智谷大数据伴您学系列之十二——HBase
Posted 沈阳智谷大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智谷大数据伴您学系列之十二——HBase相关的知识,希望对你有一定的参考价值。
Hadoop是入门大数据技术的基础之一,想要学习大数据,Hadoop是必须要了解的。想要了解Hadoop,就得了解Hadoop的生态系统,而Hadoop生态体系中很重要的一个部分是HBase。这篇文章为你介绍的就是Hadoop的分布式数据库HBase的相关知识。
HBase的定义及特点
HBase是建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。它介于NoSQL和RDBMS之间,仅能通过行键(row key)和行键序列来检索数据,仅支持单行事务。主要用来存储非结构化和半结构化的松散数据。与Hadoop一样,HBase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase表的特点
大:一个表可以有上亿行,上百万列。
面向列:面向列(族)的存储和权限控制,列(族)独立检索。
稀疏:对于为空(null)的列,并不占用存储空间。因此,表可以设计的非常稀疏。
HBase的体系架构
HBase的服务器体系结构遵循简单的主从服务器架构。它由HRegion Server和HMaster组成,HMaster负责管理所有的HRegion Server,HBase中所有的服务器都通过ZooKeeper来协调。HBase的体系结构如下图所示:
Client
HBase Client使用RPC与HMaster和HRegionServer通信。对于管理类操作,Client与HMaster通信,对于数据读写类操作,与HRegionServer通信。Client访问HBase上数据的过程并不需要HMaster参与(寻址访问Zookeeper和HRegion Server,数据读写访问HRegion Server),HMaster仅仅维护表和HRegion的元数据信息,负载很低。
HMaster
为HRegion Server分配HRegion。
负责HRegion Server的负载均衡。
发现失效的HRegion Server并重新分配其上的HRegion。
处理元数据更新请求。
HRegion Server
HRegion Server维护HMaster分配给它的HRegion,处理对这些HRegion的I/O请求。
HRegion Server负责切分在运行过程中变得过大的HRegion。
ZooKeeper
保证任何时候,集群中只有一个HMaster。
存储所有HRegion的寻址入口。
实时监控HRegion Server的状态,将HRegion Server的上线和下线信息实时通知给HMaster。
HBase Shell
HBase Shell 提供了大量的 HBase 命令,通过HBase Shell 用户可以方便地创建、删除及修改表,还可以向表中添加数据、列出表中的相关信息等。
HBase的主要模型
逻辑模型:Hbase的名字的来源是Hadoopdatabase,即hadoop数据库。主要是从用户角度来考虑,即如何使用Hbase。
物理模型:主要从实现Hbase的角度来讨论。
HBase的访问接口
Native Java API.最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据。
HBase Shell.HBase的命令行工具,最简单的接口,适合HBase管理使用。
Thrift Gateway.利用Thrift序列化技术,支持C++,php,Python等多种语言,适合其他异构系统在线访问HBase表数据。
REST Gateway.支持REST 风格的Http API访问HBase, 解除了语言限制。
Pig.可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计。
Hive.当前Hive的Release版本尚没有加入对HBase的支持,但在下一个版本Hive 0.7.0中将会支持HBase,可以使用类似SQL语言来访问HBase。
HBase架构之美
LSM
解决磁盘随机写问题(顺序写才是王道),采用LSM树(Log-Structured Merge Tree)作为存储引擎,支持增、删、读、改、顺序扫描。将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
HFile
解决数据索引问题(只有索引才能高效读)。
WAL
解决数据持久化(面对故障的持久化解决方案)。
ZooKeeper
解决核心数据的一致性和集群恢复。
HDFS
使用HDFS存储,解决数据副本和可靠性问题。
HBase表的逻辑视图
HBase以表的形式存储数据。表由行和列组成,列划分为若干个列族(column family)。HBase表逻辑结构如下图所示:
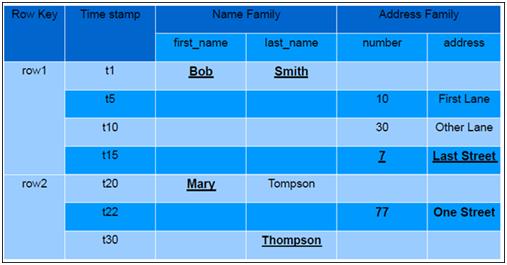
行键
与NoSQL数据库一样,行键(row key)是用来检索记录的主键。行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100Bytes),在HBase内部,行键保存为字节数组。
访问HBase表中行的三种方式
通过单个行键访问
通过行键序列访问
全表扫描
存储时,数据按照行键的字典序排序存储。设计行键时,可以充分利用排序存储这个特性,将经常一起读取的行存储放到一起。
列族
HBase表中的每个列,都归属某个列族。列族是表元数据的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history , courses:math 都属于 courses这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因为隐私的原因不能浏览所有数据)。
时间戳
HBase中通过行键和列确定的一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBase (在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
单元
由{row key, column( =<family> + <label>), version} 唯一确定的单元(cell)。cell中的数据是没有类型的,全部是字节码形式存储。
HBase的存储格式
HBase中的所有数据文件都存储在Hadoop HDFS文件系统上,主要包括上述提出的两种文件类型:1. HFile, HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile;2. HLog File,HBase中WAL(Write Ahead Log) 的存储格式,物理上是Hadoop的Sequence File。
HFile
HFile文件长度不定,只有Trailer和FileInfo两块长度固定。正如图中所示的,Trailer的指针指向其他数据块的起始点。File Info负责记录文件的Meta信息,例如:LAST_KEY,COMPARATOR,AVG_KEY_LEN,AVG_VALUE_LEN等。每个Data块和Meta块的起始点则分别由Data Index和Meta Index负责记录。
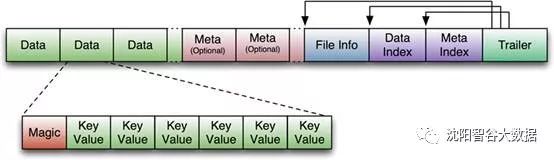
Data Block是HBase I/O的基本单元,通过Block Cache机制提升效率。每个Data块的大小可以在创建一个Table的时候通过参数指定,大的Block有利于顺序Scan,小的Block利于随机查询。每个Data块除了开头的Magic以外就是各个Key-Value对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。
HFile中的每个Key-Value对就是一个简单的byte数组。但这个byte数组包含了很多项信息,并含有固定的结构。

开始是两个长度固定的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分则相对简单,是纯粹的二进制数据。
HLogFile
HLog是WAL(Write Ahead Log)的存储格式,即Hadoop的Sequence File。
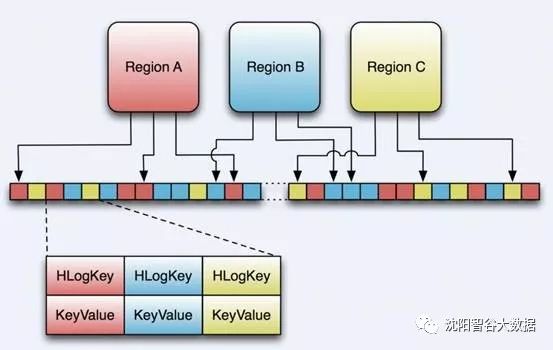
HLog文件的结构就是一个普通的Hadoop Sequence File。Sequence File的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog Sequece File的Value是HBase的Key-Value对象,即对应HFile中的Key-Value。
HBase发源于Google BigTable,在底层存储机制层面,虽然与BigTable有所不同,但其文件系统和存储格式的核心依然基于Hadoop HDFS文件系统。
智谷大数据将为大家带来一系列相关大数据的资讯,想要继续学习大数据相关知识的朋友们,请持续关注沈阳智谷大数据官微。
·END·
SY-KVDT
沈阳智谷大数据发展有限公司
塑造新兴人才
助力大数据产业发展
以上是关于智谷大数据伴您学系列之十二——HBase的主要内容,如果未能解决你的问题,请参考以下文章