通用目标检测开源框架YOLOv6在美团的量化部署实战
Posted 美团技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通用目标检测开源框架YOLOv6在美团的量化部署实战相关的知识,希望对你有一定的参考价值。
基于美团目标检测模型开源框架 YOLOv6,本文介绍了一种通用的量化部署方案,在保持精度的同时大幅提升了检测的速度,为通用检测的工业化部署探索出一条可行之路,希望能给大家带来一些启发或者帮助。
1. 背景和难点
YOLOv6 是美团发布的一款开源的面向工业应用的 2D 目标检测模型 [1],主要特点是速度快、精度高、部署友好,在美团众多视觉业务场景中都有着广泛的应用。通过量化(Quantization)提升推理速度是实际工业应用中的基本操作,但由于 YOLOv6 系列模型采用了大量的重参数化模块,如何针对 YOLOv6 进行高效和高精度的量化成为一个亟待解决的问题。
本文旨在解决 YOLOv6 量化方面的难题,并以 YOLOv6s 模型为例,从训练后量化(Post-Training Quantization, PTQ)和量化感知训练(Quantization-Aware Training, QAT)两个方面进行分析,探索出了一条切实可行的量化方案。
YOLOv6 采用了多分支的重参数化结构 [2] (如图 1A 所示),通过在网络结构层面加入人工先验可以在训练阶段让模型更好收敛。在推理阶段,多分支可以等价合并为单路,从而提升运行速度。但现有的训练后量化方法,不能很好应对多分支结构带来的剧烈变动的数值范围,导致量化后产生严重的精度损失 [3]。另外,如何针对多分支结构设计量化感知训练(QAT)方法也面临着较大的挑战。蒸馏常被用来辅助 QAT 提升性能,但如何应用 2D 目标检测的蒸馏方法来辅助 YOLOv6 模型的量化,也需要设计合理的方案在实际应用中进行检验。
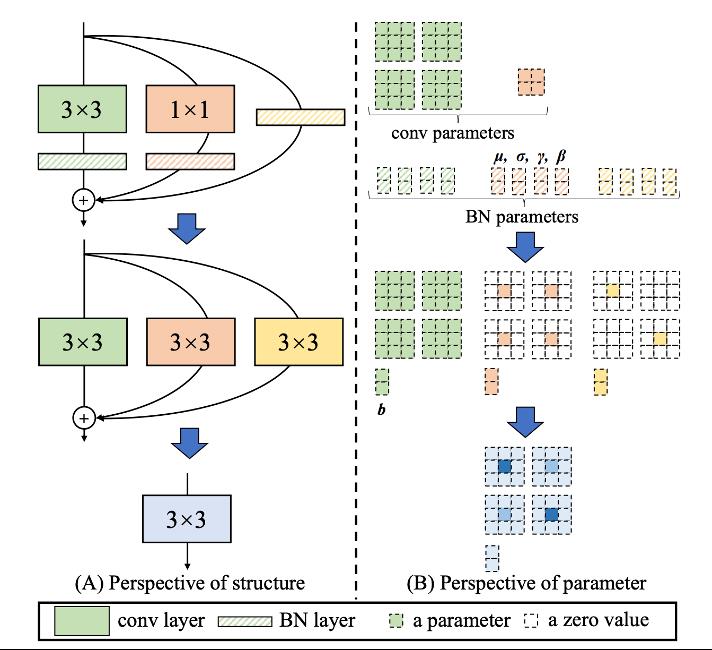
2. 量化方案实战
2.1 重参数化优化器
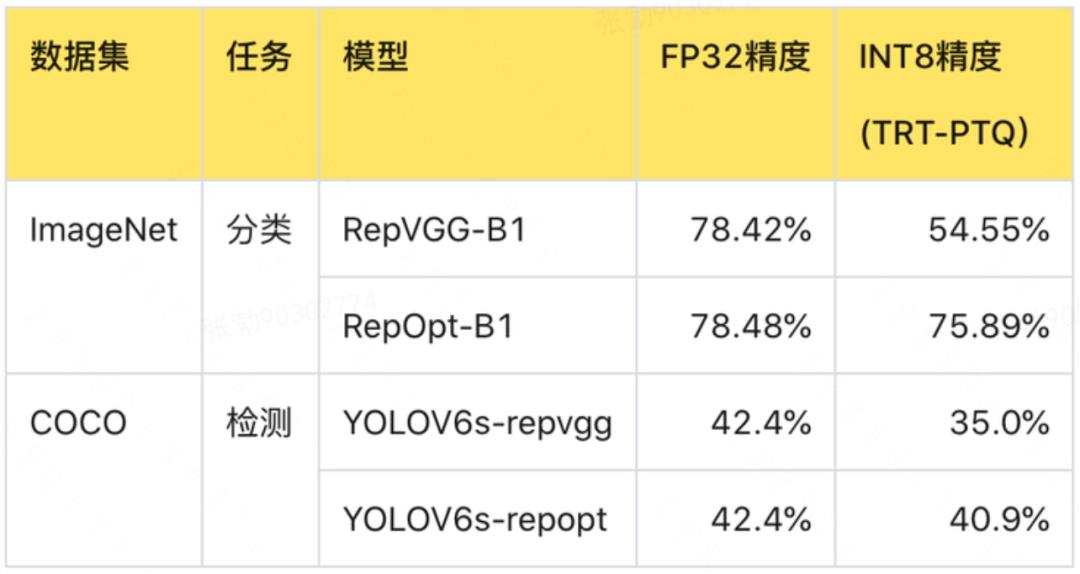
YOLOv6 网络中大量使用重参数化结构,在提高模型训练精度的同时能够显著降低模型部署推理延时,但也带来了模型量化部署方面的难题。对重参数化网络的直接量化一般会带来不可接受的精度损失,例如 RepVGG-B1 [2] 网络在 ImageNet 数据集上的浮点精度为 78.42%,采用 TensorRT 后量化(PTQ)的量化模型精度则降低为 54.55%。
此外,由于重参数化结构在训练和部署时结构不同,因此无法直接适配现有的量化感知训练(QAT)方法,如何使用 QAT 方法来提高 YOLOv6 量化模型的精度,同样存在着挑战。近期,一篇重参数化优化器的工作 RepOpt [3] 较好地解决了重参数化结构的量化问题。
2.1.1 RepOpt
RepOpt [3] 对重参数化结构量化困难的问题进行了研究,发现重参数结构的分支融合操作,显著放大了权重参数分布的标准差。异常的权重分布产生了过大的网络激活层数值分布,进一步导致该层量化损失过大,因此模型精度损失严重。
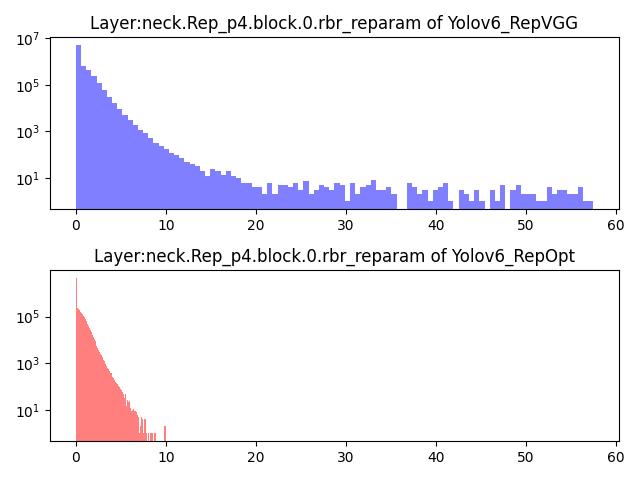
鉴于此,我们统计了基于 RepVGG 结构的 YOLOv6 模型(YOLOv6s_repvgg)各层的权重及激活数值分布,分析了 YOLOv6 中的重参数化层的数据分布。下图 2 以 “Rep_p4.block.0.rbr_reparam” 层为例,给出其特征图数值分布直方图,我们发现其数值广泛分布在 [0, 57] 的区间内。显然,采用现有的 INT8 量化方法,无论怎样选择量化缩放参数 (scale),都会产生较大的量化误差。
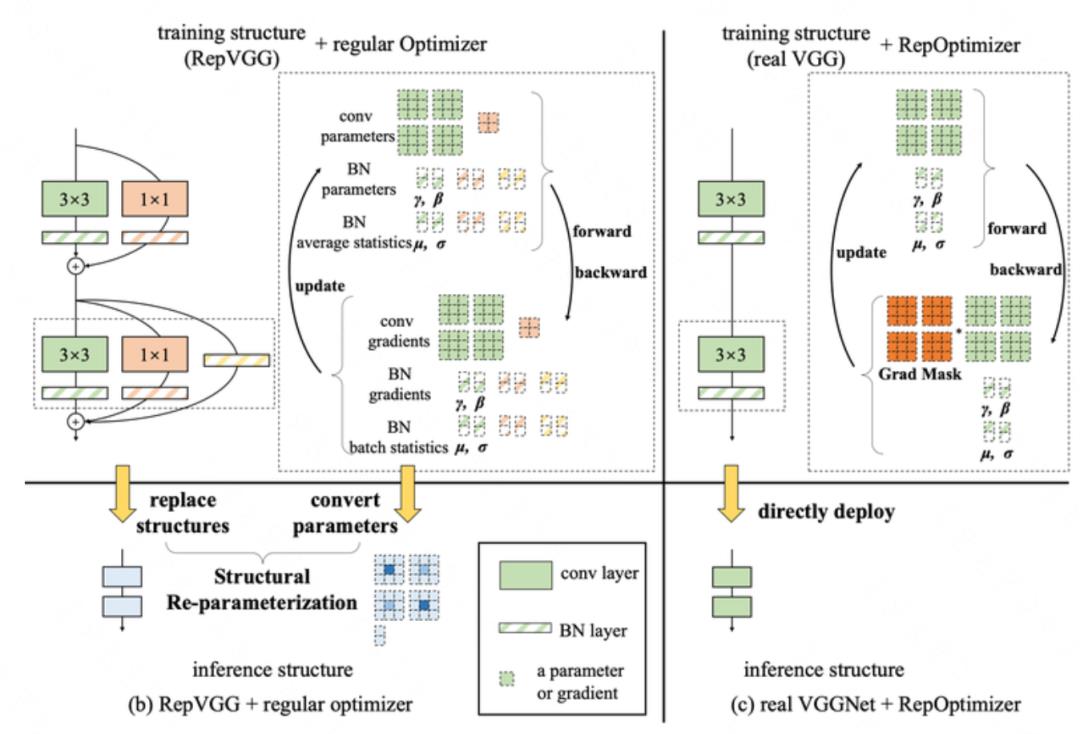
为解决这一问题,RepOpt 提出了一种基于优化器的重参数化设计(如下图 3 所示),通过梯度掩码(Gradient Mask)的方式在网络训练反向传播的过程中加入先验,保证了训练精度可达到 RepVGG 相近的水平,而网络结构则在训练和推理阶段始终保持普通的 VGG 结构,这种训练方法请参考 RepOpt [3]。该工作中提出的 RepOpt-B1 网络模型,在浮点精度与 RepVGG-B1基本一致的情况下,量化模型精度提升超过 20%,极大地改善了重参数化网络的量化掉点问题。此外,RepOpt模型的训练速度快,内存占用也比较低。
2.1.2 RepOpt 版本的 PTQ
我们实现了 RepOpt 版本的 YOLOv6s网络(YOLOv6s_repopt),达到了与 YOLOv6s_repvgg 一致的浮点精度 42.4% (300 epoch),两个版本的网络结构在部署阶段保持一致。我们首先分析了 YOLOv6s_repopt 模型的数据分布特征。
如图 2 所示,给出了“Rep_p4.block.0.rbr_reparam” 层的特征图数值分布直方图,可以看到数值紧密分布在 [0, 10] 的区间内,相比 YOLOv6s_repvgg 的数值分布对于量化操作更加友好。进一步采用 TRT 的后量化方法进行模型量化部署,可以看到 YOLOv6s_repvgg 的量化网络精度降低了 7.4%,在实际工程中基本不可用。而 YOLOv6s_repopt 网络的量化模型精度为 40.9%,精度损失仅为 1.5%,相比原版模型有了极大的改善。
2.1.3 RepOpt 版本的 QAT
此外,使用 RepOpt 结构解决了原本的 RepVGG 网络无法直接使用现有量化感知训练的问题。对于结构重参数化的 RepVGG 网络,如何使用 QAT 来恢复量化模型精度,我们一直存有困扰。如下图 4(左)所示,如果对重参数化操作之前的多分支网络进行 QAT,对每个分支分别添加伪量化算子进行量化感知训练,由于每个分支的量化参数不同,导致多分支结构无法等效融合进行高性能部署;如果对重参数化操作之后的单分支网络进行 QAT, 由于网络中不再有 BN 层,使用 QAT 方法进行微调并不容易恢复到浮点精度。而对于 RepOpt 结构网络则不存在这一问题,因为 RepOpt 在训练和部署中网络结构是保持一致的。
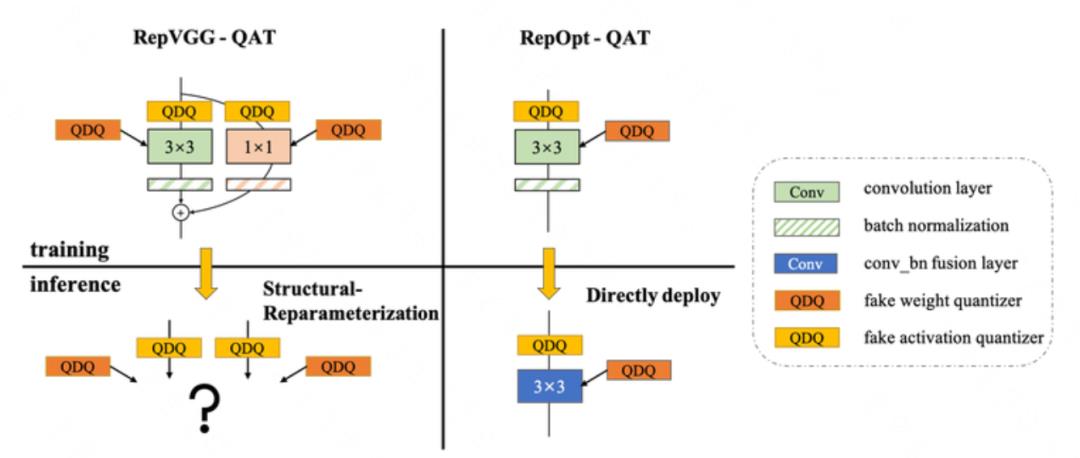
如图 4 (右)所示,对 RepOpt 的卷积等算子加入伪量化节点进行量化感知训练,提升量化模型精度,然后直接部署该量化模型,而不需要再进行模型融合的操作。后文,我们将给出具体的 QAT 算法及对模型精度的提升结果。
2.2 基于量化敏感度分析的部分量化
YOLOv6s_repopt 在 PTQ 后的 mAP 达到了 40.9%,虽然比之前的 35.0% 有了很大的改善,但仍然有 1.5% 的精度损失,还无法满足业务需求。因此,我们采用了部分量化(Partial PTQ),一种使网络中的部分量化敏感层恢复浮点计算,来快速恢复量化模型精度的方法。首先需要对网络中的每一层都进行量化敏感度分析。
我们在 YOLOv6s-repopt 网络上对常用的敏感度分析方法均方误差(MSE)、信噪比(SNR)、余弦相似度(Cosine Similarity)进行了对比测试。量化校准(calibration)测试使用 4 个 batch 的数据,敏感度计算用 1 个 batch,batch 大小设置为 32。
测试时,每次只对一层进行量化,获取该层的激活数据后计算敏感度数值,代表了该层的量化敏感度。作为对比,我们可以直接计算网络在 COCO val 数据集上的 mAP,使用检测精度作为该层的量化敏感度,即检测精度越高,该层敏感度越低(下文称为 mAP 方法)。
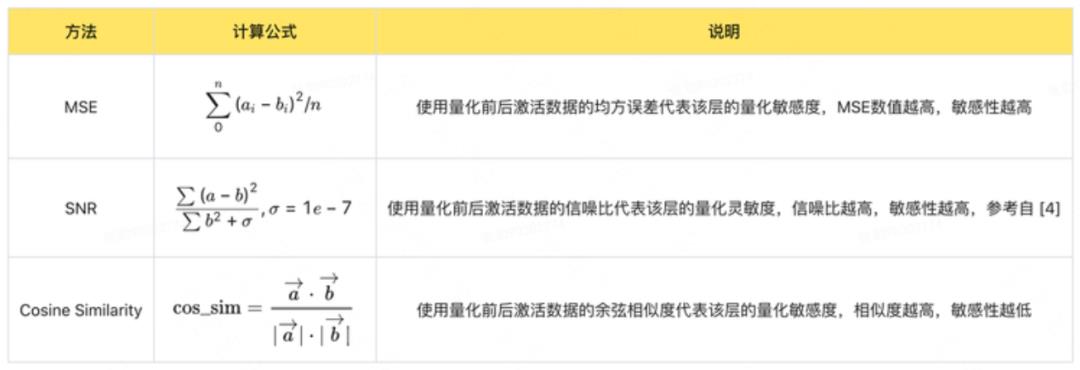
测试结果如下图 5 所示,我们对测试结果进行归一化后,从不同敏感度分析结果中选择敏感性最高的 6 层跳过,计算部分量化精度。
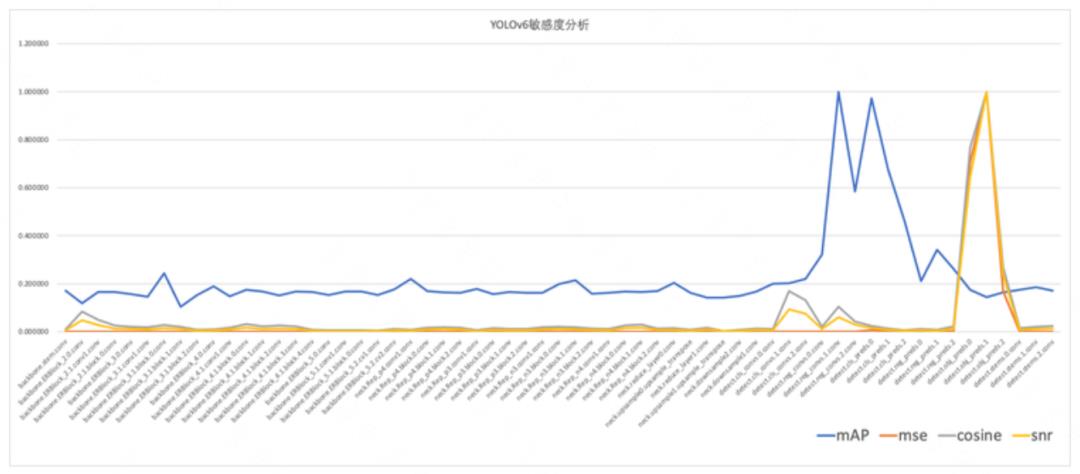
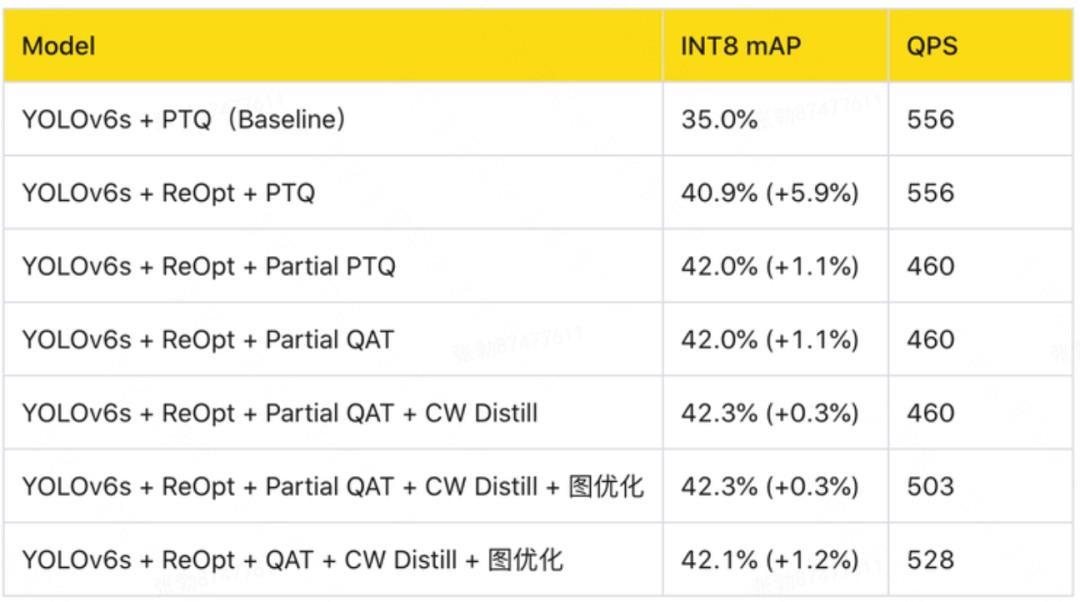
部分量化精度如下表 3 所示,可以看到:mAP 方法取得了最好的效果,能够有效代表 YOLOv6 敏感度分析结果。但由于 mAP 方法需要频繁地计算验证集精度,耗时太久且容易过拟合验证集,因此在实际项目中为了追求效率,我们建议使用 MSE 方法。
2.3 基于通道蒸馏的量化感知训练
至此,我们优化后的 PTQ 的精度达到了 42.0%,进一步提高模型精度需要引入量化感知训练(QAT)。量化感知训练(Quantization Aware Training, QAT)可以改善 PTQ 量化精度损失,通过在训练过程中对卷积等算子加入伪量化操作(如图 4 所示),使得网络参数能更好地适应量化带来的信息损失,从而显著降低量化后的精度损失。
模型蒸馏作为一种有效的提升小模型精度的方法,在 QAT 过程中被广泛使用,来提升量化模型的精度。以下,我们将探索针对 YOLOv6 网络的量化感知训练方法。
2.3.1 通道蒸馏
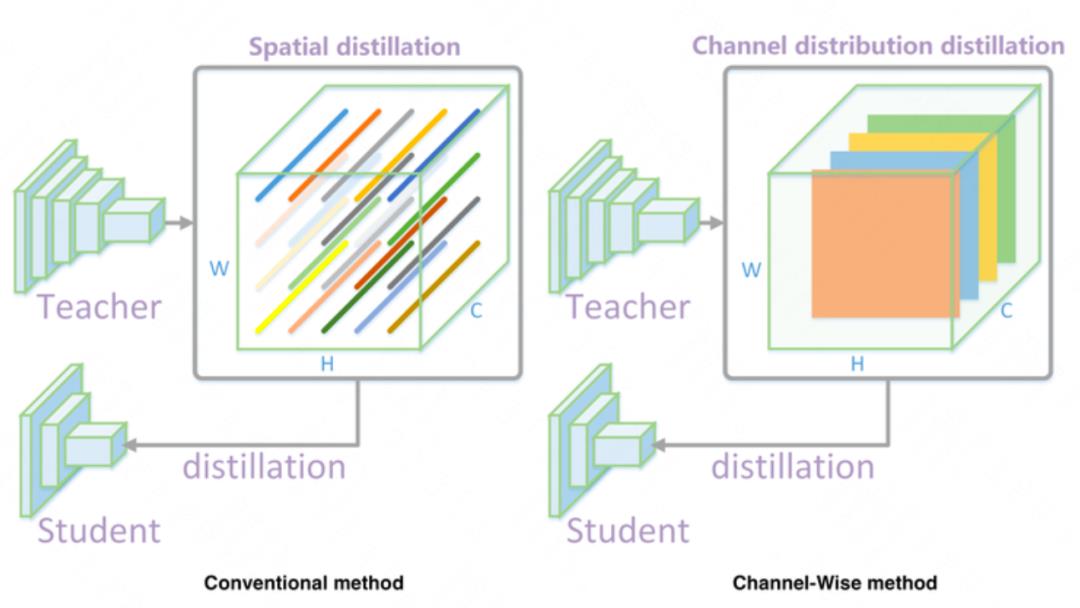
传统的分类网络在蒸馏时,往往对最后一层输出的 logits 进行蒸馏;但是在检测网络中一般采用“特征图”蒸馏的方法,直接让学生网络(student)输出的特征图拟合教师网络(teacher)输出的特征图(一般不会选取整个特征图,而是一些感兴趣区域)。
这种方法的缺陷是特征图中的每个 pixel 对蒸馏的损失贡献相同。我们采用了每通道分布蒸馏 [6],即让 student 输出的每个通道的分布拟合 teacher 输出的每个通道的分布。两种方法的区别如下图 6 所示:
2.3.2 YOLOv6 量化感知蒸馏框架
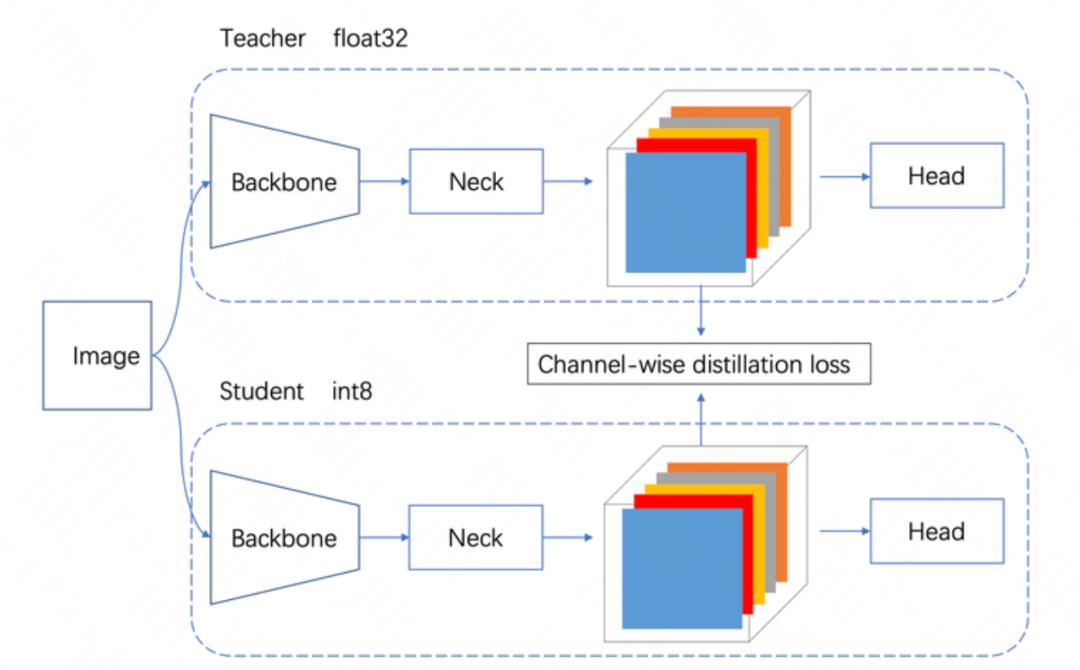
针对 YOLOv6s,我们选择对 Neck(Rep-PAN)输出的特征图进行通道蒸馏(Channel-Wise Distillation, CW)。另外,我们采用“自蒸馏”的方法,教师模型是 FP32 精度的 YOLOv6s,学生模型是 INT8 精度的 YOLOv6s。下图 7 是一个简化示意图,只画出了 Neck 的一个分支:
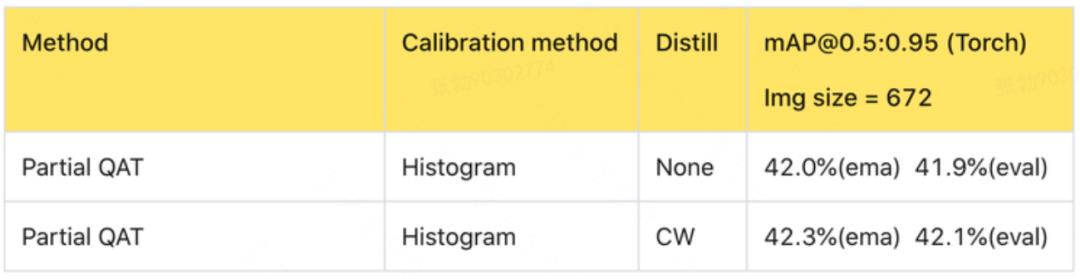
如下表 4 所示,在 Partial QAT 中引入通道蒸馏方案(CW),量化精度进一步提升了 0.3%。
3. 部署时优化
3.1 图优化
量化部署时,可以直接利用 TensorRT 的 PTQ 接口进行生成量化引擎,但是这种方法往往精度损失较大。因此,一般要先进行 QAT,使量化模型精度满足业务需求,然后导出带有“Quant”、“DeQuant”节点的 ONNX,最后再利用 TensorRT 构建量化引擎。我们发现这两种方案最终生成的图结构并不相同,导致部署模型的实际运行效率存在很大的差异,通常 QAT 方法生成的模型效率更低。
我们在 NVIDIA T4 机器上对量化模型进行了对比测试(见下表 5)。尽管 QAT INT8 模型的 QPS 比 FP16 高了~27%,但是离 PTQ INT8 还有较大差距。我们对此现象进行了细致的分析,发现原因是 QAT 引入的“Quant”,“DeQuant”节点打破了原有 TensorRT 的融合策略,导致了很多算子无法融合,从而影响了最终量化引擎的性能。在这一节中,我们以 YOLOv6s_repopt 为例,展示一种定位具体瓶颈的图优化方法。在量化实践中,图优化是一个很实用的手段,我们可以依法炮制,提升模型的 QPS。

3.1.1 性能分析
首先,我们利用 nsys 工具 [5] 对 QAT INT8 的模型和 PTQ INT8 模型进行了性能分析,如下表所示:

从中我们发现,QAT INT8 有 10.8% 的 kernel 执行了 permutationKernelPLC3 操作,这些操作对应 quantize_scale_node 节点,如下图 8 所示:

3.1.2 图结构分析
为什么 QAT INT8会有大量的 permutationKernelPLC3 操作?我们利用 trtexec 和 pltEngine 工具,画出了 PTQ INT8 和 QAT INT8 的计算图,并进行了仔细的分析。下图 9 是其中一个子图的对比:
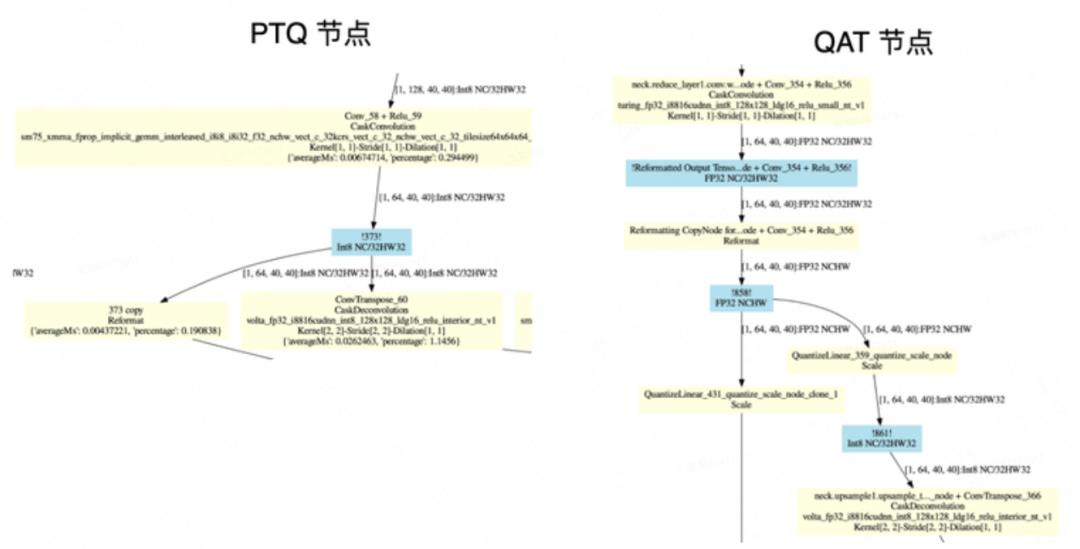
QAT INT8 计算图中 neck.reduce_layer1.conv 融合节点输出精度是 FP32,并且跟了 2 个 quantize_scale_node 节点,而 PTQ INT8 图中的 neck.reduce_layer1.conv 融合节点输出的是 INT8。很显然,QAT 图中 FP32 和 INT8 之间的转换会带来额外的开销。我们又利用 Netron 来分析 QAT INT8 的 ONNX 图结构,找到了 neck.reduce_layer1.conv 这个位置,图 10 给出该节点示意。
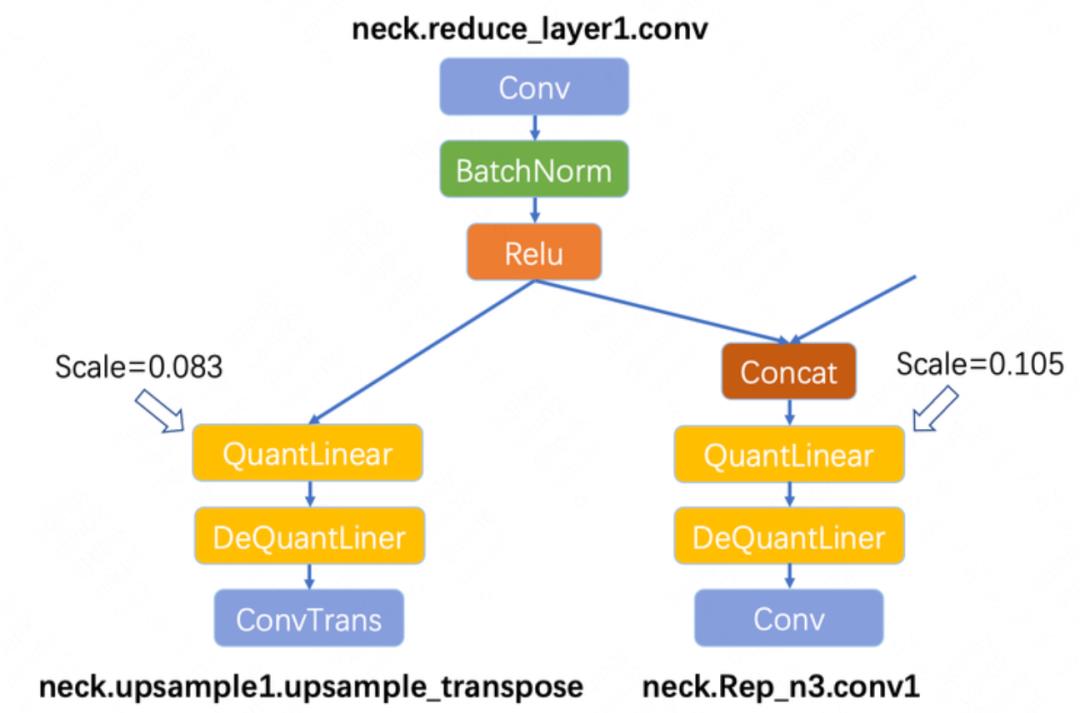
通过分析 ONNX 图结构,我们发现了QAT INT8 引擎中 neck.reduce_layer1.conv 输出为 FP32,并且为两个分支保留了quantize_scale_node 的原因。因为 neck.upsample1.upsample_transpose 分支的输入量化 scale 为 0.083,而 neck.Rep_n3.conv1 分支的输入量化 scale 为 0.105,这两个节点输入尺度是不同的,导致 neck.reduce_layer1.conv 无法直接输出为 INT8。
可以看出,对于同一个输出,输入到多路分支后为何 scale 不同的,原因是右边的分支经过了 concat 操作,会导致输出的数据分布发生变化,再进行激活校准(Activation Calibration)时,会得到的不同的最佳截断值 (Activaition Max)。
3.1.3 图结构优化
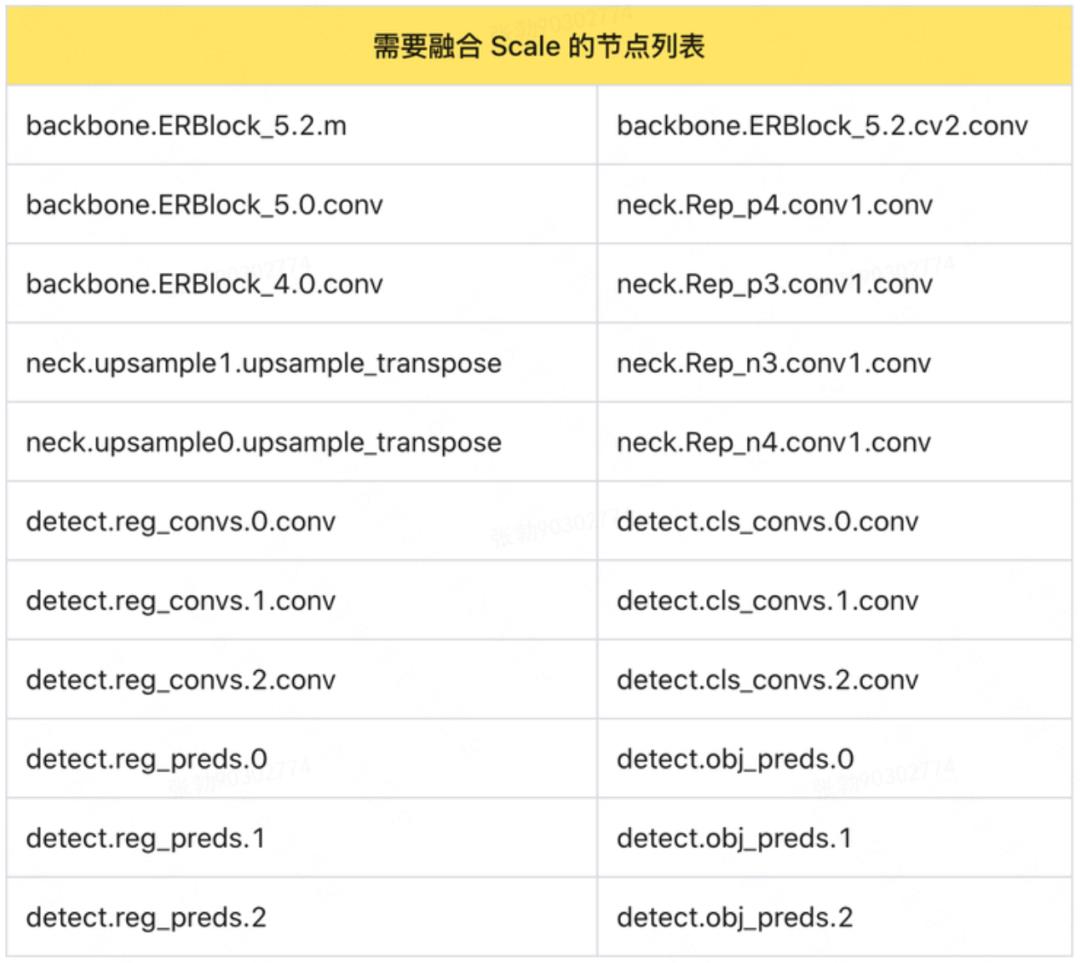
根据上面的分析,如果一个节点的输出,输入到不同的分支节点中,并且分支节点的量化 scale 不同,则 quantize_scale_node 节点无法融合,进而导致了额外的开销。如何解决这个问题?我们使用了一个简单的方法,就是强制使所有分支节点的量化 scale 相同(根据经验,在同一数量级上的 scale 可以安全合并),即直接修改 QAT 网络中的 Quantizer 节点的参数。
我们整理了 YOLOv6s_repopt 中所有需要进行 scale 融合的节点(如表 7 所示),由于 TensorRT 的 8 bit 的量化范围是[-127,127],所以只需要将多路分支的 Activation Amax 设为同一个值,一般取多路分支中的最大值。
3.1.4 性能测试
经过以上的多路分支的 scale 融合后,我们再次利用 trtexec 和 pltEngine 工具,画出了 QAT INT8 进行优化前后的图结构。可以发现,quantize_scale_node 节点已经全部被融合。
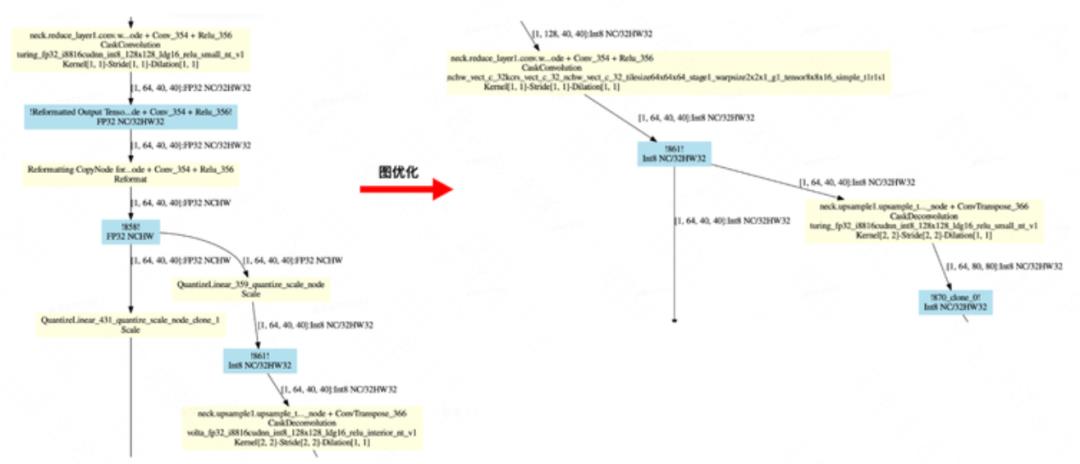
我们测试了经过图优化的 QAT 模型,QPS 达到了 528,性能非常接近 PTQ 的 556,而且 mAP 依然保持优化前的 42.1%。

3.2 线上服务优化
我们在 NVIDIA T4 服务器上进行了端到端的吞吐测试,利用“多实例”并发处理的技术,YOLOv6s_repopt INT8 QPS 达到了 552,相较 FP16 提升了~40%。我们对服务器的各项指标进行了监测,发现此时 T4 GPU 的利用率只有 95%,还有压榨空间,而 16 核 CPU 利用率已经超过了 1500%,几乎满负荷运转。我们推测整个线上服务的“瓶颈”可能在 CPU,而图片预处理会使用大量 CPU 资源。
3.2.1 DALI 预处理
为了解决 CPU 预处理带来的“瓶颈”,我们采用了 NVIDIA 的 DALI 库,将预处理直接放到 GPU 中运算。该库可以在 GPU 上对二进制图片进行解码和预处理,极大的缓解 CPU 瓶颈,下图 12 为 DALI 的经典流程。
3.2.2 吞吐测试
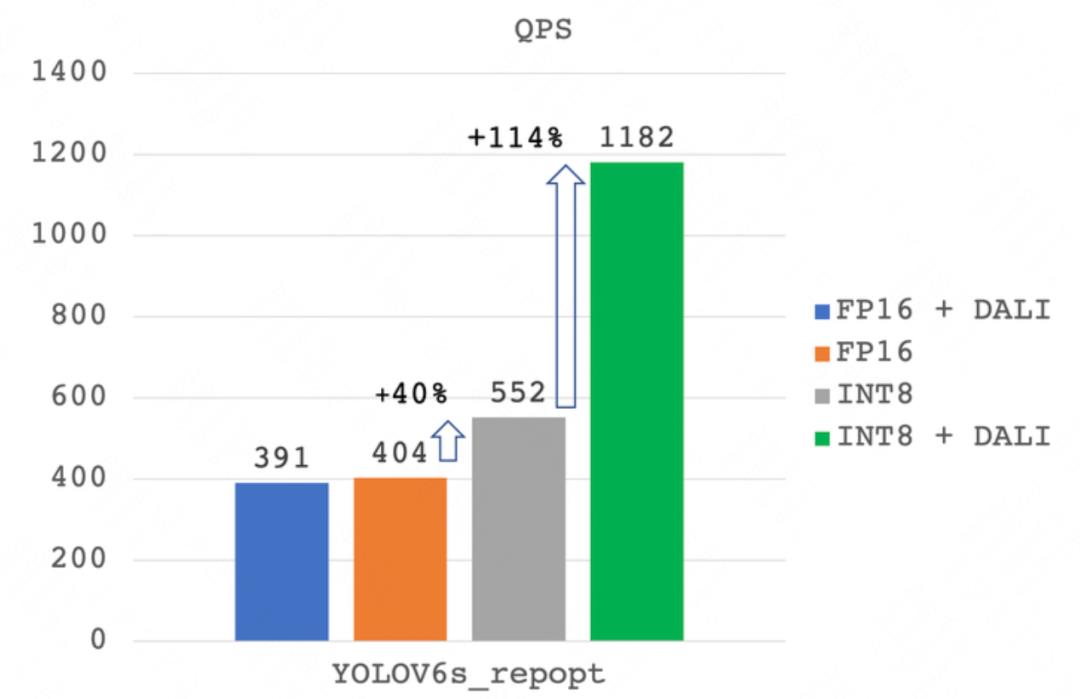
如下图 13 所示,INT8 + DALI 的吞吐达到了 1182 imgs/s,比 INT8 吞吐提升了 1.14 倍。引入 DALI 预处理后,T4 GPU 利用率达到了100%,而 16 核 CPU 的利用率则下降到了 1100% 左右,部分 CPU 资源得到了“解放”。另外,我们也测试 FP16 + DALI 的吞吐,反而有略微的下降。我们推测是 DALI 抢占了部分 GPU 计算资源,而 FP16 服务的瓶颈在 GPU,所以对整体性能产生了负面影响。
4. 总结
综上所述,本文基于 YOLOv6 V1.0 版本,以 YOLOv6s 为例探讨了基于重参数化结构设计的 2D 检测模型的量化难点和具体方案,在模型精度基本保持的前提下,通过量化加速,提升了约 40% 的 QPS。部署时的预处理优化则额外提升了 214%,极大地提升了工业部署吞吐能力。下表列出了本文尝试的方法及叠加效果。
本文使用的速度测试环境见表 11, 测试输入 batch size 为 1,尺寸为 640x640。

YOLOv6 版本更新
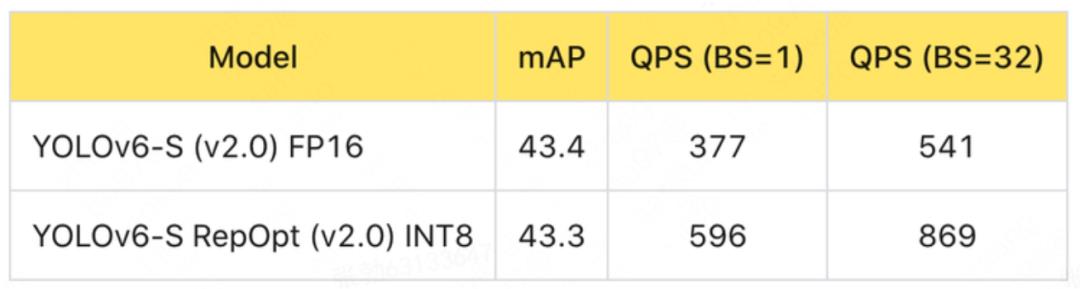
近日,YOLOv6 已经更新了 V2.0 版本,并新增了中大型网络,对轻量级和小网络的性能进行了全面升级,进一步提升综合性能,量化效果也得到大幅提升,其中 YOLOv6-S 量化模型达到了 43.3mAP 和 869 FPS (TensorRT 8.4)。更多详细内容请关注官方出品的技术报告 [7]。
我们希望通过分享本文的实践,进一步推动最新通用目标检测算法的落地。未来,我们会和业界同行一道,探索更优的量化方案,持续提升量化精度和推理速度,助力降本增效,深化业务价值。
5. 参考文献
[2] RepVGG: Making VGG-style ConvNets Great Again,https://arxiv.org/abs/2101.03697
[3] ReOpt: Re-parameterizing Your Optimizers rather than Architectures
[4] SNR: https://github.com/openppl-public/ppq/blob/8a849c9b14bacf2a5d0f42a481dfa865d2b75e66/ppq/quantization/measure/norm.py
[5] Nsight-systems: https://docs.nvidia.com/nsight-systems/UserGuide/index.html
[6] Channel-wise Knowledge Distillation for Dense Prediction, https://arxiv.org/abs/2011.13256
[7] YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications, https://arxiv.org/abs/2209.02976
6. 本文作者
庆源、李亮、奕铎、张勃、王新、祥祥等,来自美团基础研发平台数据科学与平台部和视觉智能部。
---------- END ----------
也许你还想看
| 目标检测开源框架YOLOv6全面升级,更快更准的2.0版本来啦
| CVPR 2021预讲:前沿视觉技术如何在实践中落地(内含视频&PPT)
阅读更多
以上是关于通用目标检测开源框架YOLOv6在美团的量化部署实战的主要内容,如果未能解决你的问题,请参考以下文章