Kafka实时流进行关联将事实数据和维度数据进行区分。
一、代码编写
数据写入ODS层代码是“ProduceKafkaDBDataToODS.scala”,主要代码逻辑实现如下:
object ProduceKafkaDBDataToODS
private val mysqlUrl: String = ConfigUtil.MYSQL_URL
private val mysqlUser: String = ConfigUtil.MYSQL_USER
private val mysqlPassWord: String = ConfigUtil.MYSQL_PASSWORD
private val kafkaBrokers: String = ConfigUtil.KAFKA_BROKERS
private val kafkaDimTopic: String = ConfigUtil.KAFKA_DIM_TOPIC
private val kafkaOdsTopic: String = ConfigUtil.KAFKA_ODS_TOPIC
private val kafkaDwdUserLogTopic: String = ConfigUtil.KAFKA_DWD_USERLOG_TOPIC
def main(args: Array[String]): Unit =
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
import org.apache.flink.streaming.api.scala._
env.enableCheckpointing(5000)
/**
* 1.需要预先创建 Catalog
* 创建Catalog,创建表需要在Hive中提前创建好,不在代码中创建,因为在Flink中创建iceberg表不支持create table if not exists ...语法
*/
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
/**
* 2.创建 Kafka Connector,连接消费Kafka中数据
* 注意:1).关键字要使用 " 飘"符号引起来 2).对于json对象使用 map < String,String>来接收
*/
tblEnv.executeSql(
"""
|create table kafka_db_bussiness_tbl(
| database string,
| `table` string,
| type string,
| ts string,
| xid string,
| `commit` string,
| data map<string,string>
|) with (
| 'connector' = 'kafka',
| 'topic' = 'KAFKA-DB-BUSSINESS-DATA',
| 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092',
| 'scan.startup.mode'='latest-offset', --也可以指定 earliest-offset 、latest-offset
| 'properties.group.id' = 'my-group-id',
| 'format' = 'json'
|)
""".stripMargin)
/**
* 3.将不同的业务库数据存入各自的Iceberg表
*/
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_MEMBER_INFO
|select
| data['id'] as id ,
| data['user_id'] as user_id,
| data['member_growth_score'] as member_growth_score,
| data['member_level'] as member_level,
| data['balance'] as balance,
| data['gmt_create'] as gmt_create,
| data['gmt_modified'] as gmt_modified
| from kafka_db_bussiness_tbl where `table` = 'mc_member_info'
""".stripMargin)
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_MEMBER_ADDRESS
|select
| data['id'] as id ,
| data['user_id'] as user_id,
| data['province'] as province,
| data['city'] as city,
| data['area'] as area,
| data['address'] as address,
| data['log'] as log,
| data['lat'] as lat,
| data['phone_number'] as phone_number,
| data['consignee_name'] as consignee_name,
| data['gmt_create'] as gmt_create,
| data['gmt_modified'] as gmt_modified
| from kafka_db_bussiness_tbl where `table` = 'mc_member_address'
""".stripMargin)
tblEnv.executeSql(
"""
|insert into hadoop_iceberg.icebergdb.ODS_USER_LOGIN
|select
| data['id'] as id ,
| data['user_id'] as user_id,
| data['ip'] as ip,
| data['login_tm'] as login_tm,
| data['logout_tm'] as logout_tm
| from kafka_db_bussiness_tbl where `table` = 'mc_user_login'
""".stripMargin)
//4.读取 Kafka 中的数据,将维度数据另外存储到 Kafka 中
val kafkaTbl: Table = tblEnv.sqlQuery("select database,`table`,type,ts,xid,`commit`,data from kafka_db_bussiness_tbl")
//5.将kafkaTbl Table 转换成DStream 与MySql中的数据
val kafkaDS: DataStream[Row] = tblEnv.toAppendStream[Row](kafkaTbl)
//6.设置mapState,用于广播流
val mapStateDescriptor = new MapStateDescriptor[String,JSONObject]("mapStateDescriptor",classOf[String],classOf[JSONObject])
//7.从MySQL中获取配置信息,并广播
val bcConfigDs: BroadcastStream[JSONObject] = env.addSource(MySQLUtil.getMySQLData(mysqlUrl,mysqlUser,mysqlPassWord)).broadcast(mapStateDescriptor)
//8.设置维度数据侧输出流标记
val dimDataTag = new OutputTag[String]("dim_data")
//9.只监控mysql 数据库lakehousedb 中的数据,其他库binlog不监控,连接两个流进行处理
val factMainDs: DataStream[String] = kafkaDS.filter(row=>"lakehousedb".equals(row.getField(0).toString)).connect(bcConfigDs).process(new BroadcastProcessFunction[Row, JSONObject, String]
override def processElement(row: Row, ctx: BroadcastProcessFunction[Row, JSONObject, String]#ReadOnlyContext, out: Collector[String]): Unit =
//最后返回给Kafka 事实数据的json对象
val returnJsonObj = new JSONObject()
//获取广播状态
val robcs: ReadOnlyBroadcastState[String, JSONObject] = ctx.getBroadcastState(mapStateDescriptor)
//解析事件流数据
val nObject: JSONObject = CommonUtil.rowToJsonObj(row)
//获取当前时间流来自的库和表 ,样例数据如下
//lackhousedb,pc_product,insert,1646659263,21603,null,gmt_create=1645493074001, category_id=220, product_name=黄金, product_id=npfSpLHB8U
val dbName: String = nObject.getString("database")
val tableName: String = nObject.getString("table")
val key = dbName + ":" + tableName
if (robcs.contains(key))
//维度数据
val jsonValue: JSONObject = robcs.get(key)
//维度数据,将对应的 jsonValue中的信息设置到流事件中
nObject.put("tbl_name", jsonValue.getString("tbl_name"))
nObject.put("tbl_db", jsonValue.getString("tbl_db"))
nObject.put("pk_col", jsonValue.getString("pk_col"))
nObject.put("cols", jsonValue.getString("cols"))
nObject.put("phoenix_tbl_name", jsonValue.getString("phoenix_tbl_name"))
ctx.output(dimDataTag, nObject.toString)
else
//事实数据,加入iceberg 表名写入Kafka ODS-DB-TOPIC topic中
if("mc_user_login".equals(tableName))
returnJsonObj.put("iceberg_ods_tbl_name","ODS_USER_LOGIN")
returnJsonObj.put("kafka_dwd_topic",kafkaDwdUserLogTopic)
returnJsonObj.put("data",nObject.toString)
out.collect(returnJsonObj.toJSONString)
override def processBroadcastElement(jsonObject: JSONObject, ctx: BroadcastProcessFunction[Row, JSONObject, String]#Context, out: Collector[String]): Unit =
val tblDB: String = jsonObject.getString("tbl_db")
val tblName: String = jsonObject.getString("tbl_name")
//向状态中更新数据
val bcs: BroadcastState[String, JSONObject] = ctx.getBroadcastState(mapStateDescriptor)
bcs.put(tblDB + ":" + tblName, jsonObject)
println("广播数据流设置完成...")
)
//10.结果写入到Kafka - dim_data_topic topic中
val props = new Properties()
props.setProperty("bootstrap.servers",kafkaBrokers)
factMainDs.addSink(new FlinkKafkaProducer[String](kafkaOdsTopic,new KafkaSerializationSchema[String]
override def serialize(element: String, timestamp: java.lang.Long): ProducerRecord[Array[Byte], Array[Byte]] =
new ProducerRecord[Array[Byte],Array[Byte]](kafkaOdsTopic,null,element.getBytes())
,props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))//暂时使用at_least_once语义,exactly_once语义有些bug问题
factMainDs.getSideOutput(dimDataTag).addSink(new FlinkKafkaProducer[String](kafkaDimTopic,new KafkaSerializationSchema[String]
override def serialize(element: String, timestamp: java.lang.Long): ProducerRecord[Array[Byte], Array[Byte]] =
new ProducerRecord[Array[Byte],Array[Byte]](kafkaDimTopic,null,element.getBytes())
,props,FlinkKafkaProducer.Semantic.AT_LEAST_ONCE))//暂时使用at_least_once语义,exactly_once语义有些bug问题
env.execute()
二、创建Iceberg-ODS层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1、在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;2、创建Iceberg表
这里创建Iceberg表有“ODS_MEMBER_INFO”、“ODS_MEMBER_ADDRESS”、“ODS_USER_LOGIN”,创建语句如下:
#在Hive客户端执行以下建表语句
CREATE TABLE ODS_MEMBER_INFO (
id string,
user_id string,
member_growth_score string,
member_level string,
balance string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_INFO/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_MEMBER_ADDRESS (
id string,
user_id string,
province string,
city string,
area string,
address string,
log string,
lat string,
phone_number string,
consignee_name string,
gmt_create string,
gmt_modified string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_MEMBER_ADDRESS/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);
CREATE TABLE ODS_USER_LOGIN (
id string,
user_id string,
ip string,
login_tm string,
logout_tm string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/ODS_USER_LOGIN/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);以上语句在Hive客户端执行完成之后,在HDFS中可以看到对应的Iceberg数据目录:
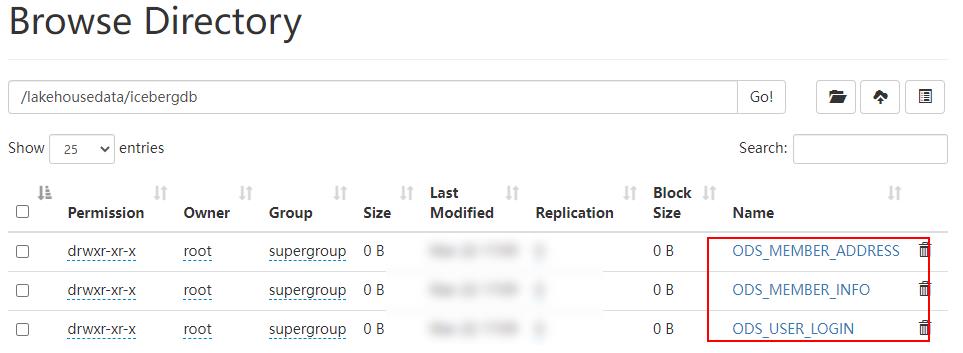
三、代码测试
以上代码编写完成后,代码执行测试步骤如下:
1、在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-ODS-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-ODS-TOPIC --partitions 3 --replication-factor 3
#在Kafka 中创建 KAFKA-DIM-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DIM-TOPIC --partitions 3 --replication-factor 3
#监控以上两个topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-ODS-TOPIC
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DIM-TOPIC2、将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动实时向MySQL表中写入数据代码“RTMockDBData.java”代码,实时向MySQL对应的表中写入数据,这里需要启动maxwell监控数据,代码才能实时监控到写入MySQL的业务数据。
3、执行代码,查看对应topic中的结果
以上代码执行后在,在对应的Kafka “KAFKA-DIM-TOPIC”和“KAFKA-ODS-TOPIC”中都有对应的数据。在Iceberg-ODS层中对应的表中也有数据。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于湖仓一体电商项目:业务实现之编写写入ODS层业务代码的主要内容,如果未能解决你的问题,请参考以下文章