目标检测YOLOR理论简介+实践测试VisDrone数据集
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测YOLOR理论简介+实践测试VisDrone数据集相关的知识,希望对你有一定的参考价值。
前言
YOLOR是2021年提出的一种算法,其一作Chien-Yao Wang(台湾)同时也是最近刚出的YOLOv7的第一作者。
论文地址:https://arxiv.org/abs/2105.04206
论文项目地址:https:// github.com/WongKinYiu/yolor
理论简介
YOLOR的论文不容易啃,因为其在里面写了大篇幅的数学推导概念,我不做深入推导研究,仅对其思想进行简单复述。
YOLOR的核心思想也是借鉴了人脑生理学结构。人类可以通过正常的感官和经验来进行主动学习,这部分学习到的知识被称为显性知识,与此同时,人类也可以通过潜意识来进行学习,这部分学习到的知识被成为隐性知识。
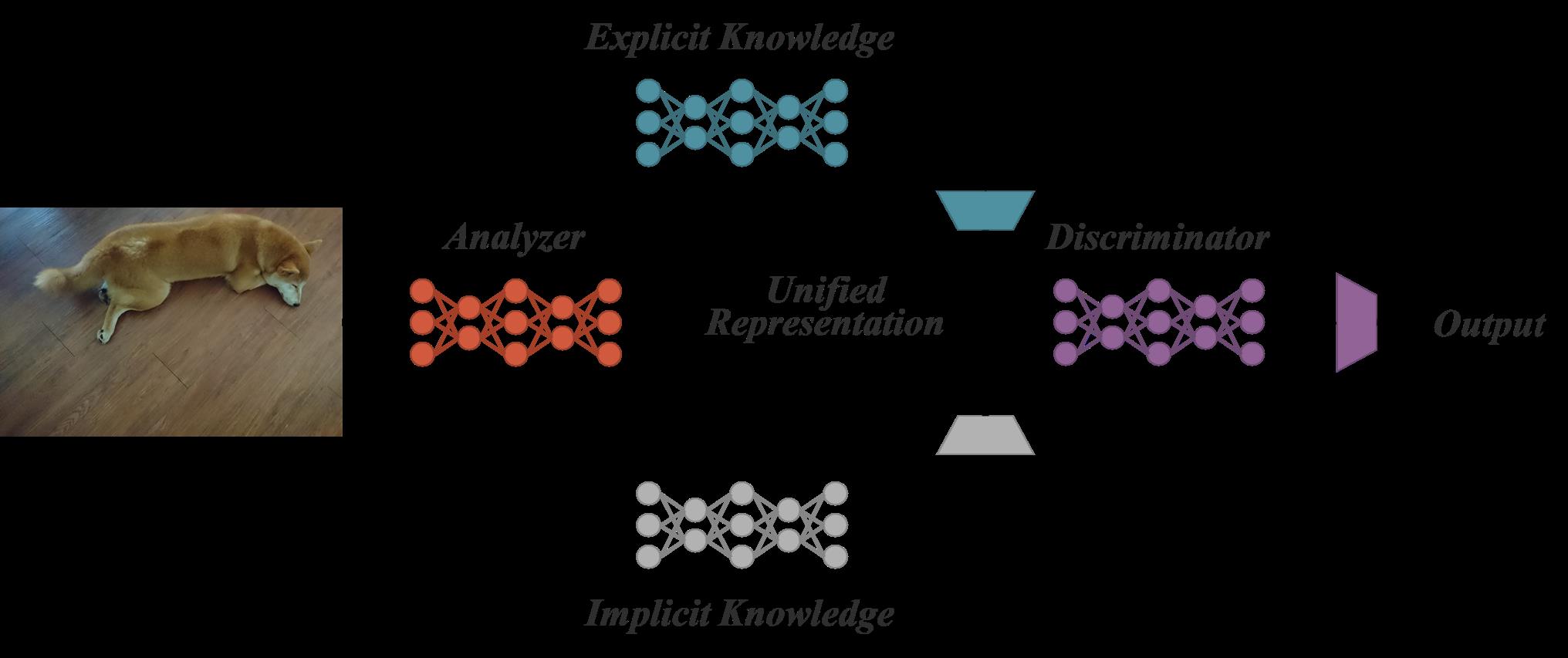
在传统的神经网络模型中,往往提取了神经元特征而丢弃了隐式知识的学习运用,作者将直接可观察的知识定义为显式知识,隐藏在神经网络中且无法观察的知识定义为隐式知识。
因此,作者就针对这一点做了下列一些研究贡献:
- 提出了一个可以完成各种任务的统一网络,它通过整合内隐知识和外显知识来学习一般表示,人们可以通过这种一般表示来完成各种任务。所提出的网络以非常小的额外成本(不到1万的参数量和计算量)有效地提高了模型的性能。
- 将核空间对齐、预测精细化和多任务学习引入内隐知识学习过程,并验证了它们的有效性。
- 分别讨论了利用向量、神经网络和矩阵分解等工具对隐性知识进行建模的方法,并验证了其有效性。
- 证实了所提出的内隐表示可以准确地对应特定的物理特征,并且我们也将其以视觉的方式呈现出来。
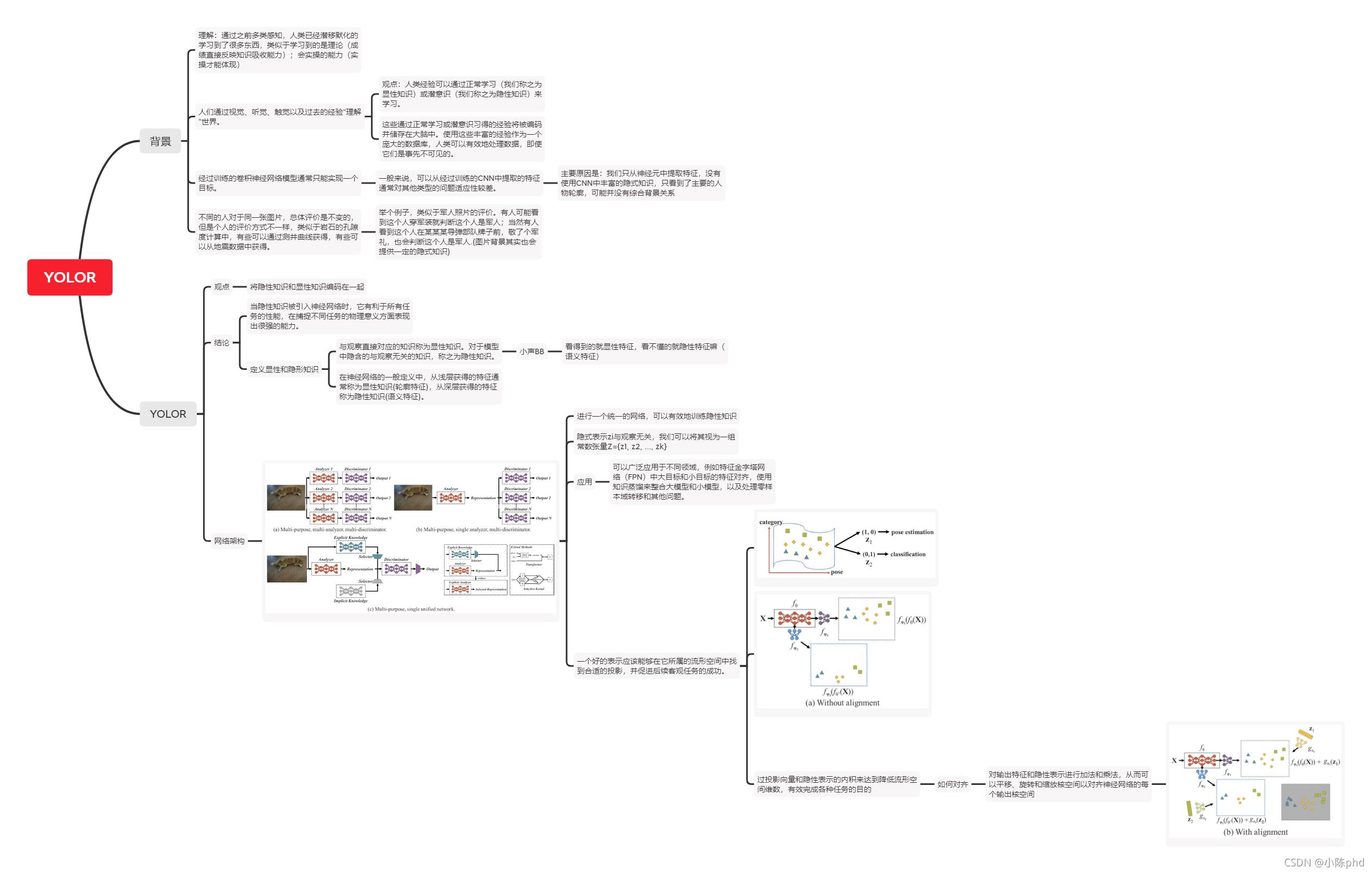
下面具体的内容太复杂且枯燥了,深入了解的可以看原论文或博文[1]总结的思维导图:
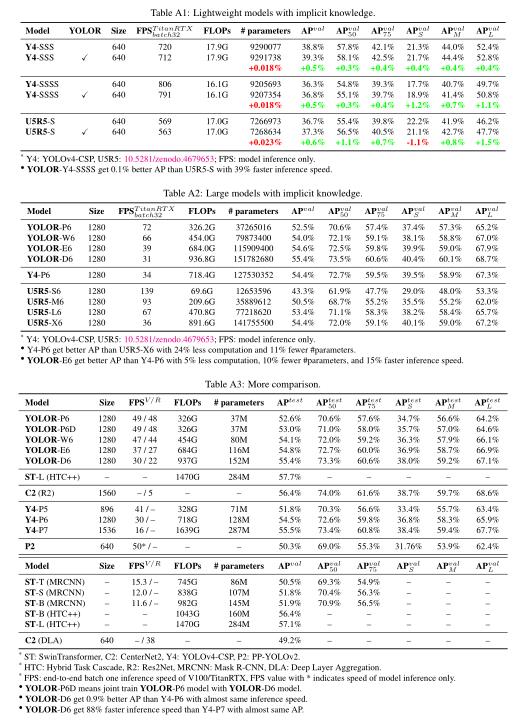
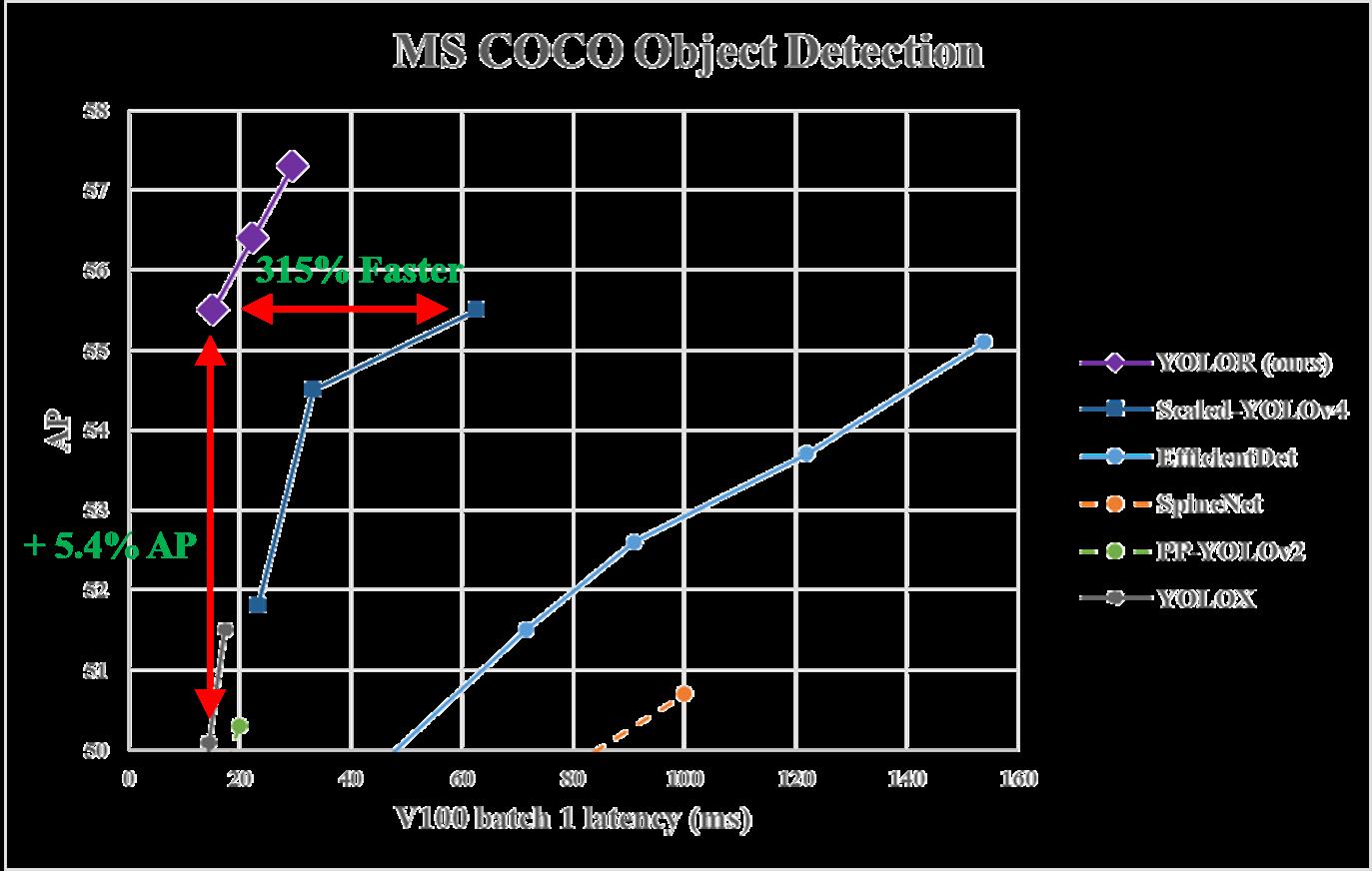
下面是论文里展现的作者使用不同模型的实验结果:
实践测试
东西好不好,还得看实际用了才知道。
看到源码基本上也是基于YOLOv5改的,因此看过我之前这篇博文【目标检测】YOLOv5跑通VisDrone数据集的读者应该对跑通YOLOR也轻车熟路。
下面我就使用VisDrone数据集和yolor_csp_x_star这个模型跑100个epoch,再进行测试,下面是测试结果,同样和之前【目标检测】TPH-YOLOv5:基于transformer的改进yolov5的无人机目标检测做个实验的模型进行对比,结果如下:
| 算法 | mAP@.5 | mAP@.5:.95s |
|---|---|---|
| yolov5-5.0 | 34.9% | 20.6% |
| yolov5-6.1 | 33.1% | 18.7% |
| tph-yolov5 | 37.4% | 21.7% |
| yolov6 | 32.5% | 17.4% |
| yolor | 37.7% | 22.8% |
注:只是100个epoch的得到的best.pt的测试结果,并未达到最优性能,通常论文里展示的测试结果都是300个epoch以上。
仅看mAP数值的话,YOLOR的数值在迭代100轮的情况下,数值最高,说明YOLOR的确是有所提升效果的。
下面我导入之前测试过的小目标人体检测视频,可以看到YOLOR的检测效果并没有像数值预期的那样理想,说明对于小目标情况,YOLOR并不非常适用(这是未经足够实验得出的结论,仅供参考)。
YOLOR_VisDrone数据集检测效果
代码备份
跑YOLOR的代码可以明显发现作者的目光并不局限于AP,有时候,AR在一些具体任务中,比AP更重要。作者对这点进行了优化,训练完之后,不像原版只保存best.pt和last.pt,而是保存多个模型。
可能是由于作者的一些失误,原始代码在运行时有一些小bug。我进行了简单修正,特将代码备份如下(包含yolor_csp_x_star.pt权重文件和我运行的一些结果):
https://pan.baidu.com/s/1lXiu82q0sQPTCU0C4UmcAQ?pwd=8888
References
[1]https://blog.csdn.net/weixin_42917352/article/details/120050525
以上是关于目标检测YOLOR理论简介+实践测试VisDrone数据集的主要内容,如果未能解决你的问题,请参考以下文章
目标检测YOLOv6理论解读+实践测试VisDrone数据集
目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试
目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试