opencv-python学习笔记:目标检测理论体系与实践说明
Posted submarineas
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了opencv-python学习笔记:目标检测理论体系与实践说明相关的知识,希望对你有一定的参考价值。
引言
本次是接着python-opencv学习笔记(七):滑动窗口与图像金字塔 一起在实验楼所做实验,为啥中间隔了四篇才接着发出来,主因是我发文比较随意(懒),当时这部分并没有总结完,至少我感觉我看的相关资料还不够多,整体理解不深,另外就是项目需求,在做很多其它的东西,图像能见度就是当时一个指标,搞了几天,最后看起来效果一般,目前没有上线只是自己测试反馈不多,所以就接着做其它适配任务去了,现在这篇是算结束吧,赶紧总结完,复习去了。
实验流程
- 使用图像金字塔将图片按一定缩放比例生成不同尺寸图片(下图序号 1 所示)。
- 使用滑动窗口在每张不同尺寸的图片上从左至右、从上向下滑动(下图序号 2 所示)。
- 将滑动窗口滑过的每个区域使用方向梯度直方图进行特征描述,获得 HOG 特征(下图序号 3 所示)。
- 将获取到的 HOG 特征使用机器学习分类器(支持向量机)进行分类(下图序号 4 所示)。
- 最后在图片中使用矩形框标记出被分类器认为是人的类别(下图序号 5 所示)。
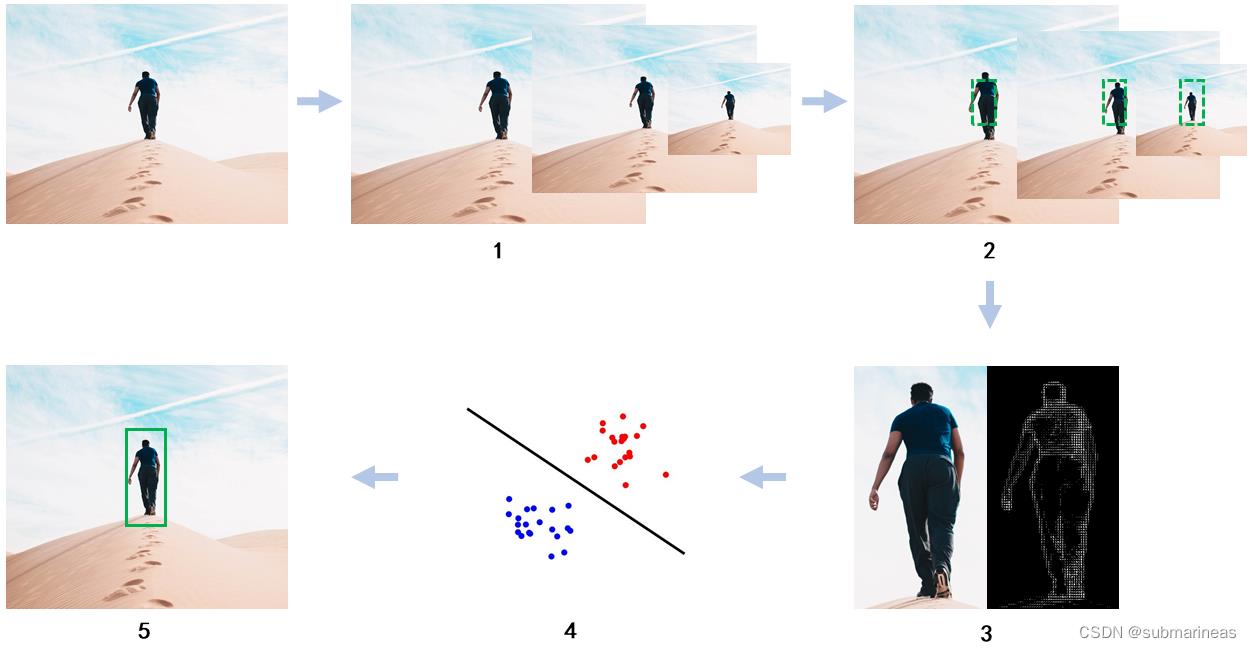
关于图像金字塔与窗口滑动,已经在第七篇中提到,本篇总结的是后面三步。
HOG 方向梯度直方图
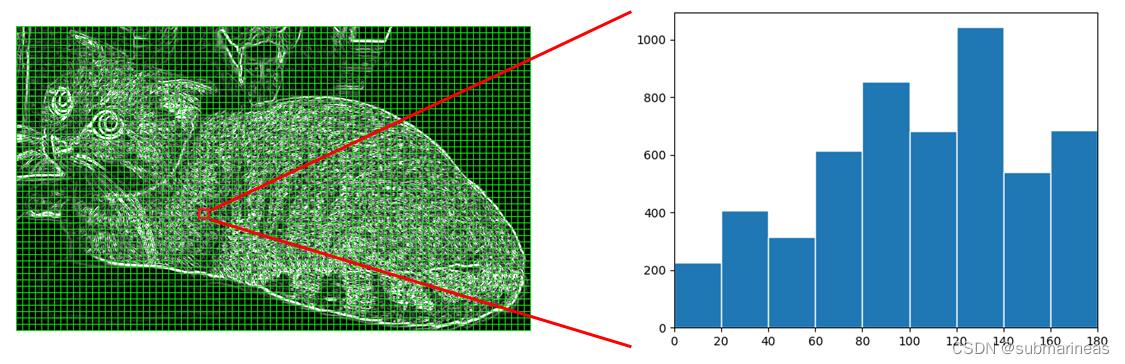
下图中左边的图片是一只猫,我们不仅可以看出猫身体上的特征、颜色、纹理,而且还能看到背景。右边的图片是使用 HOG 来表示的图片,除了可以看到图中能看出猫的外形,其他的细节包括背景几乎都被去除了,故右边的图片是左边图片的一种简化表示形式。HOG 可以用来表示物体的形状、外形特征,将这些特征输入分类器就可以实现目标的分类。

在传统的算法中,使用 HOG 描述图片,可以保留有用信息,剔除无用的信息,这样不仅减少计算量,还使得分类器的效果更好。HOG 可以分为以下几个步骤:预先归一化、计算水平和垂直方向梯度、计算梯度直方图、区域(Blocks)归一化。
预先归一化(Normalization)
在计算梯度前可对图片归一化(Normalization)处理,归一化的目的是使所有的数值落入到统一的范围内,从而使算法能有更好的表现。在 HOG 的原论文中提到使用伽马矫正的方法处理输入图片,伽马矫正可以增加图像的对比度。但是在很多情况下,伽马矫正对提升算法效果不明显,我们可以跳过图片预先归一化,直接计算图片梯度。根据一文讲解方向梯度直方图(hog),可以知道伽玛校正的函数为:
f
(
x
)
=
x
γ
f(x)=x^\\gamma
f(x)=xγ
即输出图像是输入图像的幂函数,指数为 γ \\gamma γ 。代码为:
import cv2
import numpy as np
img = cv2.imread('gamma.jpg', 0)
img2 = np.power(img/float(np.max(img)), 1.5)
自我感觉效果基本上就是向黑白靠拢,这种预处理确实意义不大。
计算梯度
图像的梯度计算是使用卷积核对图像进行卷积操作,例如我们可以使用矩阵 [[-1, 0, 1]] 和 [[-1], [0], [1]] 分别与图像上的每个像素进行运算来获得水平和垂直方向上的梯度。
G
x
=
I
×
W
x
G
y
=
I
×
W
y
\\beginaligned &G_x=I \\times W_x \\\\ &G_y=I \\times W_y \\endaligned
Gx=I×WxGy=I×Wy
然后再计算x和y方向梯度的合梯度,包括幅值 G G G和方向 θ \\theta θ:
g = g x 2 + g y 2 θ = arctan g y g x \\beginaligned &g=\\sqrtg_x^2+g_y^2 \\\\ &\\theta=\\arctan \\fracg_yg_x \\endaligned g=gx2+gy2θ=arctangxgy
上述的代码可以看Normalization中的链接,这里就不再引用,演示效果为:

上面左图是合并水平、垂直方向上的梯度获得的梯度幅值,可以看到相较于水平、垂直方向上的图片,左图中猫的轮廓更清晰明显。右图表示图片中的梯度方向。代码很简单,就是利用两个sobel算子,得到水平与垂直方向的梯度,然后利用cv2.cartToPolar,输入参数为 G x G_x Gx 和 G y G_y Gy,输出为向量的大小和角度值,即上面公式所得,具体的可以看如下链接:
方向梯度直方图
现在我们已经有了梯度幅值 G G G 和梯度方向 θ \\theta θ,接下来我们就可以计算方向梯度直方图了。在计算方向梯度直方图之前,我们需要将图片分成若干个小方格(Cells),为避免歧义下文皆书写为 Cell 或 Cells 。例如,下图是一张宽高为 649 × 385 649\\times 385 649×385 的图片,我们将其平均分割成若干个 Cells,每个 Cell 内包含 8 × 8 8\\times 8 8×8 个像素,所以图片的高被分为 ⌊ 385 ÷ 8 ⌋ = 48 \\lfloor 385\\div8 \\rfloor = 48 ⌊385÷8⌋=48 份,图片的宽被分为 ⌊ 649 ÷ 8 ⌋ = 81 \\lfloor 649\\div8 \\rfloor = 81 ⌊649÷8⌋=81 份( ⌊ ⌋ \\lfloor\\quad\\rfloor ⌊⌋ 表示向下取整),故整张图片有 48 × 81 48\\times 81 48×81 个 Cells。

至此我们已经将图片分成许多 Cells,对于每一个 Cell,一般梯度方向范围可分为 0 到 180 度(无符号)和 0 到 360 度(有符号),通常使用 0 到 180 度的范围。然后将 0 到 180 度按每 20 度分为9个区间,此即为梯度直方图,对应于角度0、20、40、60… 160,下面引出上述参考贴对应规则的图片:
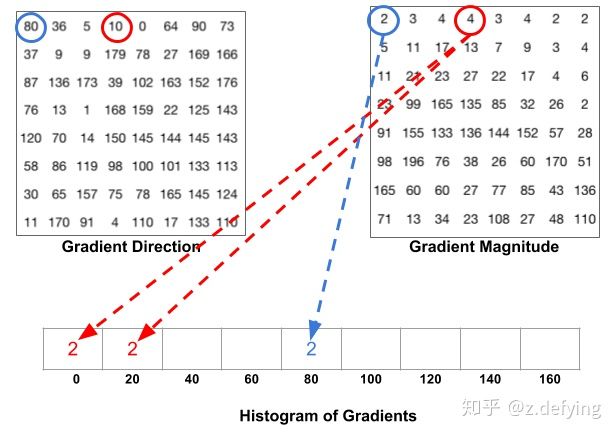
下图是一个计算方向梯度图的例子,对于红色方框中的像素,假设其中有些像素对应的梯度方向落在 0 到 20 区间,那么将这些像素对应的梯度幅值在 0 到 20 区间内进行累加,同理其他区间也做同样的运算,最终得到下图中右边的方向梯度直方图。同样地,整张图片中的所有 Cells 都用同样的方法计算方向梯度直方图:
区域(Blocks)归一化
HOG将8×8的一个区域作为一个cell,再以2×2个cell作为一组,称为block。由于每个cell有9个值,2×2个cell则有36个值,HOG是通过滑动窗口的方式来得到block的,我们用红色矩形框表示一个 Blcok,红色矩形框在图上向右滑动一个 Cell 的步长后我们就得到了蓝色矩形框,如下图所示:
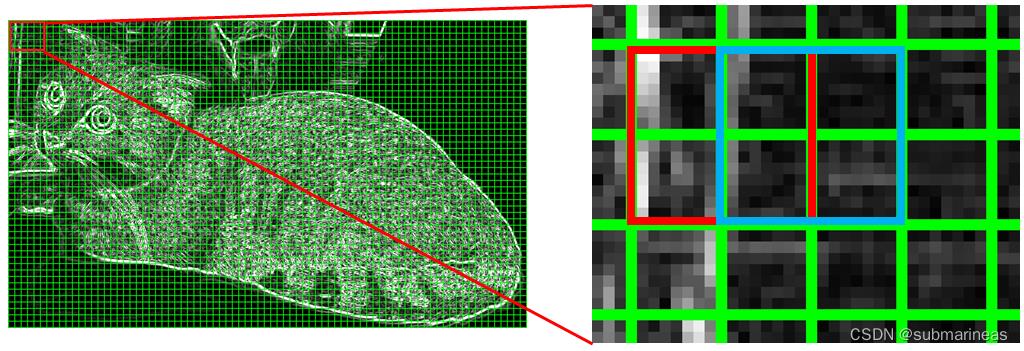
而接下来我们要对图像的每个block进行区域归一化处理,归一化的目的是减少光照变化对图像梯度的影响,那对于这种归一化方法,原参考链接中给出了一个例子。
假设我们有一个向量 [128,64,32],向量的长度为 12 8 2 + 6 4 2 + 3 2 2 = 146.64 \\sqrt128^2+64^2+32^2=146.64 1282+642+322=146.64 ,这叫做向量的 L 2 L2 L2 范数。将这个向量的每个元素除以146.64就得到了归一化向量 [0.87, 0.43, 0.22]。
事实上HOG确实是使用
L
2
L2
L2 范数会比
L
1
L1
L1 范数更好,它的归一化公式为:
v
=
v
i
∑
i
=
1
n
v
i
2
+
ϵ
2
v=\\fracv_i\\sqrt\\sum_i=1^n v_i^2+\\epsilon^2
v=∑i=1nvi2+ϵ2vi
其中 v i v_i vi 表示 Block 内的向量, ϵ \\epsilon ϵ 的作用是防止出现分母为 0 的情况,它是一个很小的值。
从上图中可以看出每一个 Cell 不止出现在一个 Block 内,也就是说一个 Cell 将被重复的用于归一化计算中,这样做会看似比较冗余,但是会提高特征描述的表现。最后对所有的 Block 完成归一化计算,合并所有获得的归一化后的向量,这样我们就完成了图像的 HOG 特征化表示。
代码实现
这里还是引用原链接的demo,然后加入了一些结合自己理解的注释:
from skimage import feature, exposure
import cv2
image = cv2.imread('xxxxx')
"""
image:输入图像
orientations:一个cell对应梯度范围,这里为9个区间,即 0 到 180 度;
pixels_per_cell:一个cell里包含的像素个数,需要传递一个元组给该参数,我们将 (8, 8) 传递给该参数;
cells_per_block:一个block包含的cell个数;
transform_sqrt:伽马校正,将 True 传递给该参数表示使用伽马校正预先对图片进行归一化处理;
visualize:表示可视化,将 True 传递给该参数表示返回 HOG 图像。
"""
fd, hog_image = feature.hog(image, orientations=9, pixels_per_cell=(16, 16),
cells_per_block=(2, 2), transform_sqrt=True, visualize=True)
# Rescale histogram for better display
"""
hog_image:前面获取的可视化二维数组
out_range:将输入图片的像素强度拉伸到设定的范围,这里是将hog_image中的每个元素值拉伸到 (0, 10) 范围内。建议是(0,255),不然会和原文中的显示图一样,归一化后的点因为拉伸太小,直接就变成了线
"""
hog_image_rescaled = exposure.rescale_intensity(hog_image, in_range=(0, 10))
cv2.imshow('img', image)
cv2.imshow('hog', hog_image_rescaled)
cv2.waitKey(0)==ord('q')
那么这大概就是HOG的整个原理介绍,当然本文的重点不在这里,HOG只是一种提取图像特征的算法,在很多检测领域会经常出现,它的优缺点都非常突出,优点在于算法比较简单直观,归一化抑制了光照颜色等影响,而缺点在于算法运行非常慢,主要是算子生成速度慢,基本不能运用于视频上,而且整个过程没有处理过噪声,对于遮挡问题都有很大影响。
针对HOG的缺点,接下来会根据它提取到的特征,训练一个SVM的模型,这也是opencv官方都给出的说明,但在此之前,可以看一个直接使用opencv实现猫狗识别的例子,这是根据这里的HOG还有前面第七篇滑动窗口与图像金字塔就能理解的很短的demo。
使用opencv实现猫狗识别
我记得很久之前,很多自媒体,比如公众号,某站等,都会起一个很雷人的标题:震惊!如此容易!不到20行的人脸 or 猫狗识别代码,关于人脸,我上一篇已经写过关于特征点的耳鼻喉检测,这里同样,有一个官方的代码:
# -*- coding=utf-8 -*-
import cv2
# 加载猫脸检测器
catPath = "haarcascade_frontalcatface.xml"
faceCascade = cv2.CascadeClassifier(catPath)
# 读取图片并灰度化
img = cv2.imread("xxx.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 猫脸检测
faces = faceCascade.detectMultiScale(
gray, # 灰度图,可以加快检测速度
scaleFactor= 1.02, # 表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%
minNeighbors=3, # 表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除
minSize=(150, 150), # 目标的最小尺寸
flags=cv2.CASCADE_SCALE_IMAGE # 一般都为默认值,或者canny,即选用什么边缘检测器来排除边缘过多或过少的区域,不过最新的版本好像没有这个参数了,但目前我这边还能用
)
# 框出猫脸并加上文字说明
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.putText(img,'Cat',(x,y-7), 3, 1.2, (0, 255, 0), 2, cv2.LINE_AA)
# 显示图片并保存
cv2.imshow('Cat?', img)
cv2.imwrite("cat.jpg",img)
c = cv2.waitKey(0)
# 关于detectMultiScale更详细的参数解释,可以看如下Stack Overflow链接讨论的内容
# https://stackoverflow.com/questions/36218385/parameters-of-detectmultiscale-in-opencv-using-python
关于haarcascade_frontalcatface.xml这个文件,可以在opencv官方提供的xml中找到,大概1.3M左右的样子,代码强行扩展到24行,其实整个函数核心就2行,一个cv2.CascadeClassifier加载,一个 faceCascade.detectMultiScale检测,具体的我按自己的理解加上了注解,而根据图像识别猫脸的代码及详解 一文中提到的,该模型可能会出现很多个框被判定为cat,这个其实就是没有做极大值抑制的结果,

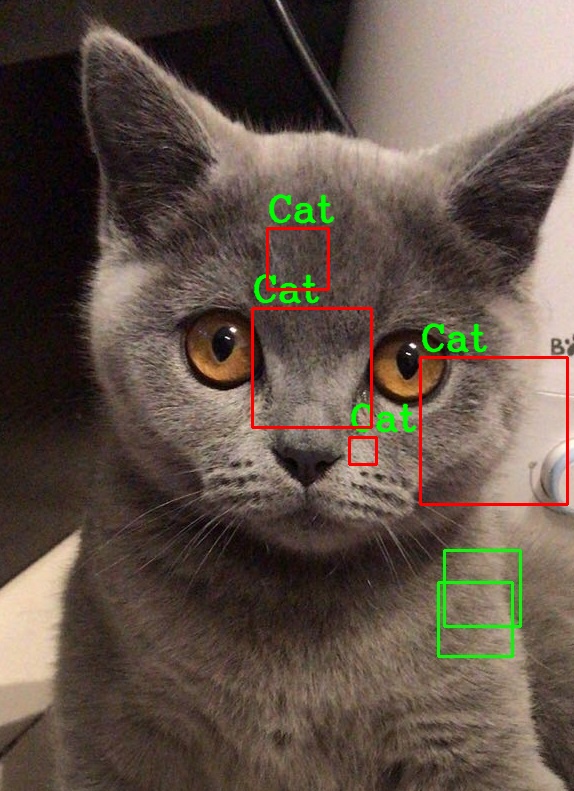
import cv2 as cv
########## hog+svm 行人检测 #####################
src = cv.imread('xxxx')
cv.imshow("input", src)
hog = cv.HOGDescriptor()
# opencv的 默认的 hog+svm行人检测器
hog.setSVMDetector(cv.HOGDescriptor_getDefaultPeopleDetector())
# Detect people in the image
(rects, weights) = hog.detectMultiScale(src,
winStride=(2, 4),
padding=(8, 8),
scale=1.2,
useMeanshiftGrouping=False)
for (x, y, w, h) in rects:
cv.rectangle(src, (x, y), (x + w, y + h), (0, 255,<以上是关于opencv-python学习笔记:目标检测理论体系与实践说明的主要内容,如果未能解决你的问题,请参考以下文章
[OpenCV-Python] OpenCV 中计算摄影学 部分 IX 对象检测 部分 X
OpenCV-Python实战(19)——OpenCV与深度学习的碰撞