模型推理谈谈模型量化组织方式
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理谈谈模型量化组织方式相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文主要聊一下深度学习模型量化组织方式。
在我的这篇 《【模型推理】谈谈推理引擎的推理组织流程》文章里对模型量化策略进行了一些介绍,有兴趣的同学可以翻看一下。今天这里主要聊一下实际推理中,怎么来组织量化过程,涉及多层之间如何衔接的问题。这里分两个部分聊一下:量化模型结构、实际举例说明。
文章目录
1、量化模型结构
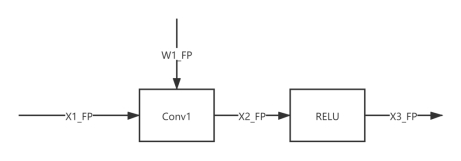
量化的操作会对网络模型有什么影响呢?下图以卷积为例,图左边表示对输入进行量化的过程,其中 Quantize Weight 权重量化在推理前就完成,Quantize Activation 激活值量化需要在推理时进行;图中间表示量化的卷积层运算;图右边表示怎么和后续层进行衔接。
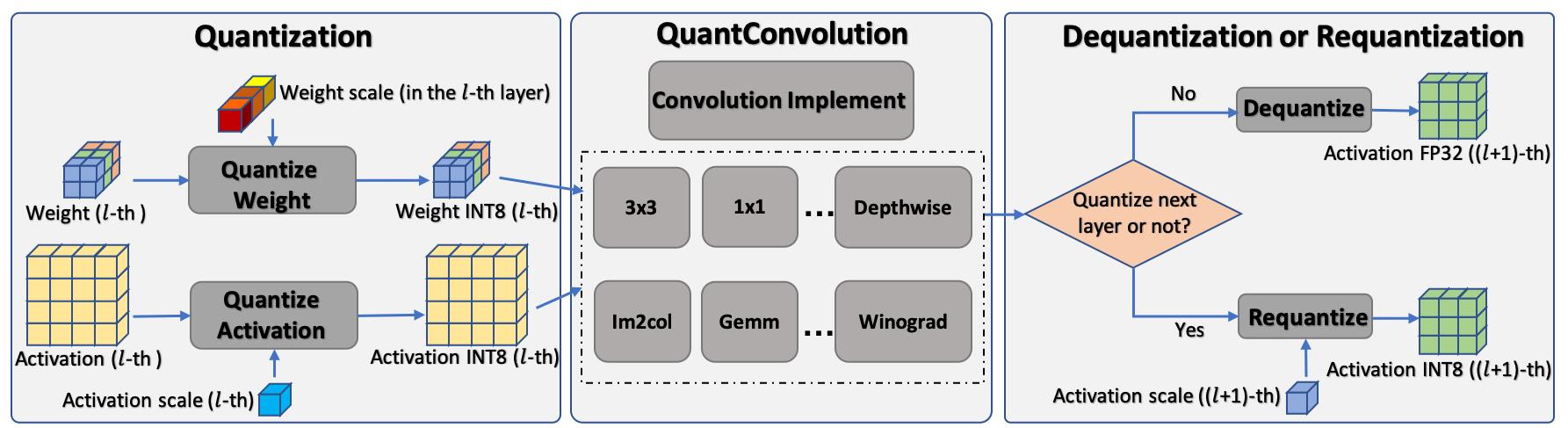
以上描述的整个过程可以表示为 quantization -> compute -> dequantization / requantization,这样就完成了一个量化的卷积结构。最近在适配新的卡,我拿一个 tf 框架量化好的网络片断展示一下。
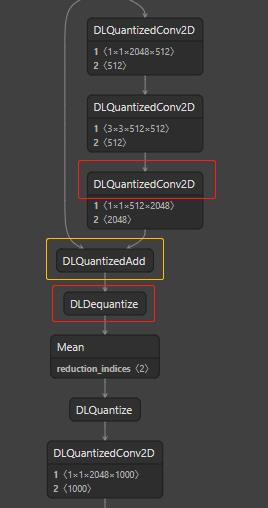
可以看到上述结构中既有 quantization,也有 dequantization,这些看起来很正常。注意看黄色框,是做了把两个量化层进行 tf.add 拼接的操作,tf.add 的功能十分丰富,可以做元素加、矩阵加、元素和矩阵加,也具有广播的机制,总体来说,通过 tf.add 有两种情况:(1)eltwise-add 维度不变,类似的算子有 darknet shortcut;(2)维度改变,类似算子有 darknet route、pytorch torch.nn.cat。对于常用的线性量化来说,类似算子拼接 concat / eltwise 的非线性变换对于常规量化来说其实并不友好。
2、实际举例
为了对模型量化的组织方式进行更加好的说明,这里我进行了一些举例。
2.1 Conv + Conv 结构
2.1.1 网络结构组织
假设两个 conv 都进行量化。
还未量化时的模型结构如下所示:
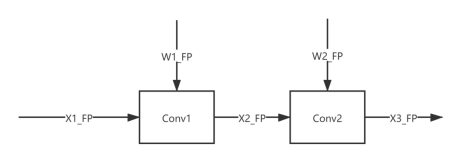
在经过权重量化和激活值量化后,结构示意如下:
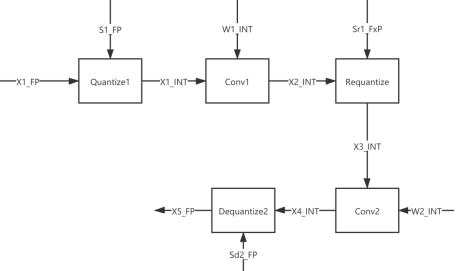
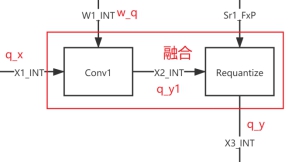
上图中 Sr1_FxP 为定点数,不少推理框架在实际推理中会进行算子融合,从而减少层与层之间的数据搬运开销,一般会把数据搬运的对象转换为 INT 类型的 Tensor。算子融合示意如下:
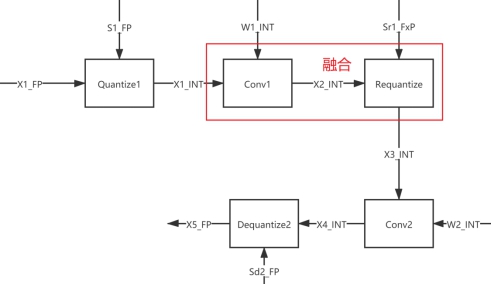
不同于常规的 conv + bn + relu 的算子融合,这里其实是做量化过程特有的 conv1 + requantize 的融合,完了会得到如下 quantizedConv2d 的算子层。
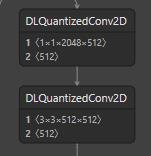
2.1.2 数学关系式
对于量化过程,不只是需要对量化算子计算缩放系数,还需要进行量化网络结构组织,以及算子参数计算。
假设卷积的数学表达式如下:

激活值量化和权重量化的数学表达如下:

将上式代入原始卷积表达式中,可以得到如下式子:

由于紧接着下一层还要量化,所以 y 也需要量化,其量化方式如下:

将上式代入卷积表达式中,得到了如下式子:

根据上式,假设模型压缩后的卷积核参数为 wq,偏置为 bq,后一层 Requantize 的定点数参数为 Sr1_FxP,那么可以得到如下对应关系:

把上式代入,得到融合后的卷积量化公式是如下,其中qx、wq、qy 一般是 int8 数据类型,bq、qy1 一般是 int32 数据类型,Sr1_FxP 是个定点数:

上述的数据表达可以对应到如下示意图:
接下来介绍下 Requantize 层的计算是如何实现的,从 Requantize 的计算公式定义可知,Requantize 层实现了把一个范围的整型数映射到了另一个范围的整型数,以下是 Requantize 的计算方式:

上述式子中 k 为定点数的小数点所占比特位长度,>>k 表示比特位右移的操作。
2.2 Conv + RELU 结构
假设这个结构有两种量化形式:(1)conv 量化 + relu 量化;(2)conv 量化 + relu 不量化。
2.2.1 RELU 量化的网络结构组织
假设 Conv 和 RELU 都进行量化。
未量化的模型结构如下:
经过激活值量化和权重量化后的结构示意如下:
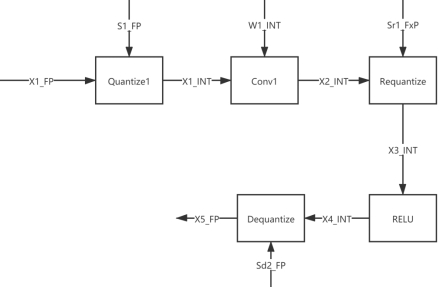
上图中 Sr1_FxP 为定点数,若进行算子融合,会得到如下示意图:
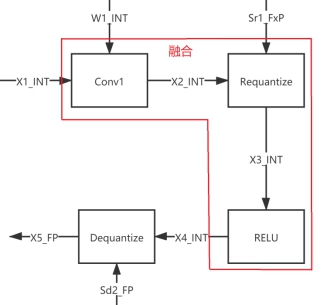
2.2.2 RELU 量化的数学关系式
这里沿用第一个例子的假设变量,同时假设 X4_INT 为 k,那么对于 RELU 函数的量化,我们可以得到如下的数学表达式:

其中最关键的思想是:不管是 qy > zy,还是 qy <= zy,都使用了 clip 截断函数代替了 RELU,因为使用 clip 截断到 0 以上的范围,就相当于进行了 RELU 操作。
假设模型压缩后的卷积核参数为 wq,其偏置为 bq,后一层 Requantize 的定点数参数为 Sr1_FxP,这个时候 RELU 这个层就相当于没有了,那么可以得到如下对应关系:

把上式代入,得到融合后的卷积量化公式是如下,其中 qx、wq、qy 一般是 int8 数据类型,bq、qy1 一般是 int32 数据类型,Sr1_FxP 是个定点数:

2.2.3 RELU 不量化的网络模型结构组织:
如下图所示,此时可以将 Conv1 和 Dequantize 进行算子融合,减少数据传输次数,其中 X2_INT 一般是 int32 数据类型。
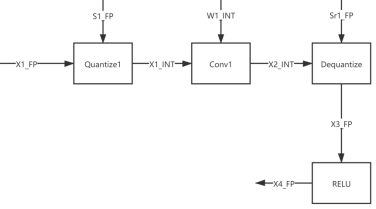
2.2.4 RELU 不量化的数学表达式:
融合后,输入是 int8 数据类型,输出是浮点数据类型,数学表达如下:

同样可以得到量化后的卷积参数如下:

Dequantize 层有两种运算方案:
(1)浮点化整数,Sr1_FxP 也采用浮点运算存储,这一步就相当于直接采用了浮点运算进行缩放;
(2)类似于 Requantize 层的操作,也就是 (定点小数 * 整数) = (整数 * 整数,然后右移小数位长度),只是这里 Dequantize 输出为浮点数而已。
以上聊了一下模型量化的组织方式,并拿 Conv + Conv、Conv + RELU 的常见结构进行了介绍。
有问题欢迎沟通,收工了~ 祝大家国庆快乐~
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理谈谈模型量化组织方式的主要内容,如果未能解决你的问题,请参考以下文章