Hadoop之hdfs
Posted skyyuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之hdfs相关的知识,希望对你有一定的参考价值。
大数据中我们常见的组件之一就是hdfs了。hdfs又是hadoop生态圈中必不可少的一个框架,所以我们进入Hadoop就必须要对它有一定的了解。
首先我们都知道hdfs是hadoop生态圈中的分布式文件系统,他存储了我们大数据中的海量数据,
正是因为谷歌的论文的发布,我们才会有了hdfs的产生,伴随的也是大数据时代的来临。
下面我们介绍一下其中的各大组件(不包括HA模式下),①namenode(保存元数据,并与datanode之间保持心跳,与client端建立通信),这里说到通信,那我们就必须要说一下这里面的通信方式了,我们都知道TCP是java中常见的通信方式,而在Hadoop中我们引入了RPC(远程过渡调用),是我们的节点之间保持会话。②datanode(真正保存数据的地方,通常我们设置的都是多副本机制(副本数为3最好)),③secondrynamenode(这里我们需要记住他不是namenode的备份,而是定期合并Editlog和fsimage的(namenode 默认6小时或者100万次操作),然后刷新到我们namenode中的镜像里面,也就是fsimage中)
hdfs的写流程(不说废话,直接上图!!!)
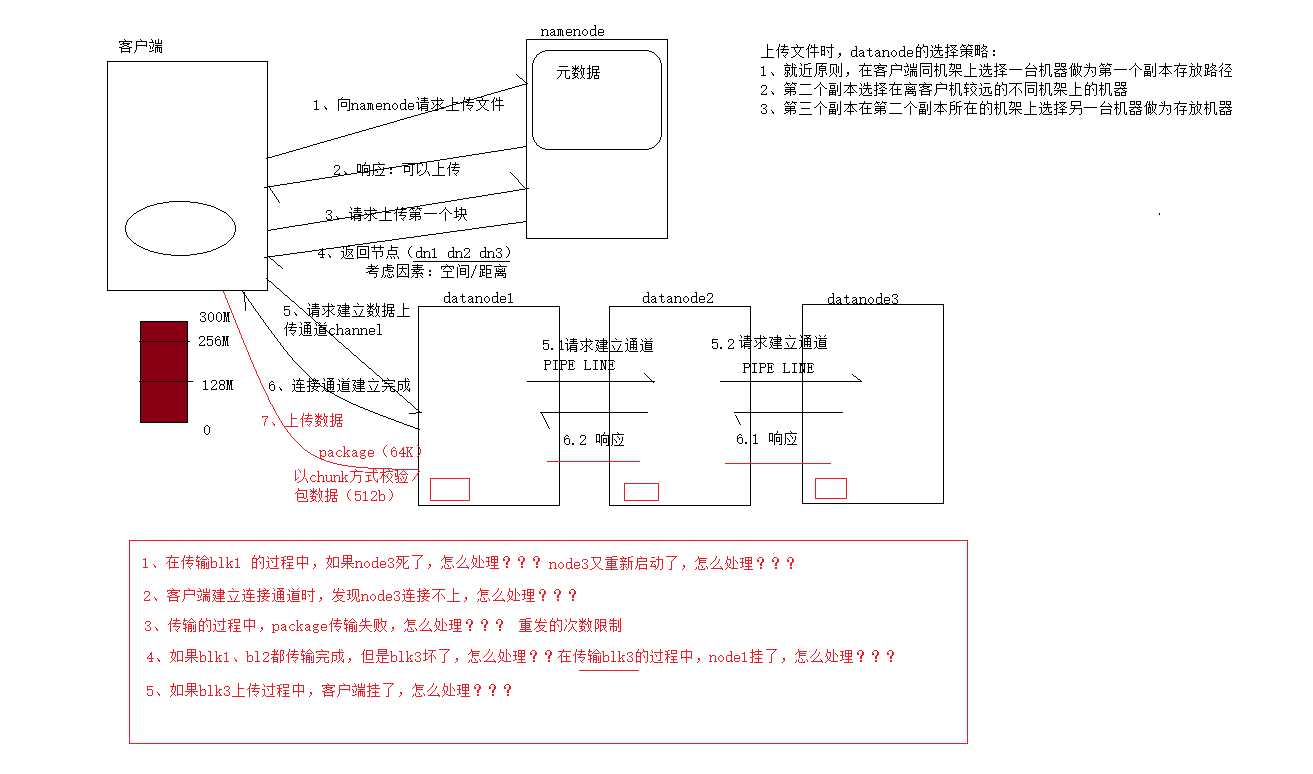
问题1 node3死了,blk1会继续上传,然后在一定的心跳次数后仍未收到,此时namenode会清除dd3的元数据 如果还未删除,node3重启后,namenode会通知他旁边的datanode复制一份数据给他,若是被替代后,则不可再被使用。
问题2 多次进行通信连接,再连接不上时,便会认为不可连接
问题3 多次尝试,最后认为作业失败
问题4 作业提交失败 多次尝试连接,最后认为失败
问题5 作业失败
以上是关于Hadoop之hdfs的主要内容,如果未能解决你的问题,请参考以下文章