目标检测YOLOv6理论解读+实践测试VisDrone数据集
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测YOLOv6理论解读+实践测试VisDrone数据集相关的知识,希望对你有一定的参考价值。
前言
本篇博文将简单总结YOLOv6的原理,并使用YOLOv6对VisDrone数据集进行训练。
背景
YOLOv6是美团视觉智能部研发的一款目标检测框架,致力于工业应用。
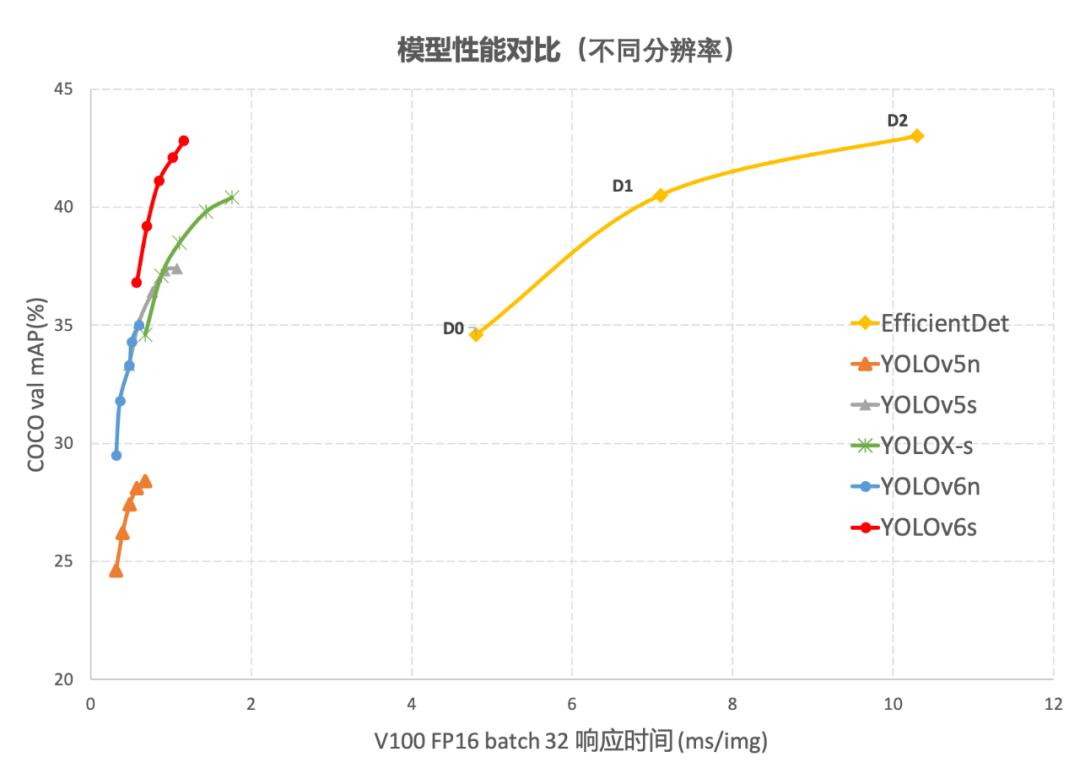
根据官方[1]提供的测试结果,YOLOv6的综合性能效果超越了YOLOv5和YOLOX,如下图所示,YOLOv6s在COCO验证集上的mAP数值最高。
网络结构优化
由于YOLOv6没有相关论文,下面这些创新点描述均参考自官方的介绍博文[1]
EfficientRep Backbone
YOLOv5/YOLOX 使用的 Backbone 和 Neck 都基于 CSPNet 搭建,采用了多分支的方式和残差结构。对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。因此,YOLOv6对Backbone 和 Neck 都进行了重新设计。
Backbone部分,提出了一种叫做 EfficientRep Backbone 的结构,结构图如下:
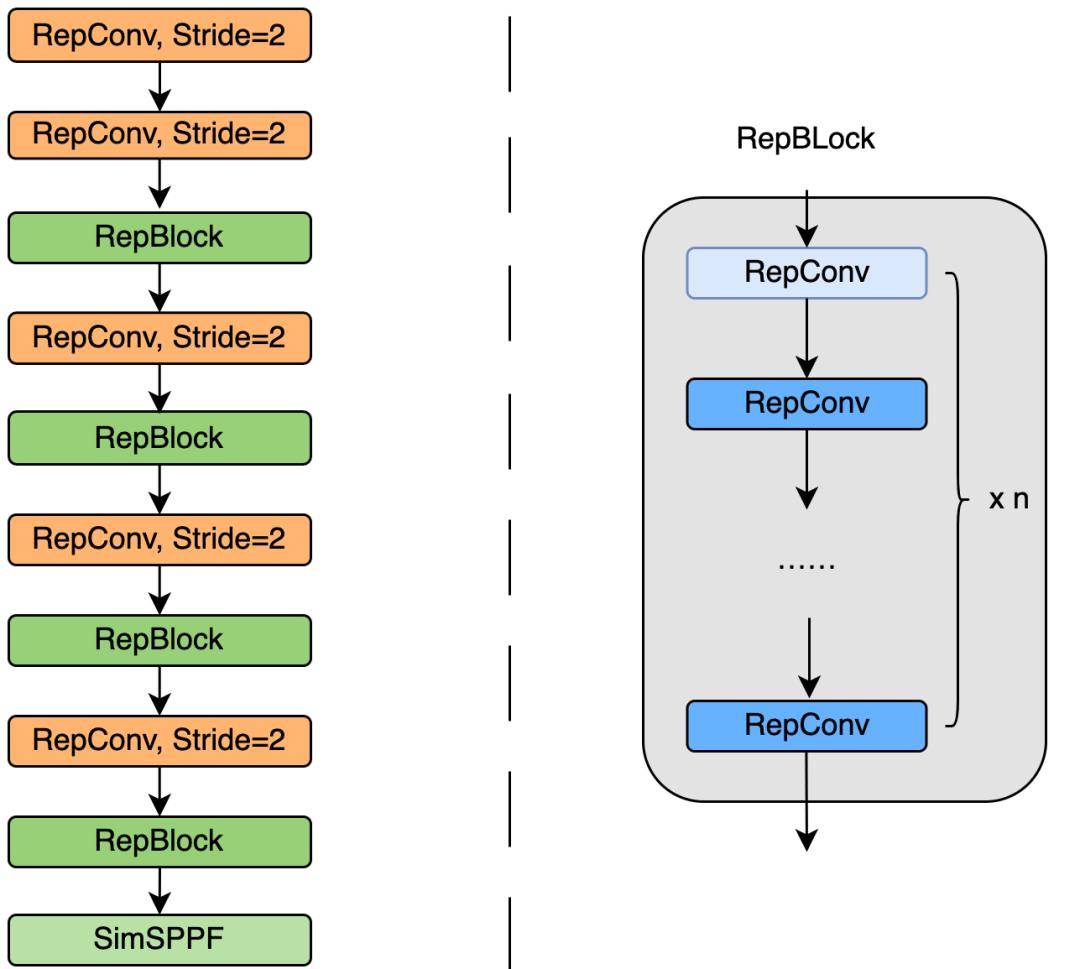
图里的RepConv,RepBlock,SimSPPF均为全新的结构,这里不作更细的探究。
Rep-PAN
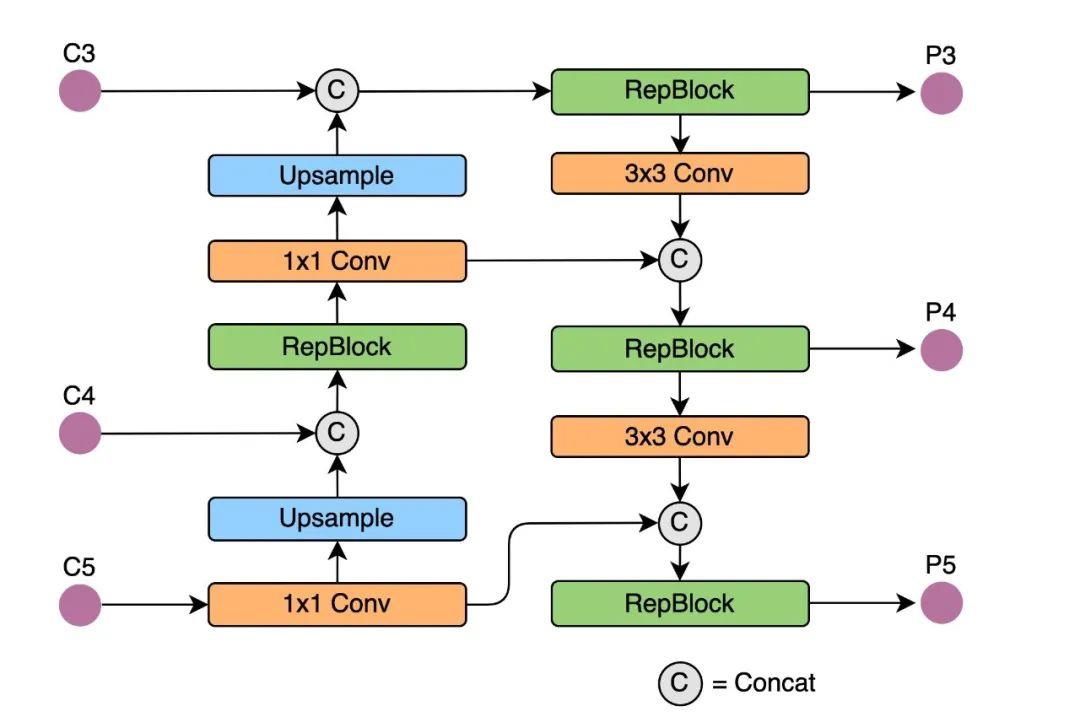
在 Neck 设计方面,YOLOv6提出了一种命名为Rep-PAN的结构,结构示意图如下:
Decoupled Head
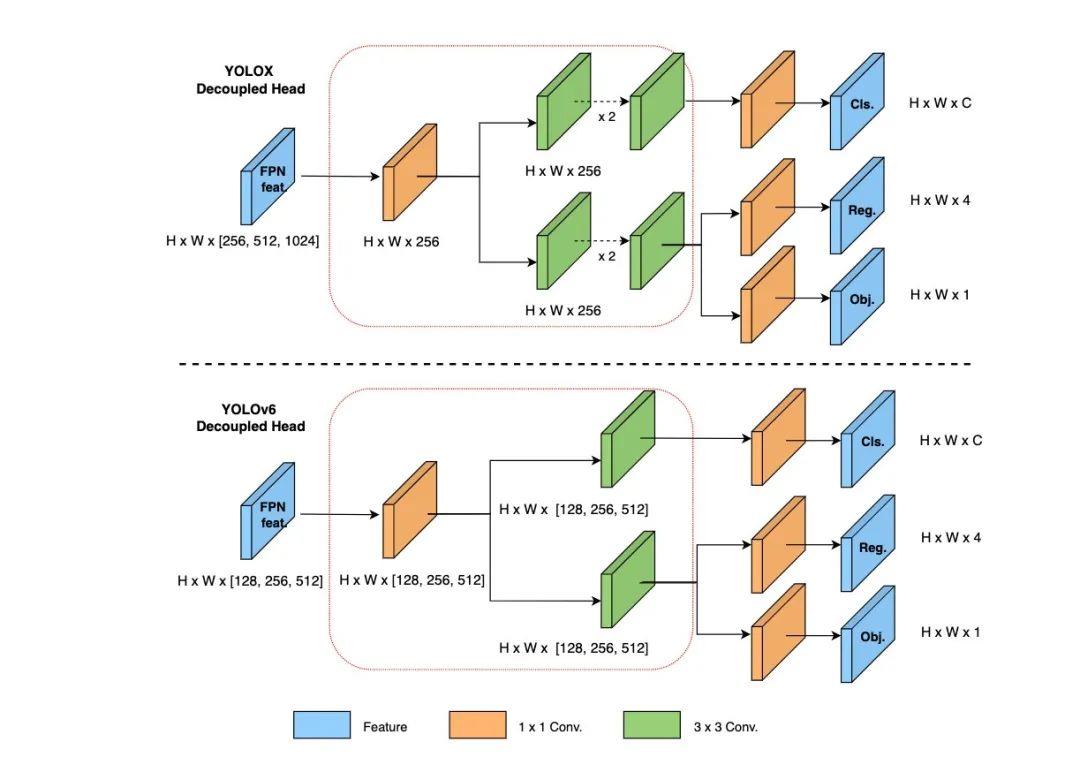
在检测头方面,YOLOv6借鉴了YOLOX的思路,采用了解耦检测头(Decoupled Head)结构,并对其进行精简。两者对比图如下:
其它优化策略
Anchor-free
Anchor-free也是借鉴YOLOX,即取消从YOLOv2一直以来的锚框(Anchor)机制,直接返回出目标的位置信息,代价是不太稳定,好处是计算能够更快。
SimOTA
SimOTA是一种正负样本匹配策略,也是YOLOX提出的策略方法,在我之前的博文【目标检测】从YOLOv1到YOLOX(理论梳理)也提到过。
简单来说,正负样本判断需要解决的问题就是当预测出来的框太多时如何去除低质量框的问题,保留高质量的框(正样本)去参与运算。
SimOTA定义的计算公式如下:
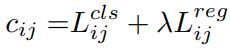
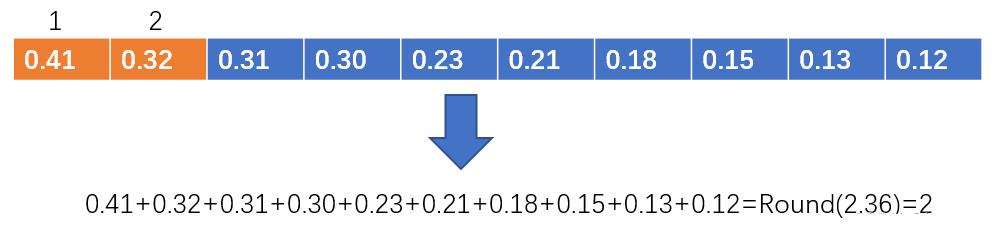
对于每一个预测框,分别计算其与真实框的IOU和类别损失,然后加权得到总体损失。然后将各个框和真实框的iou排序,将所有框的iou相加取整,得到正样本的类别个数。
比如,下图中[2],取整后的结果为2,那就选取前两个作为正样本。
SIoU
之前的边界框回归损失包括IoU、GIoU、CIoU、DIoU。YOLOv6 引入的 SIoU 损失函数通过引入了所需回归之间的向量角度,重新定义了距离损失。
相关论文可参考:https://arxiv.org/abs/2205.12740
从理论上看,YOLOv6并没有太多新东西,下面就进入实践环节,看看使用效果怎么样。
实践使用
总体看YOLOv6和YOLOv5的代码大致类似,不过很多小地方做了修改。
比如模型的训练、测试、检测函数被藏在了tools的文件夹下,这导致后面输入文件路径都很别扭,比如在inferer.py里面,路径的少了个跳出的步骤,需要手动修改一下。
数据集改造
对于数据集的输入,YOLOv6也做了改造,以至于在【目标检测】YOLOv5跑通VisDrone数据集文中的VisDrone数据集不能直接拿来用,需要做下面这番改造。
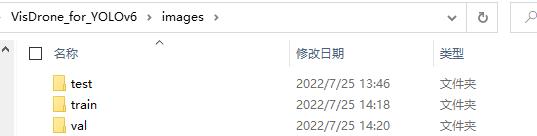
图片数据和标签需要单独建个大的文件夹,下面分别建三个小文件夹,并且名称固定为train,test,val。
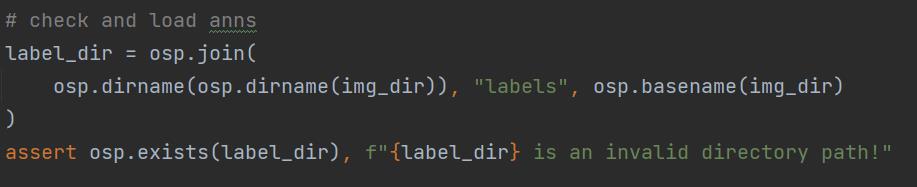
具体的原因可以看下面这几行加载数据的代码。
我处理好的VisDrone数据集也整理在这,读者可直接下载:
https://pan.baidu.com/s/1u0OZ05r48Yi6Wwi7TcqI_g?pwd=8888
注:VisDrone里面默认是只有xml格式的标签,txt标签是我通过脚本生成的,具体的方式见我上一篇博文【目标检测】YOLOv5跑通VisDrone数据集
这个处理完之后,和YOLOv5一样,需要在data文件夹下新建mydata.yaml
输入下面内容:
train: D:/Dataset/VisDrone_for_YOLOv6/images/train # train images
val: D:/Dataset/VisDrone_for_YOLOv6/images/val # val images
test: D:/Dataset/VisDrone_for_YOLOv6/images/test # test images
is_coco: False
nc: 10 # number of classes
names: [ 'pedestrian', 'people', 'bicycle', 'car', 'van', 'truck', 'tricycle', 'awning-tricycle', 'bus', 'motor' ]
这里的路径改成自己的。
效果测试
YOLOv6总共有yolov6s,yolov6n和yolov6t三种模型。我使用yolov6s在VisDrone数据集上训练了100个epoch,共耗时13个小时(RTX 2060显卡),训练速度比起YOLOv5而言,提升了不少。
测试下来,其IoU=0.50 AP为32.5%,IoU=0.50:0.95 AP为17.4%,这数据还不如前面的YOLOv5两个版本(之前的数据在我上篇博文内【目标检测】TPH-YOLOv5:基于transformer的改进yolov5的无人机目标检测)
下面来测试下视频。
结果报错:
Switch model to deploy modality.
查阅官方的issue,原来目前推理只支持图片,暂不支持视频。。
于是输入VisDrone测试集上的图片进行检测,效果如下:


第一幅图检测效果还不错,大部分目标都识别出来。
第二幅图结果却令人意外,仅检测出三个目标,其它的自行车目标全部漏检!

我的感受
YOLOv6主打的是模型的部署。在项目文件中,它支持导出ONNX、TensorRT等格式的文件,在官方出具的实验对比上看,实验环境基本上是在nano那种嵌入式设备。可能YOLOv6在真实的生产环境中更有优势,但在纯粹的算法效果上,优势并不明显。并且,好多内容都是借鉴YOLOX,被戏称为“YOLOX PLUS"也不为过。
目前YOLOv4的作者团队又推出YOLOv7,YOLOv6则沦为过渡之作,而它总体看来推出得也略显仓促,显然还没完善好就推出来占坑。不过,作为国人推出的研究成果,依然期待其后续的发展完善。
代码备份
注意,本篇博文观点仅仅是我在使用yolov6s.pt训练了100个epoch得出的结论,具体的性能有待后续测试。这里顺便进行代码备份(包含3个模型的预训练权重):
https://pan.baidu.com/s/1GIOZq3EgzzVDjs3zZP_dKQ?pwd=8888
Reference
【1】https://blog.csdn.net/MeituanTech/article/details/125437630
【2】https://blog.csdn.net/lzzzzzzm/article/details/123133069
以上是关于目标检测YOLOv6理论解读+实践测试VisDrone数据集的主要内容,如果未能解决你的问题,请参考以下文章