模型推理量化实现分享四:Data-Free Quantization 香不香?详解高通 DFQ 量化算法实现
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理量化实现分享四:Data-Free Quantization 香不香?详解高通 DFQ 量化算法实现相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
O_o >_< o_O O_o ~_~ o_O
大家好,我是极智视界,本文剖析一下高通 DFQ (Data-Free Quantization) 量化算法实现,以 Tengine 的实现为例。
本文是模型量化实现分享的第四篇,前面已有三篇,有兴趣的同学可以查阅:
(1) 《【模型推理】量化实现分享一:详解 min-max 对称量化算法实现》
(2) 《【模型推理】量化实现分享二:详解 KL 对称量化算法实现》
(3) 《【模型推理】量化实现分享三:详解 ACIQ 对称量化算法实现》
高通 DFQ 量化算法在论文《Data-Free Quantization Through Weight Equalization and Bias Correction》中提出,论文的一开始就把量化算法划了四个层级:
Level 1: No data and no backpropagation required. Method works for any model;
Level 2: Requires data but no backpropagation. Works for any model;
Level 3: Requires data and backpropagation. Works for any model;
Level 4: Requires data and backpropagation. Only works for specific models;
认为 Level 1 级的量化是最高级的,但我并不认为 DFQ 属于 Level 1,至少它是否能 works for any model,需要打个问号。往下看你就会发现,论文以 mobilenetv2 的 conv–> bn–> relu 顺序 block 为主要论证对象,论证的网络结构还是比较局限,不过方法还是比较新颖。
下面还是会从原理和实现分别进行详细的介绍。
文章目录
1、DFQ 量化原理
先来看 DFQ 的量化效果:
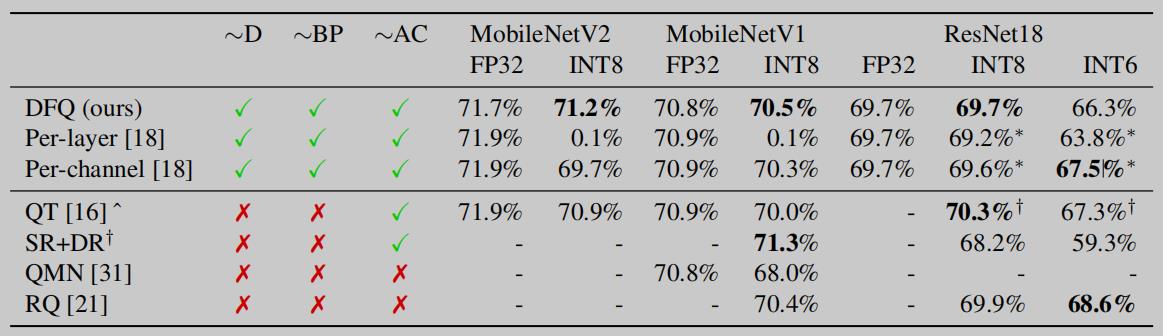
可以看到在 MobileNetV2、MobileNetV1 和 ResNet18 上做 fp32 --> int8 的量化,DFQ 都要优于直接 Per-layer 和 Per-channel 的量化策略,作者还拓展的在 ResNet18 上做了 fp32 --> int6 的量化试验,这个效果没有 Per-channel 好。
DFQ 算法的核心逻辑主要是(1)跨层均衡;(2)偏移吸收;(3)正常量化;(4)偏移修正:

其中(1)、(2)还未开始量化,是量化前的准备工作,(4)是量化后的修正工作。下面分别展开。
1.1 Cross-layer equalization
先说一下对于权重的 Per-layer 量化和 Per-channels 量化,假设权重 W 的 shape 是[n, c, h, w],Per-layer 量化是一下子把 W[:, :, :, :] 进行量化,最后只有一个 Scale 和 一个 Bias;而 Per-channels 则是逐通道 W[:, c, :, :],最后有 c 个 Scale 和 c 个 Bias。对于权重量化来说,Per-layer 策略有个弊端,如下 (Per output channel weight ranges of the first depthwise-separable layer in MobileNetV2):
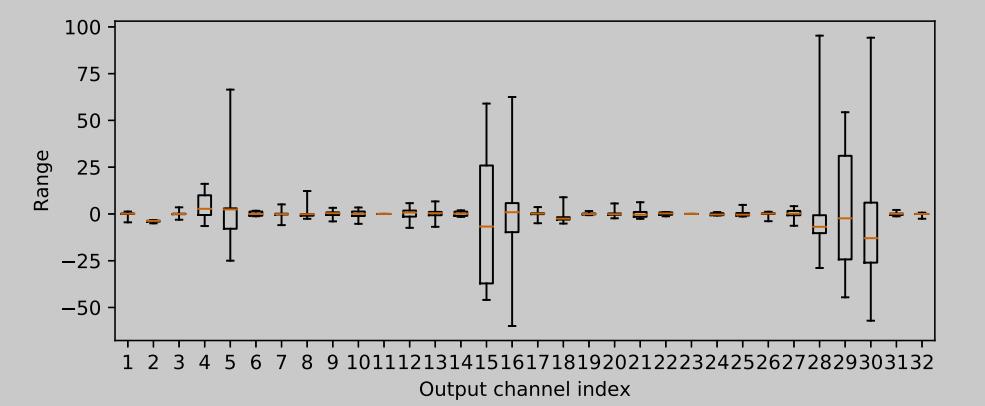
可以看到不同通道的权重的 Range 相差很大,这个时候很难用 Per-layer 的方式只用一个 Scale + Bias 统筹,若用 Per-layer 势必对于一些 Range 小的通道权重量化后值会统一置为 0,这是不合理的。而 Per-layer 的这个缺陷恰恰用 Per-channels 量化能完美解决,因为 Per-channels 会给每个通道一个 Scale 和一个 Bias。那为啥我们不直接用 Per-channels 呢,作者认为 Per-channels 相对于 Per-layer 硬件更不友好,开销更大,所以作者在论文里使劲把 Per-channels 往 Per-layer 改造,这样就诞生了这里的跨层均衡这个 tricks,意思是缩小通道间权值 Range 的差异,使用一个新的更加均衡的 fp32 权重来替代原来的权重,最后达到Per-channels 转换为 Per-layers 的目的。具体怎么做的呢,主要运用了 RELU 的数学特性进行了如下推导:
先来看一下 RELU 函数:
对于一个正半轴的 s,有:

对于网络中的相邻两层:


结合 RELU 的数学特性,可以做如下的推导:

其中:

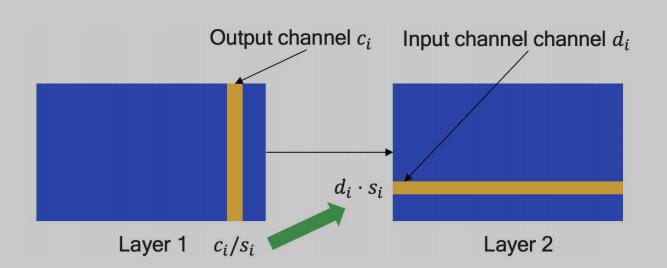
S = diag(s) 是一个对角矩阵,对角线上的各个值是用来调整缩放系数的因子,在 Layer 1 除完的系数需要在 Layer 2 相应乘回,示意如下图:
更进一步的,这个 S 到底怎么算,对于对称量化来说,假设第 i 个通道 Layer 1 和 Layer 2 的权重范围分别为 r1 和 r2,则 i 通道最好均衡到 r = √ (r1r2)(论文中有证明),那么 S 就可以这么计算得到:

这里介绍了 Layer 1 和 Layer 2 两层之间的通道权值范围的均衡,实际网络中肯定有更加多的相邻层,需要迭代下去看能不能达到量化误差指标,若达到即可停止跨层均衡,这样就完成了整个网络的跨层均衡。
1.2 Absorbing high biases
跨层均衡主要考虑对权重的处理,在整个量化处理中激活值的量化也会对整体量化效果产生比较大的影响,特别是我们在对权重进行均衡缩放处理后,相应的激活值的 Range 也会变化,如当某层某通道的 S > 1 时,则该通道的激活值 Range 范围也会变大,为了避免不同通道的激活值差异过大,需要吸收高偏差到下一层。这里同样运用到了 RELU 的数学性质,再来一波推导。
默认这种 CONV + BN + RELU 顺序结构:
对于 c < (Wx + b) || c = 0 (经 BN 输出的激活值服从高斯分布,由 3σ 原则知有 99.865% 的概率满足 c <= (Wx + b)),则有:

对于 BN --> RELU 这两层来说,进行推导:

其中:

这里就比较巧妙,直接在 Layer 1 输出激活值 h() 上减去 c,使得 Range 范围变小而减小量化误差,而减掉的部分则由下一层 Layer 2 的偏置完全吸收,这样就达到了一个平衡。这样就完成了 bias absorption。
2.3 Quantization
不多说,就是正常量化,实质文章中也没多说。掠过~~~
2.4 Quantization bias correction
先举个量化的例子,比如原始 fp32 Range 范围为 [-1.0, 1.0],咱们进行 fp32 --> int8 量化,则 Sacle = 255 / 2.0 = 127.5,量化后的值域 Range 为 [-127.5, 127.5],然后一般会做个 round() 取整操作,得到最后的量化 Range 为 [-127, 128],如果只考虑对称量化,就没有 + Zero_Point 的偏移,这样就完成了 fp32 --> int8 的过程。然后我们尝试一下复原,即 int8 --> fp32,你会发现最后得到的 fp32 Range 范围为 [-127/127.5, 128/127.5],这与最开始的 [-1.0, 1.0] 存在一些偏差,这个偏差很容易想到是由于 round() 导致的,这也说明了量化的过程是不可逆的。
然后再回到这里,这个 Quantization bias correction 就是为了校正上面提到的不可逆量化误差而导致的量化偏差。且文中还提到比较关键的一点是认为量化误差是有偏误差,有偏误差的意思从分布上来说量化误差的均值并不为0,即会影响输出分布,从而导致输出有偏差。接下来的解法就是类似前面的(1)Cross-layer equalization 和 (2)Absorbing high biases 中用到的 先乘后除/先除后乘 和 先减后加/先加后减 的补偿操作,这里也采用类似的思想,把误差给补回来。下面又开始推导。
假设某层的权重为 W,量化后的权重为 W’,则:

其中:

继而可以推导出偏移:

这个时候重心转移到求 E[x],考虑到网络结构为 BN --> RELU 的顺序结构,RELU 函数的特点是负半轴抑制,所以只会保留正半轴的 BN 输出,可以用以下两种方法来计算 RELU() 后的 E[x]:
(1) 有校准集时,可直接通过统计数据分布来得到 E[x] (但这有违 Data-Free 的思想);
(2) 无校准集时 (Data-Free),经 BN 输出的激活值服从高斯分布,然后再进 RELU,相当于把高斯分布截断只保留正半轴,则问题转换为求正半轴高斯分布的均值,可以这么计算:

好了 DFQ 的原理就是这些,还是有些东西的。接下来是实现。
2、DFQ 量化实现
我们还是以 tengine 中 DFQ 的实现为例进行介绍。
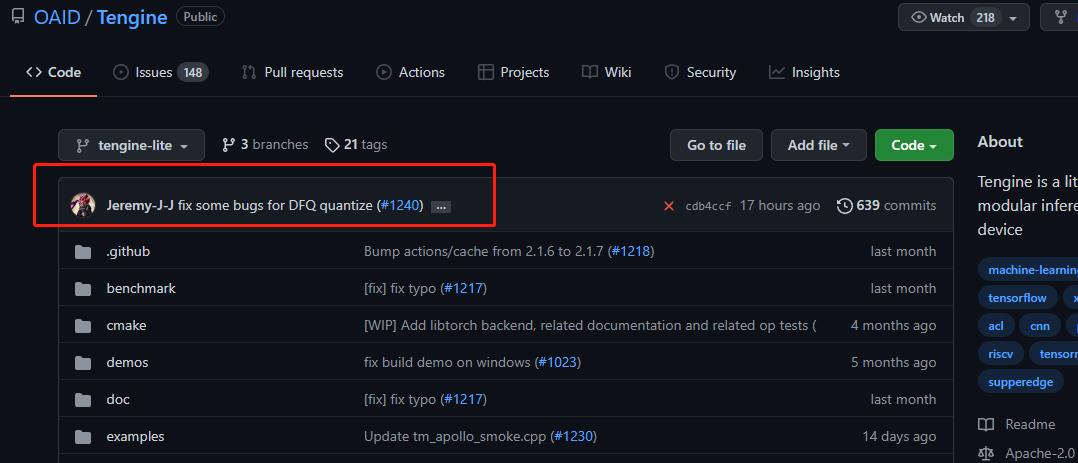
首先先提个小 bug 单(捂脸~)
然后开始。
DFQ 量化的主要实现在这里:
case ALGORITHM_DFQ:
quant_tool.data_free_quant();
quant_tool.model_file = "test_dfq_fp32.tmfile";
if (quant_tool.scale_file.empty())
quant_tool.scale_file = "table_minmax.scale";
quant_tool.activation_quant_tool();
save_graph_i8_perchannel(quant_tool.model_file.c_str(), quant_tool.scale_file.c_str(), quant_tool.output_file, quant_tool.inplace, false);
/* Evaluate quantitative losses */
if (quant_tool.evaluate)
fprintf(stderr, "[Quant Tools Info]: Step Evaluate, evaluate quantitative losses\\n");
quant_tool.assess_quant_loss(0);
break;
可以看到和其他量化算法相比较,DFQ 只是多了一句 quant_tool.data_free_quant(),如下:
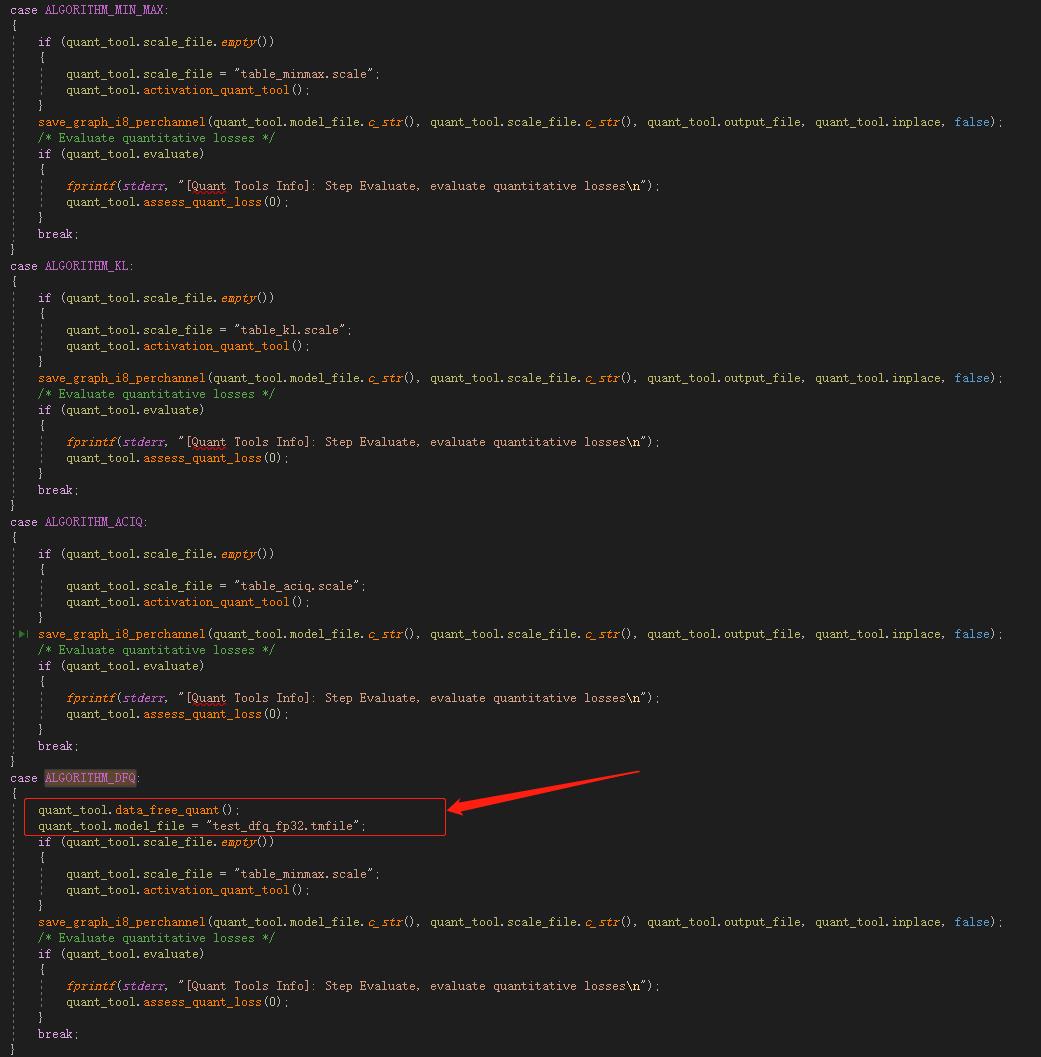
结合上面理论的讲解,应该比较容易猜测 quant_tool.data_free_quant() 应该主要在做量化前处理工作:跨层均衡和高偏移吸收,进入到 data_free_quant() 接口看代码,各种判断+内嵌循环让代码的可读性并不友好。下面慢慢道来。
刚开始主要做一些初始化的工作,就不多说了。
tengine 的实现 主要是对 DW Conv 和 Direct Conv 两种类型的算子进行 DFQ 的前处理均衡,这里你可能会有一些疑问,原理部分一直再说 BN、RELU 的一些数学特性,到这里怎么就变成 CONV 了呢,这主要是由于算子融合,tengine 或者 ncnn 在做模型转换成 tmfile(tengine) 或 bin/params(ncnn) 的时候都会做一些图优化的工作,CONV+BN+RELU 的结构是最基础需要融合成大算子的,所以到了 tengine 的 DFQ 实现里你就看不到针对于 BN、RELU 的一些处理计算了,但是用到的跨层均衡化思想和 DFQ 是一致的。
下面来看对于 Direct Conv 的处理:
/// Direct Conv
auto op_name0 = graphn->node_list[node_input_id]->op.type;
// 识别到 OP_CONV
if (node_proto[node_input_id].output_node_list.size() == 1 && op_name0 == OP_CONV)
struct conv_param* conv_param0 = (struct conv_param*)graphn->node_list[node_input_id]->op.param_mem;
if (conv_param0->group != conv_param0->output_channel || conv_param0->group == 1)
node_proto[i].pass = 1; // layer1 // 待均衡的相邻两层
node_proto[node_input_id].pass = 1; // layer0
// layer0 min/max range
struct node* nodeP = graphn->node_list[node_input_id];
struct tensor* input_tensor = get_ir_graph_tensor(graphn, nodeP->input_tensors[1]);
uint16_t dims0 = input_tensor->dims[0];
uint16_t dims123 = input_tensor->dims[1] * input_tensor->dims[2] * input_tensor->dims[3];
std::vector<float> layer0_max(dims0, 0.0f);
std::vector<float> layer0_min(dims0, 0.0f);
std::vector<float> layer0_range(dims0, 0.0f);
float* data_layer0 = (float*)input_tensor->data;
for (int d0 = 0; d0 < dims0; d0++)
for (int d1 = 0; d1 < dims123; d1++)
if (data_layer0[dims123 * d0 + d1] >= layer0_max[d0])
layer0_max[d0] = data_layer0[dims123 * d0 + d1];
if (data_layer0[dims123 * d0 + d1] < layer0_max[d0])
layer0_min[d0] = data_layer0[dims123 * d0 + d1];
for (int d0 = 0; d0 < dims0; d0++)
layer0_range[d0] = layer0_max[d0] - layer0_min[d0];
// layer1 min/max range
nodeP = graphn->node_list[i];
input_tensor = get_ir_graph_tensor(graphn, nodeP->input_tensors[1]);
dims0 = input_tensor->dims[0];
uint16_t dims1 = input_tensor->dims[1];
uint16_t dims23 = input_tensor->dims[2] * input_tensor->dims[3];
std::vector<float> layer1_max(dims1, 0.0f);
std::vector<float> layer1_min(dims1, 0.0f);
std::vector<float> layer1_range(dims1, 0.0f);
float* data_layer1 = (float*)input_tensor->data;
for (int d0 = 0; d0 < dims0; d0++)
for (int d1 = 0; d1 < dims1; d1++)
for (int d2 = 0; d2 < dims23; d2++)
if (data_layer1[dims1 * dims23 * d0 + dims23 * d1 + d2] >= layer1_max[d1])
layer1_max[d1] = data_layer1[dims1 * dims23 * d0 + dims23 * d1 + d2];
if (data_layer1[dims1 * dims23 * d0 + dims23 * d1 + d2] < layer1_min[d1])
layer1_min[d1] = data_layer1[dims1 * dims23 * d0 + dims23 * d1 + d2];
for (int d0 = 0; d0 < dims1; d0++)
layer1_range[d0] = layer1_max[d0] - layer1_min[d0];
//
// layer ops sqrt
float* ops_range = new float[dims1];
for (int ops = 0; ops < dims1; ops++)
ops_range[ops] = sqrt(layer0_range[ops] * layer1_range[ops]); // 计算通道最合适的缩放Range r = √ (r1r2)
// 计算缩放Scale
float* S01 = new float[dims1];
float* S01_F = new float[dims1];
for (int ops = 0; ops < dims1; ops++)
if (ops_range[ops] == 0)
S01[ops] = 0.0;
else
S01[ops] = layer0_range[ops] / ops_range[ops];
if (layer0_range[ops] == 0)
S01_F[ops] = 0.0;
else
S01_F[ops] = ops_range[ops] / layer0_range[ops];
//
// layer0 output 缩放均衡
nodeP = graphn->node_list[node_input_id];
input_tensor = get_ir_graph_tensor(graphn, nodeP->input_tensors[1]);
dims0 = input_tensor->dims[0];
dims123 = input_tensor->dims[1] * input_tensor->dims[2] * input_tensor->dims[3];
for (int d0 = 0; d0 < dims0; d0++)
for (int d1 = 0; d1 < dims123; d1++)
data_layer0[dims123 * d0 + d1] = data_layer0[dims123 * d0 + d1] * S01_F[d0];
input_tensor = get_ir_graph_tensor(graphn, nodeP->input_tensors[2]);
dims0 = input_tensor->dims[0];
float* data_layer0_bias = (float*)sys_malloc(sizeof(float) * dims0);
data_layer0_bias = (float*)input_tensor->data;
for (int d0 = 0; d0 < dims0; d0++)
data_layer0_bias[d0] = data_layer0_bias[d0] * S01_F[d0];
// layer1 output 缩放均衡
nodeP = graphn->node_list[i];
input_tensor = get_ir_graph_tensor(graphn, nodeP->input_tensors[1]);
dims0 = input_tensor->dims[0];
dims1 = input_tensor->dims[1];
dims23 = input_tensor->dims[2] * input_tensor->dims[3];
for (int d0 = 0; d0 < dims0; d0++)
for (int d1 = 0; d1 < dims1; d1++)
for (int d2 = 0; d2 < dims23; d2++)
data_layer1[dims1 * dims23 * d0 + dims23 * d1 + d2] = data_layer1[dims1 * dims23 * d0 + dims23 * d1 + d2] * S01[d1];
delete[] S01; // free the memory
S01 = NULL;
delete[] S01_F;
S01_F = NULL;
delete[] ops_range;
ops_range = NULL;
然后…循环循环直至均衡整网生成 dfq_fp32_tmfile,然后…还没开始就结束了,如果我没看错的话这就是目前 tengine DFQ 相对于 MIN-MAX 量化实现的不同之处 (意思是后续量化逻辑和 MIN-MAX 一致,tengine DFQ 不同的地方就是输入的 fp32 tmfile 权重数据是经过跨层均衡的),但这也只是实现了 DFQ 论文里第(1)个 tricks,其他几个 tricks 并没有揉进去,这有点不讲武德。

当然这应该也是有待完善的地方,到这里原理和实现暂时就介绍完了。
以上详细分享了高通 DFQ 量化的原理和实现,希望我的分享能对你的学习有一点帮助。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理量化实现分享四:Data-Free Quantization 香不香?详解高通 DFQ 量化算法实现的主要内容,如果未能解决你的问题,请参考以下文章