目标检测YOLOv7理论简介+实践测试
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测YOLOv7理论简介+实践测试相关的知识,希望对你有一定的参考价值。
概述
YOLOv7由YOLOv4的作者团队提出,其论文一作也是YOLOR的作者。
论文的风格也和YOLOR一样,比较难懂,因此这里的理论部分也不做仔细研究,仅对论文提出的几个创新点进行翻译概括。
理论创新
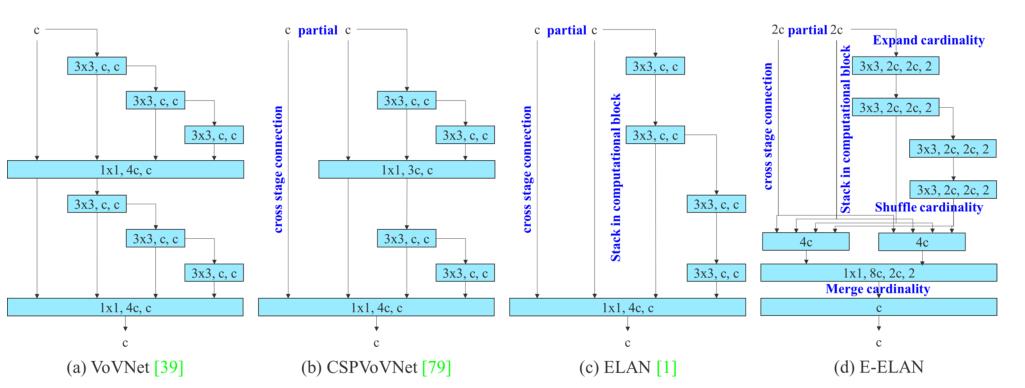
扩展的高效层聚合网络
作者提出了一个网络结构E-ELAN使用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。
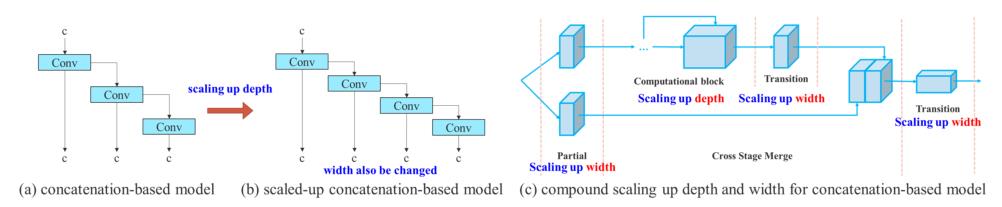
基于concatenate模型的模型缩放
作者提出了一个模型缩放方法,可以保持模型在初始设计时的特性并保持最佳结构。
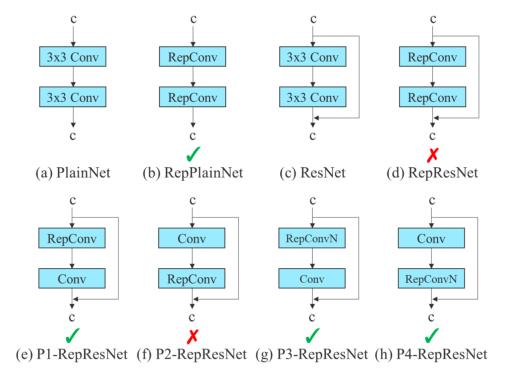
计划重参数化卷积
尽管RepConv在VGG基础上取得了优异的性能,但当将它直接应用于ResNet、DenseNet和其他架构时,它的精度将显著降低。作者使用梯度流传播路径来分析重参数化的卷积应该如何与不同的网络相结合。作者还相应地设计了计划中的重参数化的卷积。
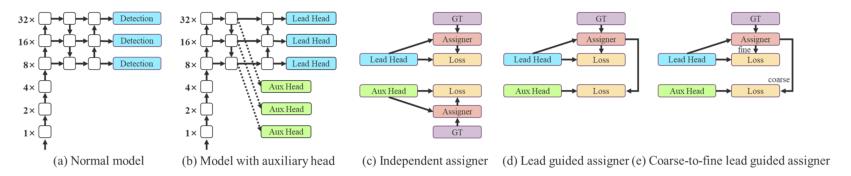
标签匹配
过去,在深度网络的训练中,标签分配通常直接指GT,并根据给定的规则生成硬标签。然而,近年来,如果以目标检测为例,研究者经常利用网络预测输出的质量和分布,然后结合GT考虑,使用一些计算和优化方法来生成可靠的软标签。例如,YOLO使用边界框回归预测和GT的IoU作为客观性的软标签。在本文中,作者将网络预测结果与GT一起考虑,然后将软标签分配为“label assigner”的机制。
最后,作者进行了一系列模型比较实验,结果如下表所示:
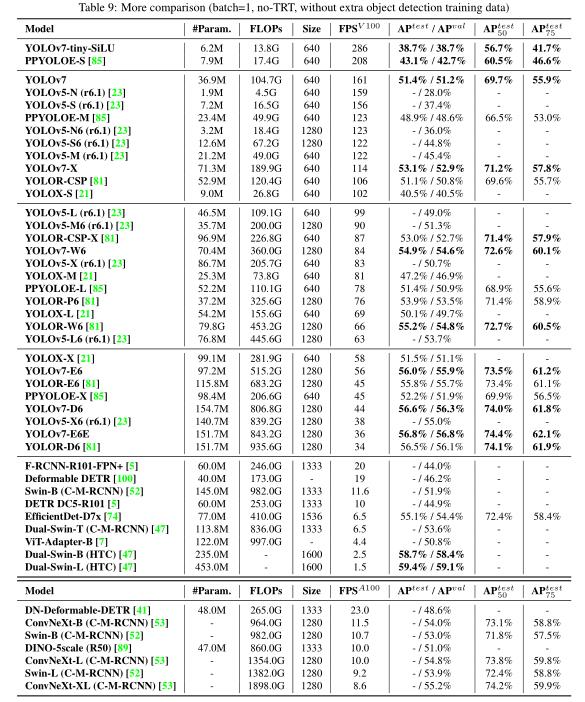
实验测试
不管前面的理论部分说得多么花里胡哨,最终还是要以实践测试结果来说明。
由于YOLOv7是基于YOLOv5代码进行修改的,因此训过YOLOv5模型的人都可以很容易得跑起来。
这里具体的流程就不再重复了,因为和【目标检测】YOLOv5跑通VisDrone数据集里面的一模一样。
这里我仍是采用VisDrone数据集,使用YOLOv7模型,添加和上篇博文里一样的训练参数,结果训练1个epoch之后,爆显存了。。

我把batch_size改成1,坚持了2个epoch,显存依旧爆炸。
于是我换用了自己的数据集,和YOLOv5-5.0做对比测试,效果如下:
| 算法 | mAP@.5 | mAP@.5:.95s |
|---|---|---|
| yolov5-5.0 | 95.6% | 67.6% |
| yolov7 | 94.8% | 67.4% |
可以看到,yolov7的效果在我自己的数据集上,效果还不如yolov5,这可能是由于我的数据集目标较大,较稀疏,检测难度不高。另外,输入的图片是640x640的尺寸,yolov7更好的模型推荐的输入尺寸是1280x1280。不过,对我这个6GB的渣显卡来说,无法进行测试验证。等我以后有机会换设备再尝试。。
代码备份
YOLOv7代码备份:https://pan.baidu.com/s/1gj5TAOH-z8_kLJDDQxlKfg?pwd=8888
包含yolov7.pt,yolov7-e6e.pt两个预训练模型
以上是关于目标检测YOLOv7理论简介+实践测试的主要内容,如果未能解决你的问题,请参考以下文章
目标检测YOLOv6理论解读+实践测试VisDrone数据集
目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试
目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试