睿智的目标检测60——Pytorch搭建YoloV7目标检测平台
Posted Bubbliiiing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了睿智的目标检测60——Pytorch搭建YoloV7目标检测平台相关的知识,希望对你有一定的参考价值。
睿智的目标检测60——Pytorch搭建YoloV7目标检测平台
学习前言
AB哥弄了个YoloV7,我觉得有必要跟进看看,它的concat结构还是第一次见,感觉有点意思。

源码下载
https://github.com/bubbliiiing/yolov7-pytorch
喜欢的可以点个star噢。
YoloV7改进的部分(不完全)
1、主干部分:使用了创新的多分支堆叠结构进行特征提取,相比以前的Yolo,模型的跳连接结构更加的密集。使用了创新的下采样结构,使用Maxpooling和步长为2x2的特征并行进行提取与压缩。
2、加强特征提取部分:同主干部分,加强特征提取部分也使用了多输入堆叠结构进行特征提取,使用Maxpooling和步长为2x2的特征并行进行下采样。
3、特殊的SPP结构:使用了具有CSP机构的SPP扩大感受野,在SPP结构中引入了CSP结构,该模块具有一个大的残差边辅助优化与特征提取。
4、自适应多正样本匹配:在YoloV5之前的Yolo系列里面,在训练时每一个真实框对应一个正样本,即在训练时,每一个真实框仅由一个先验框负责预测。YoloV7中为了加快模型的训练效率,增加了正样本的数量,在训练时,每一个真实框可以由多个先验框负责预测。除此之外,对于每个真实框,还会根据先验框调整后的预测框进行iou与种类的计算,获得cost,进而找到最适合该真实框的先验框。
5、借鉴了RepVGG的结构,在网络的特定部分引入RepConv,fuse后在保证网络x减少网络的参数量
6、使用了辅助分支辅助收敛,但是在模型较小的YoloV7和YoloV7-X中并没有使用。
以上并非全部的改进部分,还存在一些其它的改进,这里只列出来了一些我比较感兴趣,而且非常有效的改进。
YoloV7实现思路
一、整体结构解析
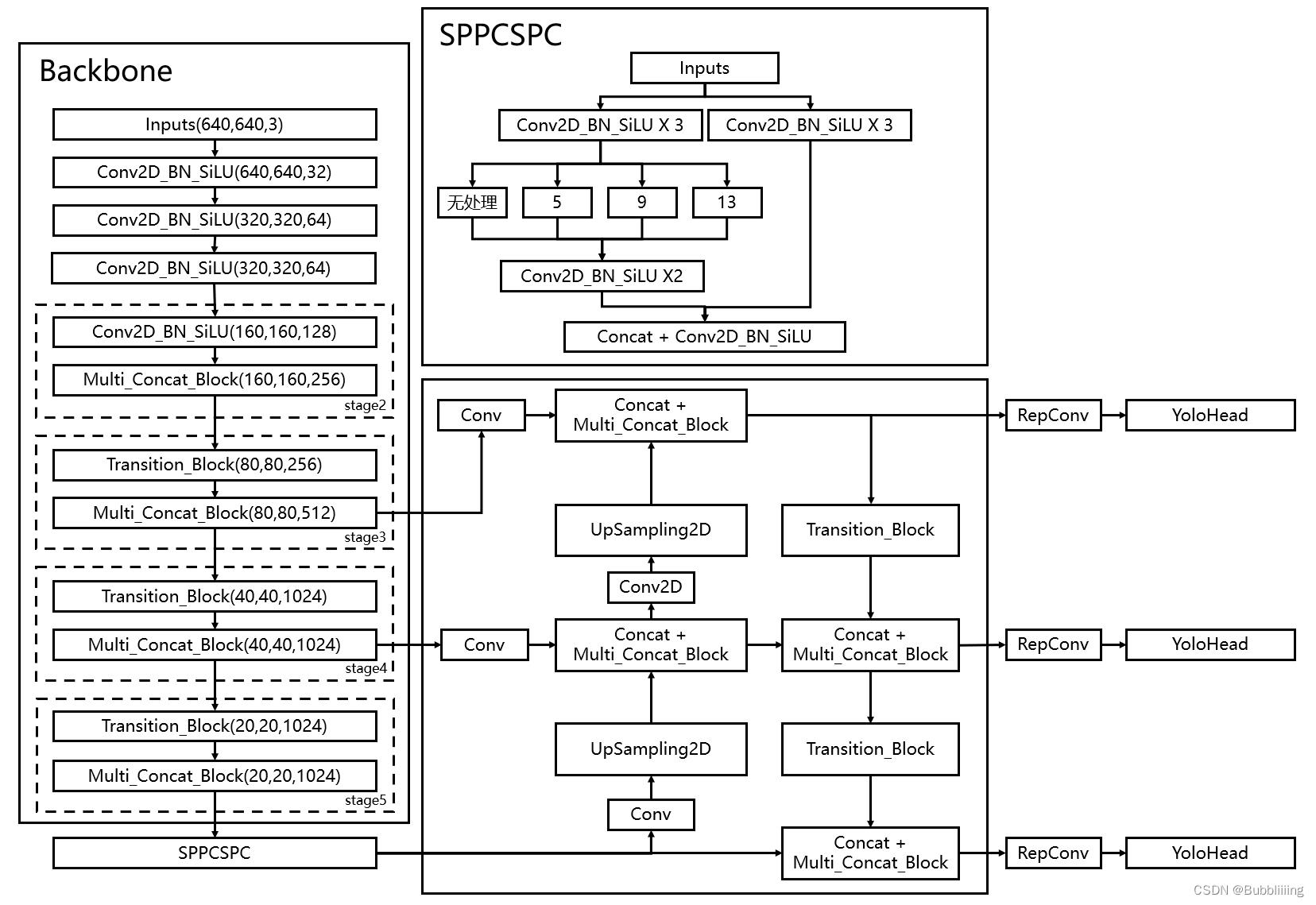
在学习YoloV7之前,我们需要对YoloV7所作的工作有一定的了解,这有助于我们后面去了解网络的细节,YoloV7在预测方式上与之前的Yolo并没有多大的差别,依然分为三个部分。
分别是Backbone,FPN以及Yolo Head。
Backbone是YoloV7的主干特征提取网络,输入的图片首先会在主干网络里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN是YoloV7的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV7里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
Yolo Head是YoloV7的分类器与回归器,通过Backbone和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每个特征点上有三个先验框,每一个先验框都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点上的先验框是否有物体与其对应。与以前版本的Yolo一样,YoloV7所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YoloV7网络所作的工作就是 特征提取-特征加强-预测先验框对应的物体情况。
二、网络结构解析
1、主干网络Backbone介绍
YoloV7所使用的主干特征提取网络具有两个重要特点:
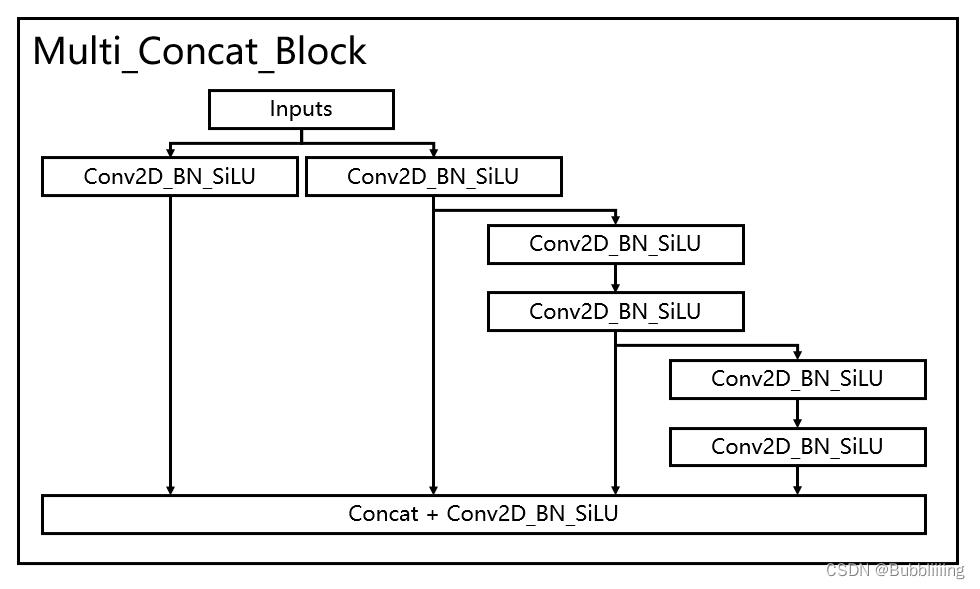
1、使用了多分支堆叠模块,这个模块其实论文里没有命名,但是我在分析源码后认为这个名字非常合适,在本博文中,多分支堆叠模块如图所示。
看了这幅图大家应该明白为什么我把这个模块称为多分支堆叠模块,因为在该模块中,最终堆叠模块的输入包含多个分支,左一为一个卷积标准化激活函数,左二为一个卷积标准化激活函数,右二为三个卷积标准化激活函数,右一为五个卷积标准化激活函数。
四个特征层在堆叠后会再次进行一个卷积标准化激活函数来特征整合。
class Multi_Concat_Block(nn.Module):
def __init__(self, c1, c2, c3, n=4, e=1, ids=[0]):
super(Multi_Concat_Block, self).__init__()
c_ = int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = nn.ModuleList(
[Conv(c_ if i ==0 else c2, c2, 3, 1) for i in range(n)]
)
self.cv4 = Conv(c_ * 2 + c2 * (len(ids) - 2), c3, 1, 1)
def forward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all = [x_1, x_2]
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1))
return out
如此多的堆叠其实也对应了更密集的残差结构,残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
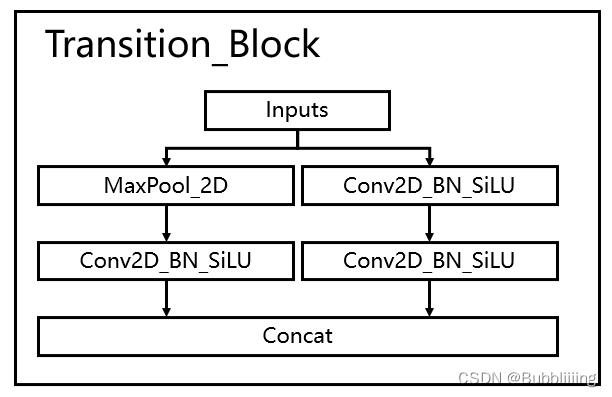
2、使用创新的过渡模块Transition_Block来进行下采样,在卷积神经网络中,常见的用于下采样的过渡模块是一个卷积核大小为3x3、步长为2x2的卷积或者一个步长为2x2的最大池化。在YoloV7中,作者将两种过渡模块进行了集合,一个过渡模块存在两个分支,如图所示。左分支是一个步长为2x2的最大池化+一个1x1卷积,右分支是一个1x1卷积+一个卷积核大小为3x3、步长为2x2的卷积,两个分支的结果在输出时会进行堆叠。
class MP(nn.Module):
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
class Transition_Block(nn.Module):
def __init__(self, c1, c2):
super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 2)
self.mp = MP()
def forward(self, x):
x_1 = self.mp(x)
x_1 = self.cv1(x_1)
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)
return torch.cat([x_2, x_1], 1)
整个主干实现代码为:
import torch
import torch.nn as nn
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=SiLU()): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act = nn.LeakyReLU(0.1, inplace=True) if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Multi_Concat_Block(nn.Module):
def __init__(self, c1, c2, c3, n=4, e=1, ids=[0]):
super(Multi_Concat_Block, self).__init__()
c_ = int(c2 * e)
self.ids = ids
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = nn.ModuleList(
[Conv(c_ if i ==0 else c2, c2, 3, 1) for i in range(n)]
)
self.cv4 = Conv(c_ * 2 + c2 * (len(ids) - 2), c3, 1, 1)
def forward(self, x):
x_1 = self.cv1(x)
x_2 = self.cv2(x)
x_all = [x_1, x_2]
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1))
return out
class MP(nn.Module):
def __init__(self, k=2):
super(MP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=k)
def forward(self, x):
return self.m(x)
class Transition_Block(nn.Module):
def __init__(self, c1, c2):
super(Transition_Block, self).__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.cv3 = Conv(c2, c2, 3, 2)
self.mp = MP()
def forward(self, x):
x_1 = self.mp(x)
x_1 = self.cv1(x_1)
x_2 = self.cv2(x)
x_2 = self.cv3(x_2)
return torch.cat([x_2, x_1], 1)
class Backbone(nn.Module):
def __init__(self, transition_channels, block_channels, n, phi, pretrained=False):
super().__init__()
#-----------------------------------------------#
# 输入图片是640, 640, 3
#-----------------------------------------------#
ids =
'l' : [-1, -3, -5, -6],
'x' : [-1, -3, -5, -7, -8],
[phi]
self.stem = nn.Sequential(
Conv(3, transition_channels, 3, 1),
Conv(transition_channels, transition_channels * 2, 3, 2),
Conv(transition_channels * 2, transition_channels * 2, 3, 1),
)
self.dark2 = nn.Sequential(
Conv(transition_channels * 2, transition_channels * 4, 3, 2),
Multi_Concat_Block(transition_channels * 4, block_channels * 2, transition_channels * 8, n=n, ids=ids),
)
self.dark3 = nn.Sequential(
Transition_Block(transition_channels * 8, transition_channels * 4),
Multi_Concat_Block(transition_channels * 8, block_channels * 4, transition_channels * 16, n=n, ids=ids),
)
self.dark4 = nn.Sequential(
Transition_Block(transition_channels * 16, transition_channels * 8),
Multi_Concat_Block(transition_channels * 16, block_channels * 8, transition_channels * 32, n=n, ids=ids),
)
self.dark5 = nn.Sequential(
Transition_Block(transition_channels * 32, transition_channels * 16),
Multi_Concat_Block(transition_channels * 32, block_channels * 8, transition_channels * 32, n=n, ids=ids),
)
if pretrained:
url =
"l" : 'https://github.com/bubbliiiing/yolov7-pytorch/releases/download/v1.0/yolov7_backbone_weights.pth',
"x" : 'https://github.com/bubbliiiing/yolov7-pytorch/releases/download/v1.0/yolov7_x_backbone_weights.pth',
[phi]
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", model_dir="./model_data")
self.load_state_dict(checkpoint, strict=False)
print("Load weights from " + url.split('/')[-1])
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
#-----------------------------------------------#
# dark3的输出为80, 80, 256,是一个有效特征层
#-----------------------------------------------#
x = self.dark3(x)
feat1 = x
#-----------------------------------------------#
# dark4的输出为40, 40, 512,是一个有效特征层
#-----------------------------------------------#
x = self.dark4(x)
feat2 = x
#-----------------------------------------------#
# dark5的输出为20, 20, 1024,是一个有效特征层
#-----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
2、构建FPN特征金字塔进行加强特征提取
在特征利用部分,YoloV7提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
在获得三个有效特征层后,我们利用这三个有效特征层进行FPN层的构建,构建方式为(在本博文中,将SPPCSPC结构归于FPN中):
- feat3=(20,20,1024)的特征层首先利用SPPCSPC进行特征提取,该结构可以提高YoloV7的感受野,获得P5。
- 对P5先进行1次1X1卷积调整通道,然后进行上采样UmSampling2d后与feat2=(40,40,512)进行一次卷积后的特征层进行结合,然后使用Multi_Concat_Block进行特征提取获得P4,此时获得的特征层为(40,40,512)。
- 对P4先进行1次1X1卷积调整通道,然后进行上采样UmSampling2d后与feat1=(80,80,256)进行一次卷积后的特征层进行结合,然后使用Multi_Concat_Block进行特征提取获得P3_out,此时获得的特征层为(80,80,256)。
- P3_out=(80,80,256)的特征层进行一次Transition_Block卷积进行下采样,下采样后与P4堆叠,然后使用Multi_Concat_Block进行特征提取P4_out,此时获得的特征层为(40,40,512)。
- P4_out=(40,40,512)的特征层进行一次Transition_Block卷积进行下采样,下采样后与P5堆叠,然后使用Multi_Concat_Block进行特征提取P5_out,此时获得的特征层为(20,20,1024)。
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
#---------------------------------------------------#
# yolo_body
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, phi, pretrained=False):
super(YoloBody, self).__init__()
#-----------------------------------------------#
# 定义了不同yolov7版本的参数
#-----------------------------------------------#
transition_channels = 'l' : 32, 'x' : 40[phi]
block_channels = 32
panet_channels = 'l' : 32, 'x' : 64[phi]
e = 'l' : 2, 'x' : 1[phi]
n = 'l' : 4, 'x' : 6[phi]
ids = 'l' : [-1, -2, -3, -4, -5, -6], 'x' : [-1, -3, -5, -7, -8][phi]
conv = 'l' : RepConv, 'x' : Conv[phi]
#-----------------------------------------------#
# 输入图片是640, 640, 3
#-----------------------------------------------#
#---------------------------------------------------#
# 生成主干模型
# 获得三个有效特征层,他们的shape分别是:
# 80, 80, 512
# 40, 40, 1024
# 20, 20, 1024
#---------------------------------------------------#
self.backbone = Backbone(transition_channels, block_channels, n, phi, pretrained=pretrained)
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
self.sppcspc = SPPCSPC(transition_channels * 32, transition_channels * 16)
self.conv_for_P5 = Conv(transition_channels * 16, transition_channels * 8以上是关于睿智的目标检测60——Pytorch搭建YoloV7目标检测平台的主要内容,如果未能解决你的问题,请参考以下文章