因果推断与反事实预测——利用DML进行价格弹性计算(二十三)
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了因果推断与反事实预测——利用DML进行价格弹性计算(二十三)相关的知识,希望对你有一定的参考价值。
文章目录
1 导言
1.1 价格需求弹性介绍
经济学课程里谈到价格需求弹性,描述需求数量随商品价格的变动而变化的弹性。价格一般不直接影响需求,而是被用户决策相关的中间变量所中介作用。假设 Q 为某个商品的需求的数量,P 为该商品的价格,则计算需求的价格弹性为,

通过上式可以简单知道,价格改变 1 元比价格改变 100 元,会导致更大的需求改变。比如以 5 元的价格每日可以卖 100 单位产品,如果价格需求弹性为 -3 ,那供应商将价格提升 5%(dp /P,从 5 元-> 5.25 元),需求将下降 15%(dQ/Q ,从 100->85)。那么收入将减少 1005-5.2585=53.75。
如果单价降低 5%,那么收入同理将提升 46.25。如果供应商知道了产品的价格弹性,那无须反复测试,即可清楚为提升收入到底应该是提价还是降价。
1.2 由盒马反事实预测论文开始
之前在因果推断笔记——DML :Double Machine Learning案例学习(十六)这篇提到用DML求价格弹性,不过没有实操模块,本篇是在看过因果推断与反事实预测——盒马KDD2021的一篇论文(二十三) 盒马论文之后,想实操一下价格弹性这块。
先来提一下盒马这篇,在反事实预测任务上(随着折扣改变销量如何改变)的尝试半参数模型、XGBtree模型、DeepIV:
- 第一种,半参数模型,不过这篇对动态折扣下销量的预估的半参数笔者还没深入了解,感觉用
分层的价格弹性(平均折扣tree销量预测 + 价格弹性拟合动态折扣销量增量)来规避了核心因果推理的问题,后续要再理解一下该模型 - 第二种,错误尝试,将折扣当作treatment,动态将treatment作为特征来预测销量
- 第三种,deepIV,将三级品类的平均价格(treatment)作为工具变量
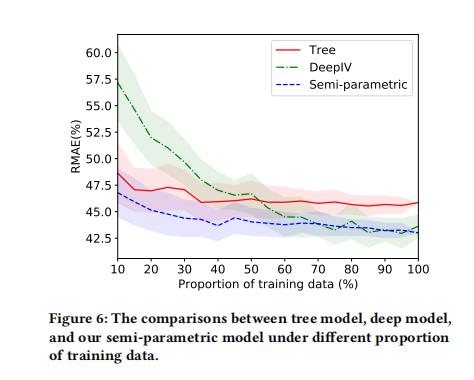
三者效果如图,还是semi-para好多了:


本篇是想放大价格弹性的因果计算模块,与盒马的不同:
- 推估弹性的方法不同(本篇是用DML预测)
- 粒度不同,本篇案例可没顾得上商品分类,一股脑子全放一起了,盒马那篇弹性系数是By 每个商品
1.3 DML - 价格弹性预测推理步骤
最好的方式,当然是直接进行 A/B 实验测试不同价格对用户的需求反应,但是价格这类的外生因素在同一产品同一阶段上,对不同用户展示不同的价格会直接损坏用户体验。因此从观察历史数据进行因果推断,但混杂因素(季节性、产品质量等)如何控制是因果推断的挑战。
这里采用 DML(Double Machine Learning) 方法进行因果推断,该方法主要解决两个问题:
- 第一,通过正则化挑拣重要控制变量;
- 第二,对比传统的线性回归模型,用非参数推断可以解决非线性问题。
DML 先应用机器学习算法去分别通过特征变量 X, W 拟合结果变量 Y 和处理变量 T,然后通过线性模型,使用处理变量的残差拟合出结果变量的残差。
目标是估计 ,这里的 Y 函数构成为 T 的因果作用和 X、W 的协同作用之和。
本篇整个价格弹性的推理过程:
-
将数据分为两部分,一部分样本选用随机森林等模型,用混杂变量预测处理变量(价格 P),得到 E[P|X];另外的样本同样可选择随机森林模型,用混杂变量预测结果变量(需求量 Q),得到 E[Q|X]。
-
计算残差,得到不受混杂变量影响的价格 P 和 需求量 Q,即为 P ~ , Q ~ \\widetilde P , \\widetilde Q P ,Q
P ~ = P − E [ P ∣ X ] \\widetilde P = P-E[P|X] P =P−E[P∣X]
Q ~ = Q − E [ Q ∣ X ] \\widetilde Q = Q-E[Q|X] Q =Q−E[Q∣X] -
因此直接将 P ~ , Q ~ \\widetilde P , \\widetilde Q P ,Q 进行 log-log 回归就能得到弹性系数 𝜃:
需要得到 θ = d Q ~ / Q ~ d P ~ / P ~ \\theta=\\fracd \\widetilde Q / \\widetilde Qd \\widetilde P / \\widetilde P θ=dP /P dQ /Q
倒推用log-log回归得到回归系数,即 l o g Q ~ ~ θ ∗ l o g P ~ + 截 距 log \\widetilde Q ~ \\theta * log \\widetilde P + 截距 logQ ~θ∗logP +截距
2 案例详解
与本节关联的文章:
下面的案例的来源:
- 利用机器学习因果推理进行弹性定价
- 数据分析36计(29):价格需求弹性和因果推断
- 简单版代码:DML.ipynb
- 数据集来源:Association Rules and Market Basket Analysis
2.1 数据清理
数据集是kaggle的比赛数据集,原文ipynb直接读入的时候会格式报错,这里贴一段kaggle原生读入的方式,不会有报错:
data = pd.read_csv('OnlineRetail.csv',encoding= 'cp1252',parse_dates=['InvoiceDate'])
data = data.sort_values(by='InvoiceDate')
data = data.set_index('InvoiceDate')

原数据是购物篮分析数据,这个数据集包含了一家英国在线零售公司在8个月期间的所有购买行为。
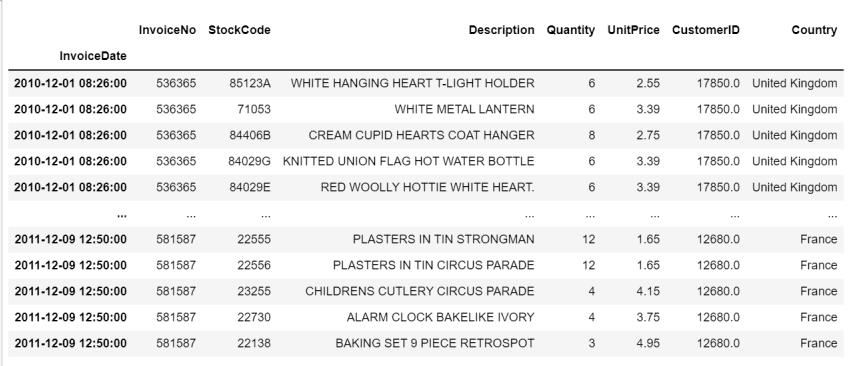
每个商品,在每个国家,每家店,每个时间出售的件数与对应的单价。
这里需要额外加工收入:
df['revenue'] = df.Quantity * df.UnitPrice
同时对P / Q进行对数化处理:
# 将单价和数量取log
df_mdl = df_mdl.assign(
LnP = np.log(df_mdl['UnitPrice']),
LnQ = np.log(df_mdl['Quantity']),
)

2.2 [v1版]求解价格弹性:OLS回归
v1版 = LnQ~LnP,没有协变量,用最简单的OLS回归
最简单的求解,也不管啥因果推断,有偏无偏,将上述数据的lnp和lnQ,一股脑子都分段,比如(-2.814,-0.868)就是这区间内lnp和lnQ的平均值,如下:

新生成的LnP和LnQ直接回归即得回归系数:
x='LnP'
y='LnQ'
df = df_mdl
n_bins=15
x_bin = x + '_bin'
df[x_bin] = pd.qcut(df[x], n_bins)
tmp = df.groupby(x_bin).agg(
x: 'mean',
y: 'mean'
)
# 回归
mdl = sm.OLS(tmp[y], sm.add_constant(tmp[x]))
res = mdl.fit()
得到结果:

弹性系数为-0.6064,价格越高,销量越少
v1的计算也可以使用另外一种方式,计算方差,
因为只有两个变量可以:
df_mdl[['LnP', 'LnQ']].cov()
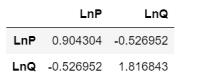
这里就是:
θ
=
−
0.52
0.9
=
−
0.60
\\theta=\\frac-0.520.9=-0.60
θ=0.9−0.52=−0.60
2.3 [v2版]求解价格弹性:Poisson回归+多元岭回归
v2版 = LnQ~LnP+Country+StockCode+Date,有多元协变量,用岭回归+泊松回归
import sklearn.preprocessing
from sklearn import linear_model
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler, RobustScaler
from sklearn.feature_extraction.text import CountVectorizer
feature_generator_basic = ColumnTransformer(
[
('StockCode', OneHotEncoder(), ['StockCode']),
('Date', OneHotEncoder(), ['Date']),
('Country', OneHotEncoder(), ['Country']),
('LnP', 'passthrough', ['LnP']),
], remainder='drop'
)
mdl_basic = Pipeline([
('feat_proc', feature_generator_basic),
('reg', linear_model.PoissonRegressor(
alpha=1e-6, # l2 penalty strength; manually selected value for minimum interference on LnP-coef (elasticity)
fit_intercept=False, # no need, since we have OneHot encodings without drop
max_iter=100_000,
)),
], verbose=True)
mdl_basic_ols = Pipeline([
('feat_proc', feature_generator_basic),
('reg', linear_model.Ridge(
alpha=1e-20, # l2 penalty strength, "very small"
fit_intercept=False,
max_iter=100_000,
)),
], verbose=True)
mdl_basic.fit(
df_mdl[['LnP', 'StockCode', 'Date', 'Country']],
df_mdl['Quantity'] # Poisson regression has log-link, so LnQ is implicit in loss function
)
但是训练数据不跟之前v1一样,不需要分组,直接用原始数据:

柏松回归中LnP的回归系数为 -2.87559,
Ridge—OLS回归中LnP的回归系数为 -1.79945,
尝试下来各个方法得到的结果差异很大。
2.4 [v3版]求解价格弹性:DML
2.4.1 DML数据准备 + 建模 + 求残差
因为不同产品的单价差异很大,所以对于同一维度的单价需要减去该维度的单价均值:
d
L
n
P
i
,
t
=
l
o
g
(
p
i
,
t
)
−
l
o
g
(
p
‾
i
)
dLnP_i,t=log(p_i,t)-log(\\overline p_i)
dLnPi,t=log(pi,t)−log(pi)
这里,消除数据差异的方法,在盒马论文里面是:
- Y i o Y_i^\\texto Yio是常规渠道产品 i i i近期的平均销量
- Y i / Y i nor Y_i/Y_i^\\textnor Yi/Yinor代表了折扣价格使得销量增加的百分比,因为不同商品销量差异很大,所以比率会比绝对值更有用
df_mdl['dLnP'] = np.log(df_mdl.UnitPrice) - np.log(df_mdl.groupby('StockCode').UnitPrice.transform('mean'))
df_mdl['dLnQ'] = np.log(df_mdl.Quantity) - np.log(df_mdl.groupby('StockCode').Quantity.transform('mean'))
混杂因子也做了一些处理:
- 季节性变量:该价格处于第几月、处于月里第几天和周里第几天
- 产品上线的时长:用当期时间减去该产品的最小时间
- sku 的价格水平:单个sku内的价格中位数
df_mdl = df_mdl.assign(
month = lambda d: d.Date.dt.month,
DoM = lambda d: d.Date.dt.day,
DoW = lambda d: d.Date.dt.weekday,
stock_age_days = lambda d: (d.Date - d.groupby('StockCode').Date.transform('min')).dt.days,
sku_avg_p = lambda d: d.groupby('StockCode').UnitPrice.transform('median')
)
有了混杂因子,lnp,lnq,来看看DML过程:
- 构建 l n p − W lnp-W lnp−W, l n q − W lnq-W lnq−W
- 计算残差
# 混杂因子针对Q \\ P 分别建模
model_y = Pipeline([
('feat_proc', feature_generator_full),
('model_y', RandomForestRegressor(n_estimators=50, min_samples_leaf=3, n_jobs=-1, verbose=0))
# n_samples_leaf/n_estimators is set to reduce model (file) size and runtime
# larger models yield prettier plots.
])
model_t = Pipeline([
('feat_proc', feature_generator_full),
('model_t', RandomForestRegressor(n_estimators=50, min_samples_leaf=3, n_jobs=-1, verbose=0))
])
# 上述模型得到预估值
# Get first-step, predictions to residualize ("orthogonalize") with (in-sample for now)
q_hat = model_y.predict(df_mdl)
p_hat = model_t.predict(df_mdl)
# 用观测值减去预测得到的值求解残差
df_mdl = df_mdl.assign(
dLnP_res = df_mdl['dLnP'] - p_hat,
dLnQ_res = df_mdl['dLnQ'] - q_hat,
)
2.4.2 三块模型对比
此时经过数据处理,数据集中就有三种数据类型:
- 对数
- 对数+去均值化
- 对数+去均值化+求残差
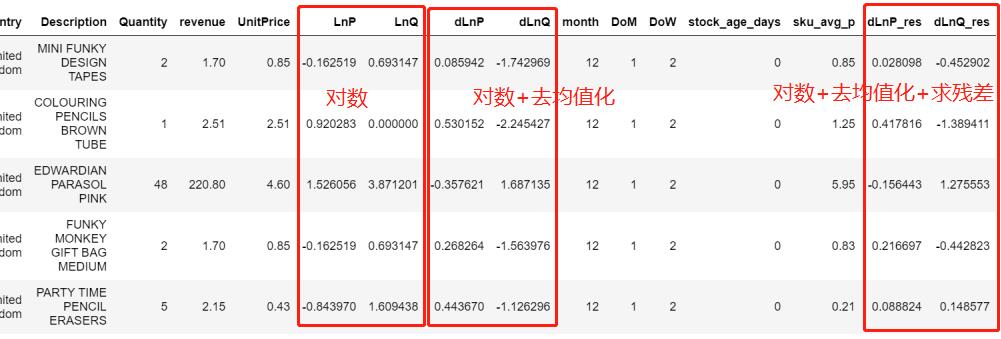
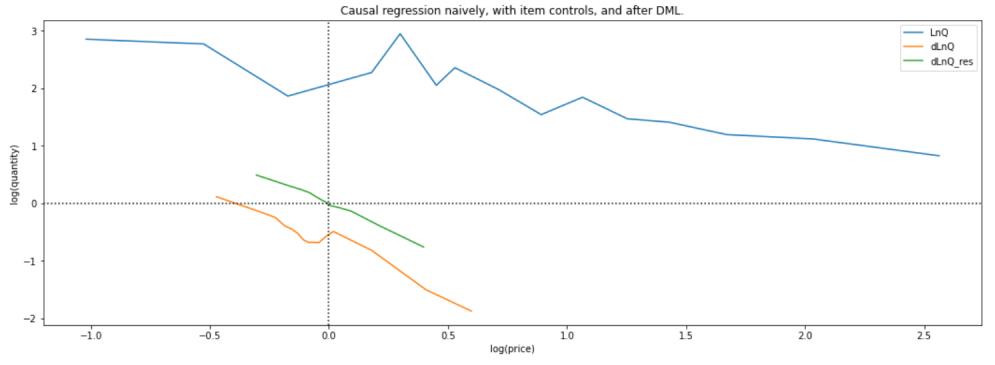
然后三组数据,按照v1版的处理方式,先分段,后利用OLS求价格弹性:

# 初始ols模型
old_fit = binned_ols(
df_mdl,
x='LnP',
y='LnQ',
n_bins=15,
)
# 初始去均值化后的ols模型
old_fit = binned_ols(
df_mdl,
x='dLnP',
y='dLnQ',
n_bins=15,
plot_ax=plt.gca(),
)
# 残差拟合的ols模型
old_fit = binned_ols(
df_mdl,
x='dLnP_res',
y='dLnQ_res',
n_bins=15,
plot_title='Causal regression naively, with item controls, and after DML.',
plot_ax=plt.gca()
)
此时经过数据处理,数据集中就有三种数据类型,三者的价格弹性对比:
- 对数: θ = − 1.7 \\theta=-1.7 θ=−1.7
- 对数+去均值化: θ = − 1.7 \\theta=-1.7 θ=−1.7
- 对数+去均值化+求残差: θ = − 1.819 \\theta=-1.819 θ=−1.819
当然OLS还有截距项,绘图可得:
这里原文也给出了,DML求解过程中,两个随机森林模型的特征重要性:
feat_imp = pd.DataFrame(
'feat': get_feat_generator_names(model_y['feat_proc']),
'importance_q': model_y['model_y'].feature_importances_,
'importance_p': model_t['model_t'].feature_importances_,
).set_index('feat')
feat_imp.sort_values(by='importance_p').iloc[-15:].plot.barh(
figsize=(5, 8),
title='feature importances for DML estimators of treatment(p) and outcome(q)'
)

2.4.3 稳健性评估
这章主要学习到的:
- 一种数据筛选的原则,残差正交化后, d L n P r e s dLnP_res dLnPres 总是很小,因此为了减少噪音,我们将丢弃所有非常小的价格变化观察值,它们不包含太多信息
训练数据分成多k-fold来检验弹性系数的稳定性
那么在盒马那篇文章里面来看一下这个图,
使用training data的比例往上几个模型的稳定性分布情况
模型的预测推断结果是
θ
^
=
d
L
n
Q
r
e
s
d
L
n
P
r
e
s
\\hat \\theta=\\fracdLnQ_resdLnP_res
θ^=dLnPresdLnQres
但是残差正交化后, d L n P r e s dLnP_res dLnPres 总是很小,因此为了减少噪音,我们将丢弃所有非常小的价格变化观察值,它们不包含太多信息。
Chernozhukov 提出了一个改进的 DML,传统的标准 OLS 方法估计
θ
^
=
(
P
~
T
P
~
)
−
1
P
~
T
Q
~
\\hat \\theta=(\\widetilde P^T \\widetilde P)^-1\\widetilde P^T \\widetilde Q
θ^=(P
因果推断——借微软EconML测试用DML和deepIV进行反事实预测实验(二十五)
因果推断笔记——DML :Double Machine Learning案例学习(十六)
因果推断笔记——DML :Double Machine Learning案例学习(十六)