目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试相关的知识,希望对你有一定的参考价值。
前言
之前在看Swin Transformer的时候,发现该算法在目标检测、实例分割等各种视觉任务上屠榜,于是想来实践测试一下。
官方地址:https://github.com/SwinTransformer/Swin-Transformer-Object-Detection
查看源码,发现Swin Transformer并不是作为一套单独的算法进行使用,而是嵌入在mask_rcnn算法中,作为该算法的backbone。(当然,也可以使用别的算法,只是该仓库目前仅实现了mask_rcnn和cascade_mask_rcnn)
因此,有必要先对Mask R-CNN算法做一个了解。
Mask R-CNN简介
Mask R-CNN是何凯明大神继Faster-RCNN后的又一力作,在Fasker R-CNN的基础上,集成了物体检测和实例分割两大功能。
论文链接:https://arxiv.org/pdf/1703.06870.pdf
中文翻译:https://blog.csdn.net/weixin_43066351/article/details/106613654
这里顺便补充一个知识点:实例分割和语义分割的区别

如图所示,中间那幅图是语义分割,只需要把不同的类别和背景分割出来即可,右侧图是实例分割,不仅需要把类别分割出来,还需要把每个个体分割出来,因此,实例分割的难度比语义分割更高。
整体结构
Mask R-CNN添加一个分支来预测每个关注区域(RoI)上的分割蒙版,从而扩展了Faster R-CNN,与现有的用于分类和边界框回归的分支并行,整体结构如下图所示:

RoIAlign替代RoIPool
Mask R-CNN和Fast R-CNN一样,均属于两阶段的目标检测,第一阶段是从原图中提取感兴趣区域(Rol)。
在Fast RCNN中,采用了RoIPool,能够通过卷积和池化将原图映射成固定尺寸的特征图,不过在处理过程中,进行了两次量化,造成了精度损失。
因此在Mask R-CNN中,使用了RoIAlign来替代RoIPool,核心思想是通过双线性插值法来避免两次量化产生的误差。
下表展示了替代之后的效果,左边这栏是实例分割的mAP,右边这栏(bb)是目标检测的mAP,可以看到替代之后对于结果的提升还是非常显著的。

这部分具体细节可以参考这两篇文章:
检测头结构
第二阶段是从Rol处理之后的特征图进行检测/分割,作者在这部分讨论了两种不同的检测头结构,如下图所示:
下图左边是不带FPN结构的Mask分支,右侧是带有FPN结构的Mask分支(灰色部分为原Faster R-CNN预测box, class信息的分支,白色部分为Mask分支)

对此,作者对不同的网络结构进行了实验比较,结果如下图所示:
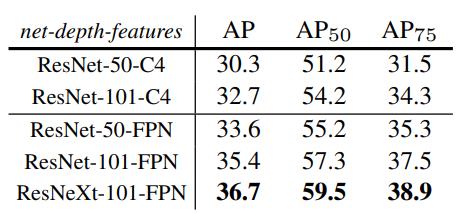
可以看到ResNeXt-101-FPN这个结构起到最好的效果。
结果展示
最后作者展示了在不同算法在COCO数据集上的比较结果:

进一步拓展:可以将目标检测部分替换成人体关键点检测,结果如下图所示:

优化过程解读
最后,作者在附录中记录了对于COCO数据集的调参以及优化过程,感觉对于后续的竞赛会有帮助,研究一下:

-
Updated baseline
这一步就是对一些超参数进行修改,包括延长迭代次数到18万轮;从12万轮到16万轮学习率降低10点;将NMS阈值从0.3调整到0.5
这一步mask AP提升0.3,box AP提升0.9 -
End-to-end training
之前的训练策略是先单独对一阶段的RPN网络进行训练,之后再对二阶段的Mask R-CNN检测头进行训练,这一步端到端的优化就是将两者结合起来一起训练
这一步mask AP提升0.6,box AP提升1.2 -
ImageNet-5k pre-training
这一步很简单,就是扩充数据集,引入ImageNet-5k数据集进行预训练
这一步mask AP提升1.0,box AP提升1.0 -
Train-time augmentation
这一步就是在训练的时候,对原始数据进行数据增强,这里作者采用的数据增强策略是随机在[640, 800]像素范围内进行缩放,并且将迭代次数增加到26万轮
这一步mask AP提升0.6,box AP提升0.8 -
Deeper
deeper就是将使用更深的网络结构,这里作者101-ResNeXt升级为152-ResNeXt
这一步mask AP提升0.5,box AP提升0.6 -
Non-local
Non-local类似残差结构一样,可以在不改变原有网络结构的基础上,作为一种通用的结构插入,具体我没仔细了解,详细内容可以参考这篇论文笔记【论文笔记】Non-local Neural Networks
这一步mask AP提升0.6,box AP提升0.9 -
Test-time augmentation
这一步就是在测试时对测试数据也进行数据增强,具体的策略包括每间隔100张图片,对数据随机在[400, 1200]像素范围内进行缩放,并进行水平翻转
这一步mask AP提升1.5,box AP提升2.3
总结:从上面的实验过程不难看出,扩充数据集/对数据增强提升效果比修改网络结构提升得更为明显,这和我以往的实验经验一致。同时,对测试集进行增强检测,提升的效果最多,个人猜测是因为对测试集进行数据增强之后,测试集更贴近训练集(训练集也进行了数据增强),因此目标更容易被检测。
实践测试
下面又到了快乐的实践环节。
官方的代码实际是用mmdection框架进行实现的,而且用的版本比较老,在mmdet/__init__.py文件中,指明了mmcv的版本范围为1.2.4-1.4.0,而在mmdection最新仓库中,mmcv的最高版本已支持1.7.0。
将其版本手动扩大,尝试运行,结果报错:
TypeError: MaskRCNN: SwinTransformer: init() got an unexpected keyword argument ‘ape’
查询到官方的issues#92,发现也有人遇到了同样的问题,采用python setup.py develop等方式,并无法解决该问题,遂放弃,使用最新版本的mmdection进行实践。
mmdection地址:https://github.com/open-mmlab/mmdetection
mmdection的简介和安装可以参考我之前的博文【目标检测】MMDetection的安装与基础使用,mmcv和mmdection的版本配套比较麻烦,建议使用python3.7版本。
安装配置好之后,在configs/swin下可以看到官方实现的几个mask_rcnn算法,这里采用mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py

之后建立一个checkpoint文件夹,下载mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth和swin_small_patch4_window7_224.pth两个模型权重,下载方式见官方的ModelZoo。

检测图片
在源码的demo文件夹中,有检测图片的程序,这里为了运行方便,在根目录下新建一个infer.py
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
import warnings
warnings.filterwarnings("ignore")
config_file = 'configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py'
checkpoint_file = 'checkpoint/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth'
device = 'cuda:0'
# 初始化检测器
model = init_detector(config_file, checkpoint_file, device=device)
# 推理演示图像
img = 'demo/demo.jpg'
result = inference_detector(model, img)
show_result_pyplot(model, img, result, score_thr=0.3, out_file='1.jpg')
这里的out_file指定输出的图片名,检测效果如下图所示:

检测视频
检测视频和检测图片类似,在demo中有对应的代码,这里同样在根目录下新建一个infer_video.py
import argparse
import os
import cv2 as cv
import torch
from mmdet.apis import inference_detector, init_detector
import warnings
import time
warnings.filterwarnings("ignore")
file_path = __file__
dir_path = os.path.dirname(file_path)
output_video_path = os.path.join(dir_path, 'result.mp4')
def parse_args():
parser = argparse.ArgumentParser(description='MMDetection webcam demo')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument(
'--device', type=str, default='cuda:0', help='CPU/CUDA device option')
parser.add_argument(
'--camera-id', type=int, default=0, help='camera device id')
parser.add_argument(
'--score-thr', type=float, default=0.5, help='bbox score threshold')
parser.add_argument(
'--file', type=str, help='where the test video path')
parser.add_argument(
'--out', type=str, default=output_video_path, help='the out put video path')
args = parser.parse_args()
return args
def main():
args = parse_args()
if not args.file:
print('No target file!')
exit(0)
device = torch.device(args.device)
print('device:', args.device)
model = init_detector(args.config, args.checkpoint, device=device)
camera = cv.VideoCapture(args.file)
camera_width = int(camera.get(cv.CAP_PROP_FRAME_WIDTH))
camera_hight = int(camera.get(cv.CAP_PROP_FRAME_HEIGHT))
# print(camera_hight, camera_width)
fps = camera.get(cv.CAP_PROP_FPS)
video_writer = cv.VideoWriter(args.out, cv.VideoWriter_fourcc(*'mp4v'),
fps, (camera_width, camera_hight))
count = 0
tt = 0
while True:
torch.cuda.empty_cache()
ret_val, img = camera.read()
if ret_val:
if count < 0:
count += 1
print("Write in result Successfuly!".format(count))
continue
result = inference_detector(model, img)
frame = model.show_result(img, result, score_thr=args.score_thr, wait_time=1, show=False)
# cv.imshow('frame', frame)
if len(frame) >= 1:
# 添加帧率检测
# cv.putText(frame, "FPS::.1f".format(1. / (time.time() - tt)), (20, 50), cv.FONT_HERSHEY_SIMPLEX, 2,
# (235, 0, 0), 4)
# tt = time.time()
video_writer.write(frame)
count += 1
print("Write in result Successfuly!".format(count))
else:
# print('Load fail!')
break
camera.release()
video_writer.release()
# cv.destroyWindow()
if __name__ == '__main__':
main()
终端输入:
python infer_video.py configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py ch
eckpoint/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth --file demo/demo.mp4
等待片刻,即可在根目录下生成视频结果'result.mp4'
这里我使用ResNet-50,ResNet-101,Swin-S,Swin-T四种不同的backbone,对比效果如下:
Mask R-CNN遇上ikun
实测发现,对于这段30帧的视频,Mask R-CNN的帧率基本不超过3fps(RTX 2060单显卡推理),作为二阶段的算法,推理速度还是比较慢的。
视频中,有几帧会把kun的白带识别为手提包,因为是直接采用coco数据集上训练的模型进行检测,该特征和包的提手很像。
模型测试
官方下载的模型是在coco数据集进行训练的,因此使用coco数据集可以直接进行模型测试。
首先需要下载coco数据集:https://pan.baidu.com/s/1D_J3qGfQZWhaTxMvW5LzBA?pwd=8888
下载好之后,位置结构如图所示:

然后在configs/_base_/datasets/coco_instance.py中,修改数据集的路径:

修改好之后,运行tools/test.py即可进行模型测试:
终端输入:
python tools/test.py configs/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco.py checkpoint/mask_rcnn_swin-t-p4-w7_fpn_1x_coco_20210902_120937-9d6b7cfa.pth --eval bbox segm
结果输出:
注:bbox是目标检测的相关指标,segm是实例分割的相关指标
Evaluating bbox...
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.427
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.652
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.468
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.265
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.459
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.566
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.559
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.559
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.559
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.383
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.596
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.703
Evaluating segm...
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.393
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.622
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.422
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.205
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.418
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.578
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.519
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.519
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.519
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.345
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.555
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.675
OrderedDict([('bbox_mAP', 0.427), ('bbox_mAP_50', 0.652), ('bbox_mAP_75', 0.468), ('bbox_mAP_s', 0.265), ('bbox_mAP_m', 0.459), ('bb
ox_mAP_l', 0.566), ('bbox_mAP_copypaste', '0.427 0.652 0.468 0.265 0.459 0.566'), ('segm_mAP', 0.393), ('segm_mAP_50', 0.622), ('seg
m_mAP_75', 0.422), ('segm_mAP_s', 0.205), ('segm_mAP_m', 0.418), ('segm_mAP_l', 0.578), ('segm_mAP_copypaste', '0.393 0.622 0.422 0.
205 0.418 0.578')])
模型训练
下面同样尝试利用coco数据集进行训练,数据集路径在上一节已经修改完毕,这一节主要需要修改训练参数。
我使用的是单卡GPU,显存较小,因此将configs/_base_/default_runtime.py中的base_batch_size改成1

然后修改configs/_base_/datasets/coco_instance.py文件中的samples_per_gpu和workers_per_gpu,同样修改为1
最后运行tools/train.py即可开始训练:
终端输入:
python tools/train.py configs/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco.py
训练时会显示预估剩余时间,单卡2060在coco数据集上实测训练mask_rcnn_swin-t模型一轮需要花费近一天时间,这个模型参数量着实恐怖。
代码备份
包含完整代码/下载的权重:
https://pan.baidu.com/s/19zpIljdlkJG-BJD7w2NzCA?pwd=8888
以上是关于目标检测/实例分割Mask R-CNN简介与Swin Transformer实践测试的主要内容,如果未能解决你的问题,请参考以下文章