大数据繁荣生态圈组件之实时大数据Druid小传Druid架构与原理
Posted Maynor学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据繁荣生态圈组件之实时大数据Druid小传Druid架构与原理相关的知识,希望对你有一定的参考价值。
文章目录
Druid架构与原理
1. Druid系统架构详解
Druid有5种节点:
1.Overlord
2.MiddleManager
3.Coordinator
4.Historical
5.Broker
以下是这几个节点的主要功能:
1.Overlord、MiddleManager
负责处理索引任务
Overlord是MiddleManager的master节点
2.Coordinator、Historical
负责管理分发Segment
Coordinator是Historical的master节点
3.Broker
负责接收Client查询请求
拆分子查询给MiddleManager和Historical节点
合并查询结果返回给Client
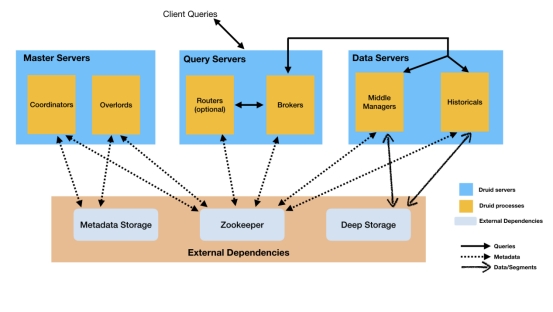
索引服务
索引服务是数据摄入创建和销毁Segment的重要方式,Druid提供一组支持索引服务(Indexing Service)的组件,即Overlord和MiddleManager节点。
索引服务采用的是主从架构,Overlord为主节点,MiddleManager是从节点
索引服务架构图如下图所示:
索引服务由三部分组件组成:
Overlord组件 :分配任务给MiddleManager
MiddleManager组件 :用于管理Peon的
Peon组件 :用于执行任务
部署:
1.MiddleManager和Overlord组件可以部署在相同节点也可以跨节点部署
2.Peon和MiddleManager是部署在同一个节点上的
索引服务架构和Yarn的架构很像:
Overlaod => ResourceManager,负责集群资源管理和任务分配
MiddleManager => NodeManager,负责接受任务和管理本节点的资源
Peon => Container,执行节点上具体的任务
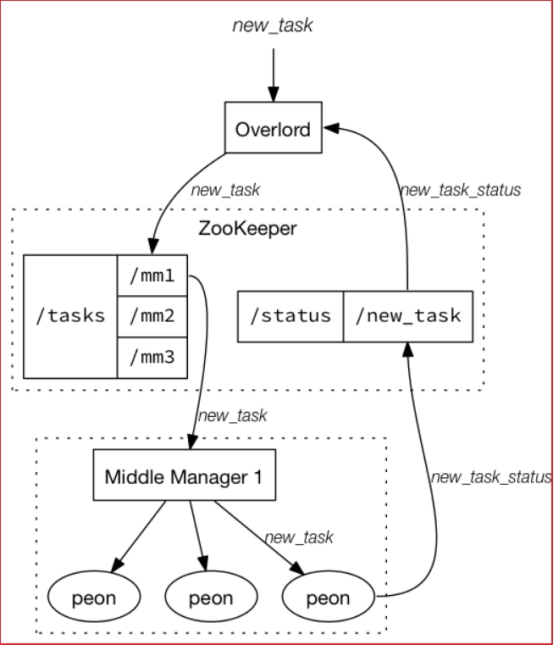
1.2. Overlord节点
Overlord是索引服务的主节点,对外负责接受索引任务,对内负责将任务分解并下发给MiddleManager
Overlord有两种运行模式:
- 本地模式(Local Mode):默认模式
本地模式下的Overlord不仅负责任务协调工作,还会负责启动一些peon来完成具体的任务。
- 远程模式(Remote Mode)
该模式下,Overlord和MiddleManager运行在不同的节点上,它仅负责任务的协调工作,不负责完成具体的任务。
3.UI客户端
Overlord提供了一个UI客户端,可以用于查看任务、运行任务和终止任务等
UI访问地址:http://node01:8090/console.html
Overlord提供了RESETful的访问形式,所以客户端可以通过HTTP POST形式向请求节点提交任务:
提交任务 : http://node01:8090/druid/indexer/v1/task
杀死任务 : http://node01:8090/druid/indexer/v1/task/task_id/shutdown
1.3. MiddleManager节点
MiddleManager是执行任务的工作节点
MiddleManager会将任务单独发给每个单独JVM运行的Peon
每个Peon一次只能运行一个任务
1.4. Coordinator节点
Coordinator是Historical的mater节点,主要负责管理和分发Segment
具体工作就是:
1.告知Historical加载或删除Segment
2.管理Segment副本以及负载Segment在Historical上的均衡
Coordinator是定期运行的,通过Zookeeper获取当前集群状态,通过评估集群状态来进行均衡负载Segment。
Coordinator连接数据库(MetaStore),获取Segment信息和规则(Rule),Coordinator根据数据库中表的数据来进行集群 segment 管理
Coordinator提供了一UI界面,用于显示集群信息和规则配置:http://node1:8081/index.html#/
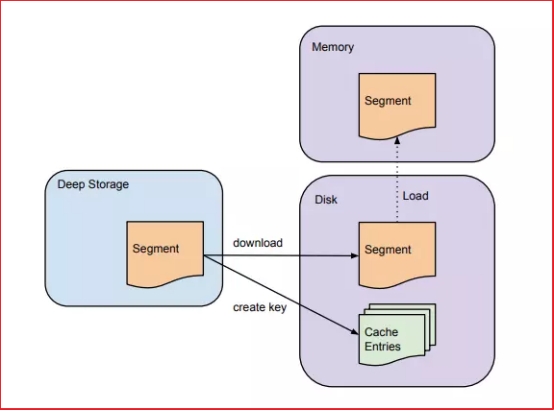
1.5. Historical节点
1.Historical节点负责管理历史Segment
2.Historical节点通过Zookeeper监听指定的路径来发现是否有新的Segment需要加载
3.Historical节点收到有新的Segment时候,就会检测本地cache和磁盘,查看是否有该Segment信息。如果没有Historical节点会从Zookeeper中拉取该Segment相关的信息,然后进行下载
1.6. Broker节点
Broker节点负责转发Client查询请求的
Broker通过zookeeper能够知道哪个Segment在哪些节点上,将查询转发给相应节点
所有节点返回数据后,Broker会将所有节点的数据进行合并,然后返回给Client
2. Druid数据存储
Druid提供对大数据集的实时摄入和高效复杂查询的性能,主要原因:基于Datasource与Segment的数据存储结构
2.1. 数据存储
1.Druid中的数据存储在被称为DataSource中,DataSource类似RDMS中的table
2.每个DataSource按照时间划分,每个时间范围称为一个chunk((比如按天分区,则一个chunk为一天))。
3.在chunk中数据被分为一个或多个segment;
4.segment是数据实际存储结构,Datasource、Chunk只是一个逻辑概念;
每个segment都是一个单独的文件,通常包含几百万行数据;
segment是按照时间组织成的chunk,所以在按照时间查询数据时,效率非常高。
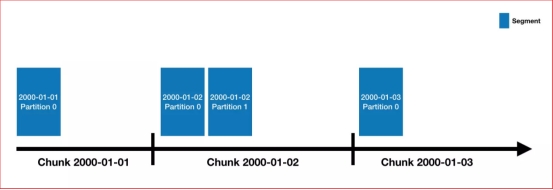
2.2. 数据分区
Druid处理的是事件数据,每条数据都会带有一个时间戳,可以使用时间进行分区,上图指定了分区粒度为天,那么每天的数据都会被单独存储和查询。
2.3. Segment
Segment是数据存储、复制、均衡和计算的基本单元
Segment具备不可变性,一个Segment一旦创建完成后(MiddleManager节点发布后)就无法被修改
只能通过生成一个新的Segment来代替旧版本的Segment
2.4. Segment内部存储结构
Druid采用列式存储,每列数据都是在独立的结构中存储
Segment中的数据类型主要分为三种:
1.时间戳
2.维度列
3.指标列

1.时间戳列和指标列
Druid采用LZ4压缩每列的整数或浮点数
收到查询请求后,会拉出所需的行数据(对于不需要的列不会拉出来),并且对其进行解压缩。
2.维度列
维度列需要支持filter和group by
Druid使用了字典编码(Dictionary Encoding)和位图索引(Bitmap Index)来存储每个维度列。
每个维度列需要三个数据结构:
1.需要一个字典数据结构,将维度值映射成一个整数ID
2.使用上面的字典编码,将该列所有维度值放在一个列表中
3.对于列中不同的值,使用bitmap数据结构标识哪些行包含这些值。
Druid针对维度列之所以使用这三个数据结构,是因为:
1.使用字典将字符串映射成整数ID,可以紧凑的表示维度数据
2.使用Bitmap位图索引可以执行快速过滤操作
- 找到符合条件的行号,以减少读取的数据量
- Bitmap可以快速执行AND和OR操作
3. roll-up聚合
1.Druid通过一个roll-up的处理,将原始数据在注入的时候就进行汇总处理;
2.roll-up可以压缩我们需要保存的数据量;
3.Druid会把选定的相同维度的数据进行聚合操作,可减少存储的大小;
4.Druid可以通过 queryGranularity 来控制注入数据的粒度。 最小的queryGranularity 是 millisecond(毫秒级)。
Roll-up聚合前:
| time | app_key | area | value |
|---|---|---|---|
| 2019-10-05 10:00:00 | area_key1 | Beijing | 1 |
| 2019-10-05 10:30:00 | area_key1 | Beijing | 1 |
| 2019-10-05 11:00:00 | area_key1 | Beijing | 1 |
| 2019-10-05 11:00:00 | area_key2 | Shanghai | 2 |
Roll-up聚合后:
| time | app_key | area | value |
|---|---|---|---|
| 2019-10-05 | area_key1 | Beijing | 3 |
| 2019-10-05 | area_key2 | Shanghai | 2 |
3.1. 位图索引
以下为一个DataSource(表)中存储的数据。
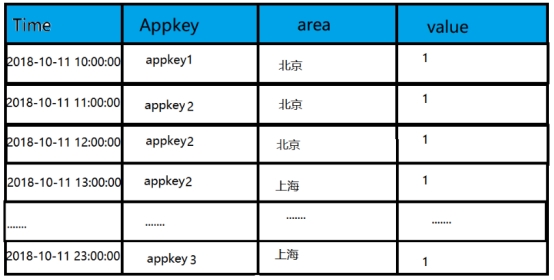
第一列为时间,Appkey和area都是维度列,value为metric列;
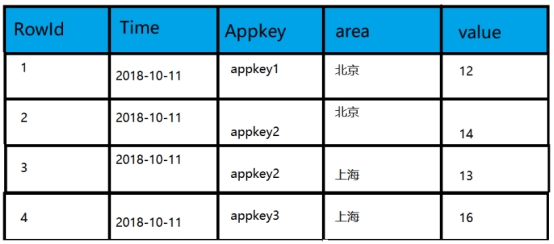
Druid会在导入阶段自动对数据进行Rollup,将维度相同组合的数据进行聚合处理;
按天聚合后的数据如下:
Druid通过建立位图索引,来实现快速进行数据查找。
索引如下所示:
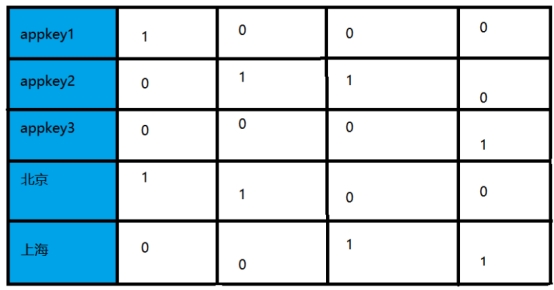
索引位图可以看作是HashMap<String, Bitmap>
key就是维度的取值;
value就是该表中对应的行是否有该维度的值;
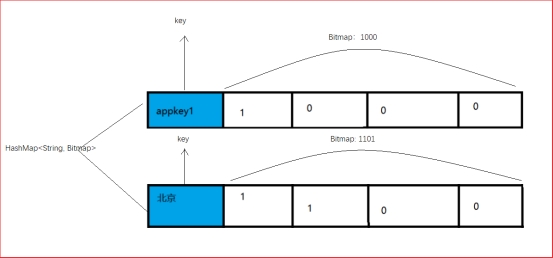
以SQL查询为例:
1)boolean条件查询
select sum(value) from AD_areauser where time=’2017-10-11’ and Appkey in (‘appkey1’,’appkey2’) and area=’北京’
执行过程分析:
- 根据时间段定位到segment
- Appkey in (‘appkey1’, ‘appkey2’) and area=’北京’查到各自的bitmap
2.1: (appkey1(1000) or appkey2(0110)) and (北京(1100) ) =》 (1000 or 0110 )and 1100
2.2: (1000 or 0110) and 1100 = 1110 and 1100 = 1100
2.3: 符合条件的列为第一行和第二行,这两行的 sum(value) 的和为26.
2)group by 查询
select area, sum(value) from AD_areauser where time=’2017-10-11’and Appkey in (‘appkey1’,’appkey2’) group by area
该查询与上面的查询不同之处在于将符合条件的列
- appkey1(1000) or appkey2(0110) = (1110)
- 将第一行、第二行、第三行取出来
- 在内存中做分组聚合。结果为:北京:26, 上海:13.
本次项目使用Druid来进行实时OLAP分析,通过Flink预处理Kafka的数据,再将预处理后的数据下沉到Kafka中。再基于Druid进行数据分析。
以上是关于大数据繁荣生态圈组件之实时大数据Druid小传Druid架构与原理的主要内容,如果未能解决你的问题,请参考以下文章