大数据入门基础系列之初步认识大数据生态系统圈(博主推荐)
Posted 好记性不如烂笔头!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据入门基础系列之初步认识大数据生态系统圈(博主推荐)相关的知识,希望对你有一定的参考价值。
之前在微信公众平台里写过
大数据入门基础系列之初步认识hadoop生态系统圈
http://mp.weixin.qq.com/s/KE09U5AbFnEdwht44FGrOA
大数据入门基础系列之初步认识大数据生态系统圈
1.概述
最近收到一些同学和朋友的邮件,说能不能整理一下 Hadoop 生态圈的相关内容,然后分享一些,我觉得这是一个不错的提议,于是,花了一些业余时间整理了 Hadoop 的生态系统,并将其进行了归纳总结,进而将其以表格的形式进行了罗列。涉及的内容有以下几点:
- 分布式文件系统
- 分布式编程模型
- NoSQL 数据库
- SQL-On-Hadoop
- 数据采集
- 编程服务中间件
- 调度系统
- 系统部署
- 数据可视化
2.内容
2.1 分布式文件系统
2.1.1 Apache HDFS
在分布式文件系统当中,首先为大家所熟悉的是 Apache 的 HDFS。全称为 Hadoop Distributed File System,由多台机器组建的集群,存储大数据文件。HDFS 的灵感来自于 Google File System(GFS)。Hadoop 2.x 版本之前,NameNode 是存在单点故障的。在 ZooKeeper 的高可用性功能解决了 HDFS 的这个问题,通过提供运行两个冗余的节点在同一个集群中进行主备切换,即:Active & Standby
相关链接地址如下所示:
2.1.2 Red Hat GlusterFS
GlusterFS 是一个扩展的网络附加存储文件系统。GlusterFS 最初是由 Gluster 公司开发的,然后,由 Red Hat 公司在2011年进行了购买。2012年六月,Red Hat 存储服务器被宣布为商业支持的整合与 Red Hat 企业 Linux GlusterFS。Gluster 文件系统,现在称为 Red Hat 存储服务器。
相关链接地址如下所示:
2.1.3 QFS
QFS 是一个开源的分布式文件系统软件包,用于对 MapReduce 批处理工作负载。她被设计为一种 Apache Hadoop 的 HDFS 另一种选择方案,用于大型加工集群提供更好的性能和成本效率。它用 C++ 和固定占用内存管理。QFS 使用 Reed-Solomon 纠错保证可靠的数据访问方法。Reed-Solomon 编码在海量存储系统中被广泛应用,以纠正与媒体缺陷相关的突发错误。而不是存储每个文件或是像 HDFS 一样,存储 3+ 次以上,QFS 仅仅需要 1.5 倍的原始容量,因为它存储在哎九个不同的磁盘驱动上。
相关链接地址如下所示:
2.1.4 Ceph Filesystem
Ceph 是一个免费的软件存储平台,被设计为对象,块和从单一节点到集群的文件存储。它的主要目标是完全分布式无单点鼓掌,可水平扩展到 PB 容量,对多种工作负载的高性能,以及高可用性。
相关链接地址如下所示:
2.1.5 Lustre file system
Lustre 是由 Linux 和 Cluster 演变而来,是为了解决海量存储问题而设计的全新的文件系统。可支持达 1w 节点,PB 的存储容量,100GB/S 的传输速度。Lustre 是基于对象的存储系统,减少元数据服务器的 iNode。它实际上还是将数据条带化到各个存储目标上,所以可以实现高度聚合 IO 能力。Lustre 原生态支持海量小文件读写;且对大文件读写在 Linux 内核做了特殊优化。另外,Lustre 是个对用户透明的 Share 文件系统,条带化数据的位置信息不能完美的暴露出来,所以要用上 Hadoop 的 MapReduce 优势还需要做很多工作。
相关链接地址如下所示:
关于分布式文件系统的内容就赘述到这里;其它分布式文件系统,如:Alluxio,GridGain 以及 XtreemFS[1.官网,2.Flink on XtreemFS,3.Spark XtreemFS] 等这里就不多赘述了,大家可以下去自己普及一下。
2.2 分布式编程模型
2.2.1 Apache Ignite
Apache Ignite 内存数组组织框架是一个高性能、集成和分布式的内存计算和事务平台,用于大规模的数据集处理,比传统的基于磁盘或闪存的技术具有更高的性能,同时他还为应用和不同的数据源之间提供高性能、分布式内存中数据组织管理的功能。
它包含一个分布式的 Key/Value 存储在内存中,SQL 执行能力,MapReduce 和其它计算,分布式数据结构,连续查询,消息和事件子系统。Hadoop 和 Spark 均有集成。Ignite 编译于 Java,提供 .NET 和 C++ 的 API 接口。
相关链接地址如下所示:
2.2.2 Apache MapReduce
这个大家应该不陌生,这是一个经典的编程模型,用于在集群上处理并发,分布式大数据集。当前版本编译于 YARN 框架。这里就不多赘述了。
相关链接地址,如下所示:
2.2.3 Apache Spark
这个编程模型,大家也不会陌生,现在 Spark 的应用场景和社区活跃度较高。快速的执行能力,丰富的编程 API 接口,使其备受恩宠。
相关链接地址,如下所示:
2.2.4 Apache Storm
做实时流水数据处理的同学,应该也不陌生,可以嫁接多种消息中间件(如Kafka,MQ等)。
相关链接地址,如下所示:
2.2.5 Apache Flink
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。 Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
相关链接地址,如下所示:
这里列举了热度较高的分布式编程模型,其它的编程模型,如下表所示:
| 分布式编程模型 | 相关链接地址 |
| Apache Pig | |
| JAQL | |
| Facebook Corona | 1.Corona on Github |
| Apache Twill | 1.Twill 官网 |
| Apache Tez |
2.3 NoSQL 数据库
2.3.1 列数据模型
2.3.1.1 Apache HBase
灵感来自于 Google 的 BigTable。非关系性分布式数据库。随机实时读写操作列扩展的大表。
相关链接地址,如下所示:
2.3.1.2 Apache Cassandra
Apache Cassandra 是一套开源分布式 Key-Value 存储系统。它最初由 Facebook 开发,用于储存特别大的数据。 Cassandra 不是一个数据库,它是一个混合型的非关系的数据库,类似于 Google 的 BigTable。Cassandra 的数据模型是基于列族(Column Family)的四维或五维模型。它借鉴了 Amazon 的 Dynamo 和 Google\'s BigTable 的数据结构和功能特点,采用 Memtable 和 SSTable 的方式进行存储。在 Cassandra 写入数据之前,需要先记录日志 ( CommitLog ),然后数据开始写入到 Column Family 对应的 Memtable 中,Memtable 是一种按照 key 排序数据的内存结构,在满足一定条件时,再把 Memtable 的数据批量的刷新到磁盘上,存储为 SSTable 。
相关链接地址,如下所示:
2.3.1.3 Apache Kudu
Kudu 是 Cloudera 开源的列式存储引擎,具有一下几个特点:
- C++ 语言开发
- 高效处理类 OLAP 负载
- 与 MR,Spark 以及 Hadoop 生态系统中其它组件友好集成
- 可以与 Cloudera Impala 集成
- 灵活的一致性模型
- 顺序和随机写并存的场景下,仍能达到良好的性能
- 高可用,使用 Raft 协议保证数据高可靠存储
- 结构化数据模型
相关链接地址,如下所示:
2.3.2 文档数据模型
2.3.2.1 MongoDB
面向文档的数据库系统。它是数据库系统中 NoSQL 家族的一部分。MongoDB 存储结构化数据以 JSON 格式的文件形式进行存储。
相关链接地址,如下所示:
2.3.3 Key-Value 数据模型
2.3.3.1 Redis 数据库
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
相关链接地址,如下所示:
2.4 SQL-On-Hadoop
2.4.1 Apache Hive
一款由 Facebook 开发的数据仓库。数据聚合,查询和分析。提供类 SQL 语言:HiveQL
相关链接地址,如下所示:
2.4.2 Apache Trafodion
Trafodion是一个构建在Hadoop/HBase基础之上的关系型数据库,它完全开源免费。Trafodion能够完整地支持ANSI SQL,并且提供ACID事务保证。和传统关系数据库不同的地方在于,Trafodion利用底层Hadoop的横向扩展能力,可以提供极高的扩展性。而传统数据库,比如mysql,在数据量达到P级别的时候就很难处理。而Trafodion却可以借助HBase的扩展性,仅通过增加普通Linux服务器就可以增加计算和存储能力,进而支持大数据应用。
相关链接地址,如下所示:
2.4.3 Apache Drill
Drill 是 Apache 开源的,用于大数据探索的 SQL 查询引擎。她在大数据应用中,面对结构化数据和变化迅速的数据,她能够去兼容,并且高性能的去分析,同时,还提供业界都熟悉的标准的查询语言,即:ANSI SQL 生态系统。Drill 提供即插即用,在现有的 Hive,HBase,S3 等存储介质中可以随时整合部署。
相关链接地址,如下所示:
2.4.4 Cloudera Impala
类似于 Drill 的一款大数据实时查询引擎,依赖 CDH 环境。
相关链接地址,如下所示:
2.4.5 Apache Kylin
Kylin 是一款开源的分布式数据分析引擎由 eBay 公司提供。支持 Hadoop 大数据集 OLAP 业务/
相关链接地址,如下所示:
另外,还有[Apache Tajo],[Apache Phoenix] 等,这里就不一一列举了。
2.5 数据采集
2.5.1 Apache Flume
Flume 是一个分布式,可靠的,可用的服务,有效的收集,聚合和移动海量的日志数据。它有一个简单而灵活的架构,基于流数据流。具有很好的冗余和容错性,以及可靠性和多故障转移和恢复机制。它使用一个简单的可扩展数据模型,并允许在线分析应用。
相关链接地址,如下所示:
2.5.2 Apache Sqoop
一款从 HDFS 到 RDBMS 之间做数据交互的工具。类似于 Flume。
相关链接地址,如下所示:
2.5.3 Apache Kafka
分布式发布-订阅消息系统,用于处理流式海量数据。Kafka 是一个由 LinkedIn 开发的消息队列。能嫁接 HDFS 这样的存储介质,能被 Storm,Spark这类实时或类实时数据模型消费。
相关链接地址,如下所示:
2.5.4 Apache NiFi
Apache NiFi 是由美国国家安全局(NSA)贡献给 Apache 基金会的开源项目,目前已被顺利孵化完成成为 Apache 的顶级项目之一。Apache NiFi 其设计目标是自动化系统间的数据流。基于其工作流式的编程理念,NiFi 拥有易使用,高可用以及高配置等特性。其尤为突出的两大特性是:强大的用户界面和良好的数据回溯工具。NiFi 的用户界面允许用户在浏览器中直观的理解并与数据流进行交互,快速和安全的进迭代。其数据回溯特性允许用户查看一个对象如何在系统间流转,回放以及可视化关键步骤之前以及之后发生的情况,包括大量复杂的图式转换,Fork,Join 以及其它操作等。另外,NiFi 使用基于组件的扩展模型用以为复杂的数据流快速增加功能,开箱即用的组件中,处理文件系统的包括 FTP,SFTP 以及 HTTP 等,同样也支持 HDFS。
相关链接地址,如下所示:
另外,还有 Facebook Scribe,Apache Chukwa,Netflix Suro,Apache Samza,Cloudera Morphline,HIHO 等套件就不一一介绍了,大家可以下去了解这些数据采集套件相关内容。
2.6 编程服务中间件
2.6.1 Apache Thrift
Thrift 是一个软件框架,用来进行可扩展且跨语言的服务开发。它结合了功能强大的软件堆栈和代码生成引擎,用以构建在 C++,Java,Python,Ruby 等编程语言上,进行无缝,高效的衔接。其最初由 Facebook 开发用做系统内各个语言之间的 RPC 通信,后 Facebook 贡献给 Apache,目前成为 Apache 的顶级项目之一。
相关链接地址,如下所示:
2.6.2 Apache Zookeeper
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务,状态同步服务,集群管理,分布式应用配置项的管理等。
相关链接地址,如下所示:
2.6.3 Apache Avro
Apache Avro 是 Hadoop 中的一个子项目,也是 Apache 中的一个独立的项目,Avro 是一个基于二进制数据传输高性能的中间件。在 Hadoop 的其它项目中,例如 HBase,Hive 的 Client 端与服务端的数据传输也采用了这个工具。Avro 是一个数据序列化的系统,它可以将数据结构或对象转化成便于存储或传输的格式。Avro 设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。拥有一下特点:
- 丰富的数据结构类型
- 快速可压缩的二进制数据形式,对数据二进制序列化后可以节约数据存储空间和网络传输带宽
- 存储持久数据的文件容器
- 可以实现远程过程调用 RPC
- 简单的动态语言结合功能
相关链接地址,如下所示:
另外,还有 Apache Curator,Twitter Elephant Bird,Linkedin Norbert 等工具,这里就不一一介绍了。
2.7 调度系统
2.7.1 Apache Oozie
在 Hadoop 中执行的任务有时候需要把多个 MR 作业连接到一起,这样才能达到目的。在 Hadoop 生态圈中,Oozie 可以把多个 MR 作业组合到一个逻辑工作单元中,从而完成更大型的任务。Oozie 是一种 Java Web 应用程序,它运行在 Java Servlet 容器中(即:Tomcat)中,并使用数据库来存储一下内容:
- 工作流定义
- 当前运行的工作流实例,包括实例的状态和变量
Oozie 工作流是放置在控制依赖 DAG 中的一组动作(如 Hadoop 的 MR 作业,Pig 作业等),其中指定了动作执行的顺序。
相关链接地址,如下所示:
2.7.2 Linkedin Azkaban
Hadoop 工作流管理。提供友好的 Web UI 界面进行批处理作业调度(定时或及时)。
相关链接地址,如下所示:
2.7.3 Apache Falcon
Apache Falcon 是一个面向 Hadoop 的,新的数据处理和管理平台,设计用于数据移动,数据管道协调,生命周期管理和数据发现。它使用终端用户可以快速的将他们的数据以及相关的处理和管理任务上载到 Hadoop 集群。在 Apache Falcon 中,基础设施端点,数据集,处理规则均是声明式的。这种声明式配置显式定义了实体之间的依赖关系。这也是该平台的一个特点,它本身只维护依赖关系,而并不做任何繁重的工作,所有的功能和工作流状态管理需求都委托给工作流调度程序来完成。
相关链接地址,如下所示:
2.8 系统部署
2.8.1 Apache Ambari
用于创建,管理,监控 Hadoop 集群的工具,可以很方便的安装,调试 Hadoop 集群,支持的平台组件也是越来越多,如 Spark,Storm 等计算模型,以及资源调度平台 YARN 等,都能通过 Ambari 轻松部署管理。
相关链接地址,如下所示:
2.8.2 CDH
Cloudera 公司的产品,类似于 Ambari 产品,用于创建,管理,监控 Hadoop 集群。
相关链接地址,如下所示:
2.9 可视化
2.9.1 Apache Zeppelin
你可以制作出漂亮的数据,使用 SQL,Scala 或者其它。它拥有以下特性:
- 数据收集
- 数据发掘
- 数据分析
- 数据可视化和集成
目前支持的中间件有:Spark,md,sh,Hive,Tajo,Flink,Cassandra,Phoenix,Kylin 等
相关链接地址,如下所示:
3.总结
Hadoop 生态圈是非常庞大的,上述列举的只是其生态圈中常用的一部分,下图给大家展示了本篇博客相关内容的关联图,如下图所示:
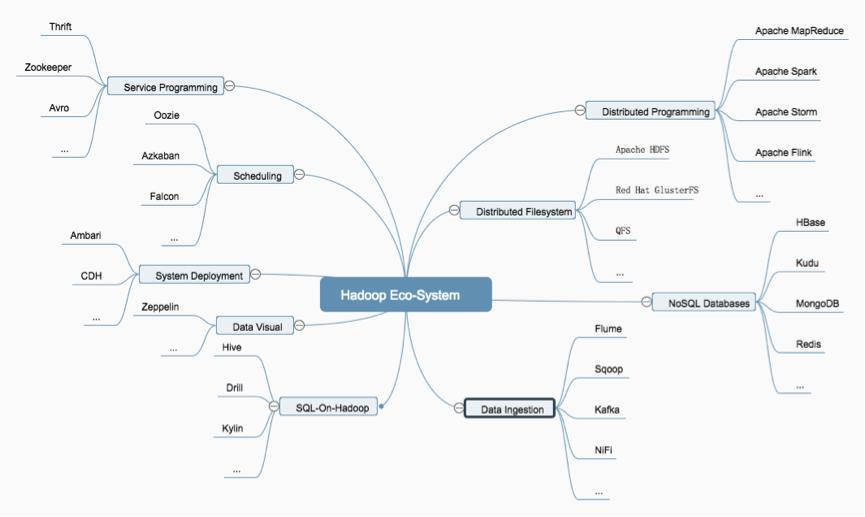
4.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
以上是关于大数据入门基础系列之初步认识大数据生态系统圈(博主推荐)的主要内容,如果未能解决你的问题,请参考以下文章
大数据开发基础入门与项目实战Hadoop核心及生态圈技术栈之1.Hadoop简介及Apache Hadoop完全分布式集群搭建
原创 | 大数据入门基础系列之ZooKeeper如何实现分布式锁