国外AI工程师讲述:深度学习与目标检测,理论和实践果然两码事
Posted TSINGSEE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了国外AI工程师讲述:深度学习与目标检测,理论和实践果然两码事相关的知识,希望对你有一定的参考价值。
背景故事
2018 年,当时我在工厂实习,我开始研究目标检测技术,因为我需要解决视觉检测问题。 这个问题需要在来自工业相机的图像流中检测许多不同的物体目标。
为了应对这一挑战,我首先尝试将分类与滑窗法结合使用。 自然,该系统非常缓慢且不适合生产。
在此之后,我开始研究执行目标检测的端到端深度学习模型。偶然间,我发现了一篇来自Gooogle研究的著名论文,题为:Speed/accuracy trade-offs for modern convolutional object detectors.
这篇论文对我产生了很大的影响,也是我对使用深度学习的对目标检测领域所需要的经验介绍。
目标检测是一项古老的任务,深度学习给它带来了什么?
现在,目标检测是计算机视觉领域中相对古老的任务。在深度学习成为主流之前,许多研究人员和工程师都在研究这个问题。 他们主要使用经典的图像处理技术,可能经常使用滑窗法。 那么深度学习对目标检测的附加价值是什么?
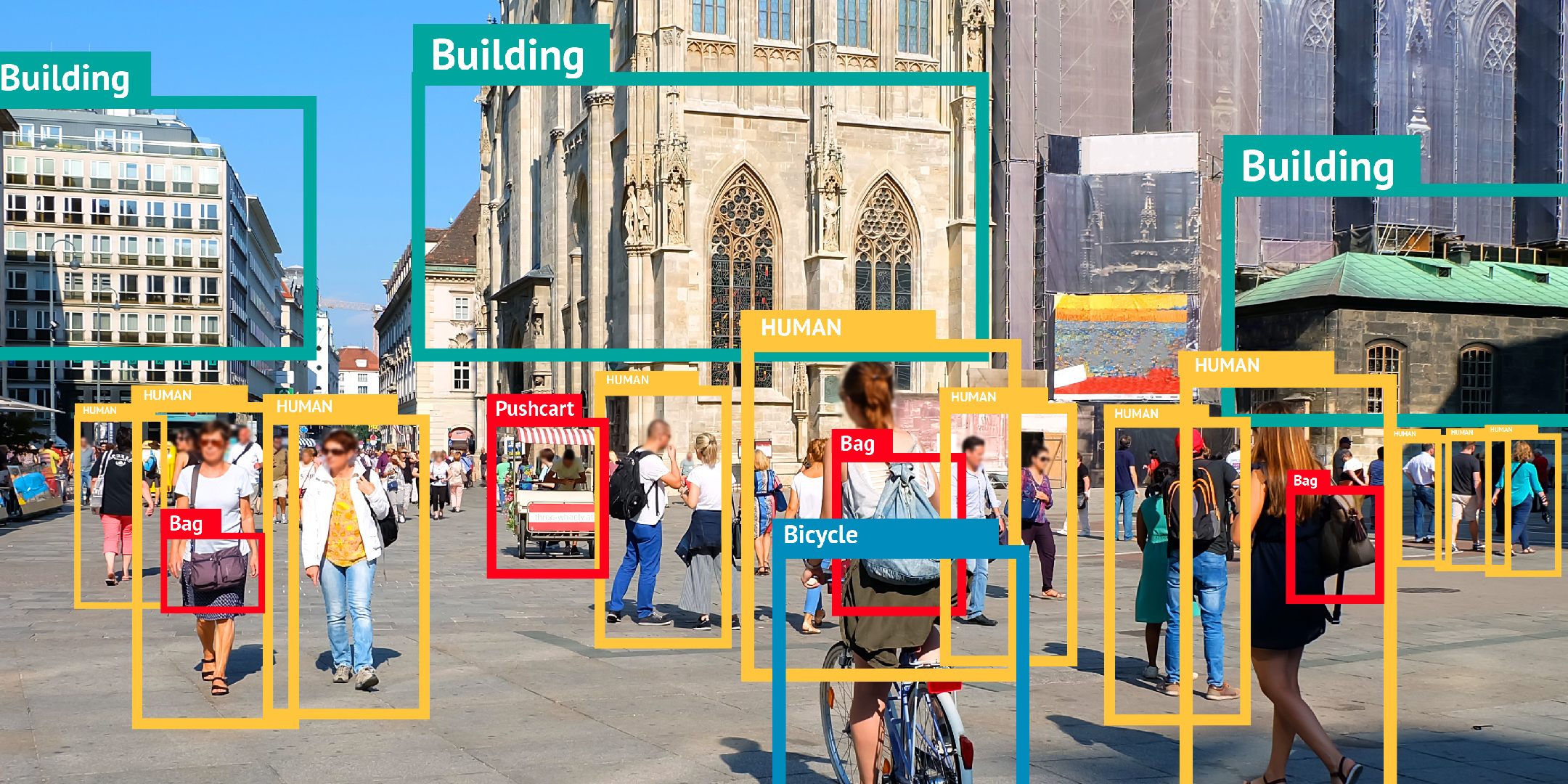
实际上,深度学习从根本上改变了我们处理目标检测的方式。随着 YOLO 和 R-CNN 系列的引入,目标检测的性能显著提高。大多数用于图像相关任务的神经网络使用卷积层。这些神经网络称为 CNN(卷积神经网络)。 这些 CNN 实际上自然而有效地执行了一种滑窗法。 这是神经网络如何学习图像表征的一部分。
目标检测技术的研究现状
在我写这篇文章的时候,谈论最多的目标检测模型是 YOLOR(You Only Learn One Representation)。设计该模型架构的研究人员正在寻找整合“隐性知识”的方法。这种隐性知识应该代表神经网络中的潜意识。作者想要构建一个架构,模仿我们人类在现实生活中解决目标检测任务的方式。这种架构可能是未来工作的基础,它集成了这种隐式知识的概念,不仅用于目标检测,还用于各种计算机视觉任务。

还有另一种架构可以成为许多未来工作的基础,那就是 DETR 架构。 DETR 代表检测变压器。
Transformer 是一种新型的神经层,它们正在与卷积层竞争多种计算机视觉任务。
Transformers 已经在 NLP(自然语言处理)任务中取得了不错的成绩,并且正在稳步进入计算机视觉任务。
目标检测技术的行业现状
在过去的几年里,我一直担任机器学习工程师,专注于计算机视觉应用。通过在该领域工作以及对需要机器学习和计算机视觉知识的职位进行多次面试,我实际上注意到了行业中目标检测的一些趋势。

如果你在该行业工作,那么肯定知道,对于同一任务,一项任务最重要的指标可能与研究中使用的指标大不相同!
在目标检测任务的情况下,同样适用。据我所知,在工业设置中实施目标检测模型时,有 2 个指标是最重要的:速度和稳健性。并非总是两者兼而有之,但总是至少存在两者之一。
由于这些原因,YOLO(v3,v4,v5)和Faster-RCNN在业界得到了广泛的应用。通常,当速度是第一要务时,则使用 YOLO,当鲁棒性是第一要务时,则使用 Faster-RCNN。
我个人均使用过 YOLOv3、SSD 和 Faster-RCNN。
尽管许多在该行业工作的人直接使用 YOLO——我猜是因为它比较有名——但我不认为它是一种万能的解决方案。
在推理速度方面,YOLO 和 SSD 都显示出巨大的潜力。但在某些情况下,它们可能仍然会失败,尤其是在行业实践中。
我记得有一次尝试使用带有 InceptionV2 后端的 SSD 来执行困难的目标检测任务。这是一项目视检查任务,我们需要检测大型发动机(飞机或直升机,我不记得了)内部的机械部件。无论我如何调整我的神经网络的参数,我都无法减少损失,它一直在振荡。
我之前使用过相同的架构,使用相同的主干,来执行其他一些目标检测任务,效果很好。因此,当我完成这项绝对更具挑战性的任务时,SSD 失败了。因为引擎看起来非常庞大,而且因为有这么多零件连接在一起,而且其中许多零件看起来非常相似。即使是人眼,也很难发现我们想要检测的特定机械部件!由此可见,注释我们的数据集有多困难。

此时,我记得我认为这只是深度学习的极限。但在完全放弃之前,我决定尝试不同的架构,并尽量避免使用 YOLO 和 SSD 等单级检测器。
我选择了 Faster-RCNN,因为它是一个两阶段的对象检测模型。结果,这个模型效果非常好!损失函数的收敛比保龄球还平滑。因此切记:下次在处理目标检测任务时,请在下定决心之前尝试几种不同的架构!
需要云计算以提高目标检测任务的性能
在训练深度学习模型,尤其是大型模型时,需要一些非常好的设备。在训练方面,GPU 可能是深度学习机器最重要的方面。很多公司购买这些设备,但也有不少公司选择云计算服务。
Google Cloud Platform (GCP)、Amazon Web Services (AWS) 和 Microsoft Azure 是一些广泛使用的云计算服务。
对于目标检测和大型模型(如 Faster-RCNN),这些云计算解决方案可能正是你正在寻找的训练模型的方法。但是应该怎么选择呢?
对于许多公司来说,他们已经在上述云提供商之一上建立了云基础设施,因此他们可能只想继续使用同一提供商来保持标准化。

当然,还有多种方法可以训练你的目标检测模型,稍后我将详细介绍一些开源工具。但是,如果你正在使用 Tensorflow(1 或 2),那么你使用的是 Tensorflow 目标检测 API。那么我建议你 Google Cloud 是比较好的选择。
由于 Tensorflow 是Google 的产品,而且目标检测 API 也属于Google ,Google Cloud团队让在 GCP 上训练模型变得非常容易。
具体来说,用于训练目标检测模型,有两个:AI Platform 和 Vertex AI。
用于执行目标检测任务的深度学习开源工具
使用深度学习进行目标检测,主要有三种广泛使用的工具:
- Tensorflow Object Detection API
- Detectron2
- MMDetection
如果是 Tensorflow 开发人员,那么 Tensorflow 目标检测 API 最适合你。 如果是 PyTorch 开发人员,那么 Detectron2 和 MMDetection 更适合你。
如果开发者更关心选择的多样性,那么 MMDetection 是最佳选择,因为它拥有大量目标检测深度学习模型。
总结
总而言之,以下是本文的要点:
- 目标检测在计算机视觉中是一项相对较旧的任务,但深度学习已经大幅提升了目标检测任务的性能。
- 当涉及到用于目标检测的深度学习时,研究中推动的指标可能不一定与行业中推动的指标相同。
- 云计算可以成为深度学习模型训练性能的主要助推器,请明智地选择云服务提供商。
- 使用深度学习进行目标检测有多种开源工具,主要的三个是:Tensorflow Object Detection API、Detectron2 和 MMDetection。
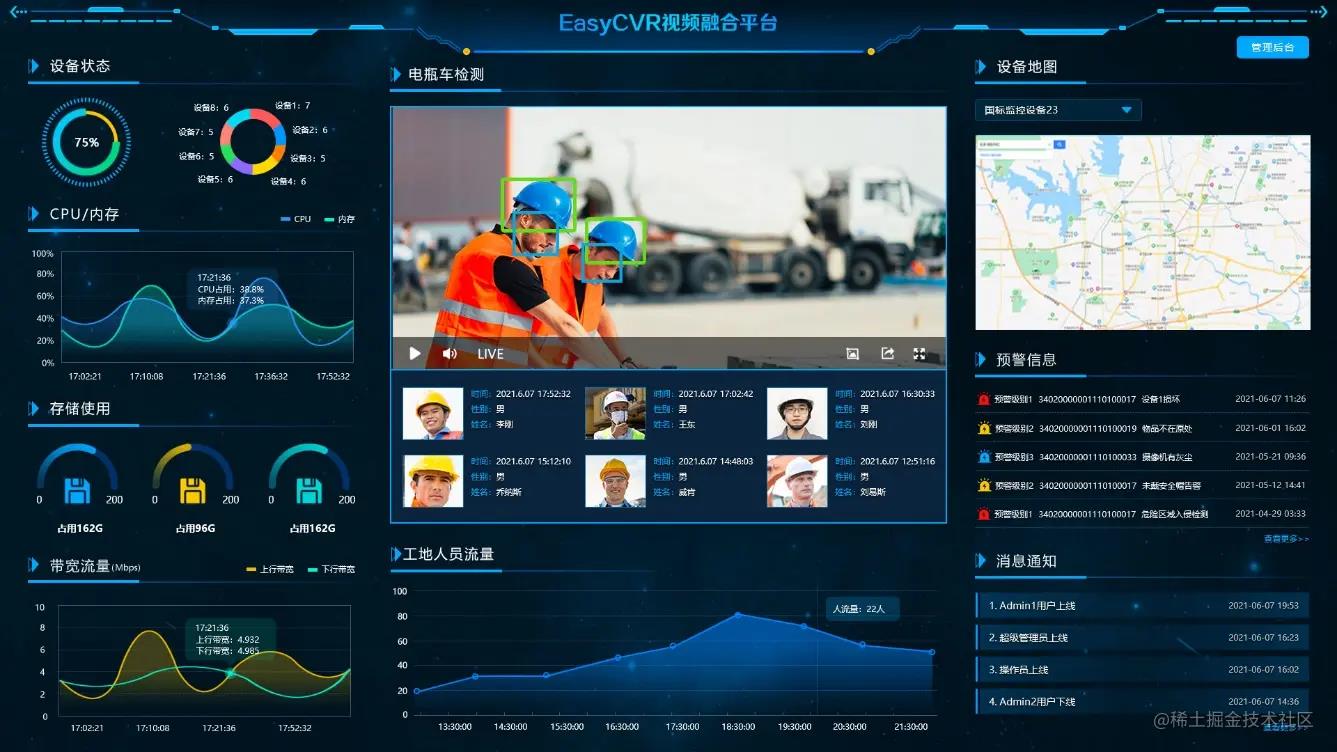
目标检测技术的安防场景示例:
TSINGSEE青犀视频基于多年视频领域的技术经验积累,在人工智能技术+视频领域,也不断研发,将AI检测、智能识别技术融合到各个视频应用场景中,如:安防监控、视频中的人脸检测、人流量统计、危险行为(攀高、摔倒、推搡等)检测识别等。典型的示例如EasyCVR视频融合云服务,具有AI人脸识别、车牌识别、语音对讲、云台控制、声光告警、监控视频分析与数据汇总的能力。
以上是关于国外AI工程师讲述:深度学习与目标检测,理论和实践果然两码事的主要内容,如果未能解决你的问题,请参考以下文章
逐梦AI深度学习与计算机视觉应用实战课程(BAT工程师主讲,无人汽车,机器人,神经网络)
深度学习与图神经网络核心技术实践应用高级研修班-Day4基于深度学习的目标检测(object_detection)