大数据繁荣生态圈组件之实时大数据Druid小传
Posted Maynor学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据繁荣生态圈组件之实时大数据Druid小传相关的知识,希望对你有一定的参考价值。
文章目录
Druid小传
RDBMS劣势
项目中采用的关系型数据库是mysql,那么关系型数据库有哪些优劣势,我们可以参考下面的分析:
关系型数据库的优点:
1.基于ACID,支持事务,适合于对安全性和一致性要求高的的数据访问
2.可以进行Join等复杂查询,处理复杂业务逻辑,比如:报表
3.使用方便,通用的SQL语言使得操作关系型数据库非常方便
关系型数据库的劣势:
1.不擅长大量数据的写入处理
2.每个字段都会占用一定的磁盘空间,不具有稀疏性
3.高并发下性能、吞吐量较低
4.扩展性不如非关系型数据库方便
根据上面的总结,随着每日增量数据的累加,短期来看mysql数据库是能够承载一定程度的数据量的,但是长期来看,mysql数据库将不堪重负。因此,我们需要寻找mysql数据库的替代方案,这里我们选择了apache druid实时数据库。
Druid简述
基于 Hadoop 的大数据平台,有如下一些问题:
(1)无法保障查询性能
对于Hadoop使用的MapReduce批处理框架,数据何时能够查询没有性能保证
(2)随机IO问题
HDFS以集群硬盘作为存储资源池的分布式文件系统;
在海量数据的处理过程中,会引起大量的读写操作,随机IO是高并发场景下的性能瓶颈
(3)数据查询效率问题
HDFS对于数据分析以及数据的即席查询,HDFS并不是最优的选择。
传统的Hadoop大数据处理架构更倾向于一种“后台批处理的数据仓库系统”,其作为海量历史数据保存、冷数据分析,确实是一个优秀的通用解决方案,但问题主要体现为:
1.无法保证高并发环境下海量数据的查询分析性能
2.无法实现海量实时数据的查询分析与可视化
Druid的介绍
Druid是由一个名为 MetaMarket 的公司开发的;2011年,MetaMarket 开始研发自己的"轮子"Druid,将Druid定义为“开源、分布式、面向列式存储的实时分析数据存储系统”。
要解决的"痛点"是:
1.在高并发环境下,保证海量数据查询分析性能
2.同时提供海量实时数据的查询、分析与可视化功能
Druid是面向海量数据的、用于实时查询与分析的OLAP存储系统。Druid的关键特性如下:
1.亚秒级的OLAP查询分析
采用了列式存储、倒排索引、位图索引等关键技术
2.在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作
3.实时流数据分析
传统分析型数据库采用的批量导入数据,进行分析的方式
Druid提供了实时流数据分析,以及高效实时写入
4.实时数据在亚秒级内的可视化
5.丰富的数据分析功能
Druid提供了友好的可视化界面
6.SQL查询语言
REST查询接口
7.高可用性与高可拓展性
Druid工作节点功能单一,不相互依赖
Druid集群在管理、容错、灾备、扩容都很容易
注意:阿里巴巴也曾创建过一个开源项目叫 Druid (简称阿里 Druid),它是一个数据库连接池项目。阿里 Druid 和 我们要讨论的
Druid 没有任何关系,它们解决完全不同的问题
Druid的典型应用架构
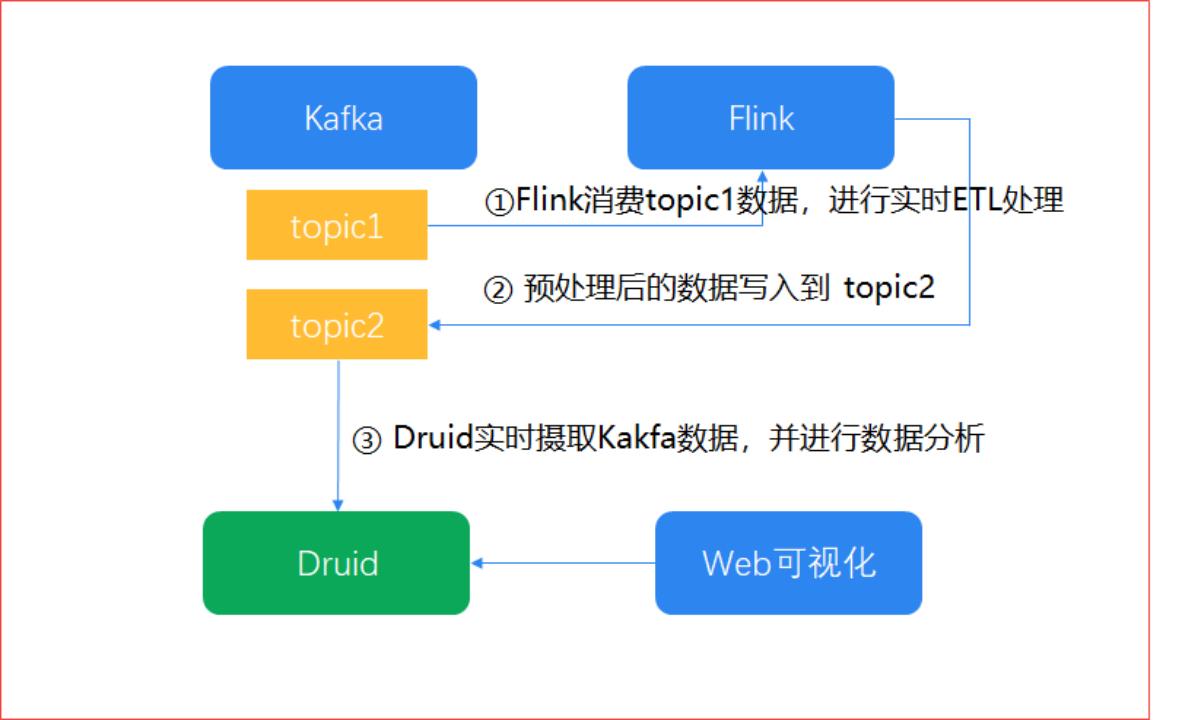
国内哪些公司在使用Druid
1.腾讯
腾讯企点采用Druid用于分析大量的用户行为,帮助提升客户价值
2.阿里巴巴
阿里搜索组使用Druid的实时分析功能用于获取用户交互行为
3.新浪微博
新浪广告团队使用Druid构建数据洞察系统的实时分析部分,每天处理数十亿的消息
4.小米
Druid用于小米统计的后台数据收集和分析
也用于广告平台的数据分析
5.滴滴打车
Druid是滴滴实时大数据处理的核心模块,用于滴滴实时监控系统,支持数百个关键业务指标
通过Druid,滴滴能够快速得到各种实时的数据洞察
6.优酷土豆
Druid用于其广告的数据处理和分析
Druid 对比其他OLAP
Druid vs. Elasticsearch
Druid在导入过程会对原始数据进行Rollup,而ES会保存原始数据
Druid专注于OLAP,针对数据导入以及快速聚合操作做了优化
Druid不支持全文检索
Druid vs. Key/Value Stores (HBase/Cassandra/OpenTSDB)
Druid采用列式存储,使用倒排和bitmap索引,可以做到快速扫描相应的列
Druid vs. Spark
Spark SQL的响应还不做到亚秒
Druid可以做到超低的响应时间,例如亚秒,而且高并发面向用户的应用。
Druid vs SQL-on-Hadoop (Impala/Drill/Spark SQL/Presto)
Driud查询速度更快
数据导入,Druid支持实时导入,SQL-on-Hadoop一般将数据存储在Hdfs上,Hdfs的写入速度有可能成为瓶颈
SQL支持,Druid也支持SQL,但Druid不支持Join操作
Druid vs. Kylin
Kylin不支持实时查询,Druid支持
Kylin支持表连接(Join),Druid不支持
以上是关于大数据繁荣生态圈组件之实时大数据Druid小传的主要内容,如果未能解决你的问题,请参考以下文章