模型推理谈谈几种量化策略:MinMaxKLDADMMEQ
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理谈谈几种量化策略:MinMaxKLDADMMEQ相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文主要聊一下深度学习模型量化相关策略。
模型小型化是算法部署的关键技术,模型小型化的过程通常用模型量化来描述。量化通常是高比特位到低比特位的映射过程,量化的对象既可以是权重数据,也可以是激活值。量化方式具有多种形态,不管是混合量化、还是全整型量化;不管是单层量化、成组量化、还是整网量化,都存在浮点数映射到整型数的过程,这个过程一定存在精度损失,而对于我们来说,要做的是把精度损失控制在可接受的范围。
量化又可以分为后量化、训练时量化又或是量化感知训练。后量化相比训练时量化,是一种更加高效和无侵入式的算法加速技术,这里主要聊一下后量化,包括一些主要的量化类型和量化策略:
- 量化类型:非对称量化和对称量化、非线性量化和线性量化;
- 量化策略:MinMax、KLD、ADMM、EQ;
1、量化类型
1.1 非对称量化和对称量化
非对称量化是比对称量化更加广义的概念,对称量化是非对称量化的一种特殊情况。
非对称量化也就是带有偏置的线性映射,其数学表达可以是这样:

其中 Z 不一定等于 0,代表浮点数的零点不一定对应整型的零点。E() 代表截断函数,作用是使其截断到对应整型的数值表述范围内。对于非对称量化,满足如下的约束:

上述约束中,T1 和 T2 是对于浮点数的截断范围,也就是非对称量化的阈值。通过换算可以得到阈值和线性映射参数 S 和 Z 的数学关系,在确定了阈值后,也就确定了线性映射的参数。

对称量化可以看作非对称量化当 Z = 0 时的一种特殊情况,满足 T1 = -T2,此时的阈值和线性映射参数的数学关系如下:

1.2 非线性量化和线性量化
线性量化往往又被称为均匀量化,这在目前的算法落地中是最常用的,上面提到的非对称量化和对称量化也是基于线性量化的。非线性量化实际用的比较少,以 LOG 量化为代表。
不同的量化方式对数据分布具有选择性。对于均匀量化,假设数据在整个表达空间内均匀分布,在均匀分布下线性量化是一种较好的量化方式。 LOG 量化则可以保证数值空间内相对误差的最优化,这是目前大部分非线形量化的目标,通过对数据分布的分析,可以提升高密度数据区域的表达能力。
举个例子,假设我要对一组数据 x 进行 int8 对称量化,量化范围为 (-a, a),对于线性量化,可以用以下数学式进行表达:
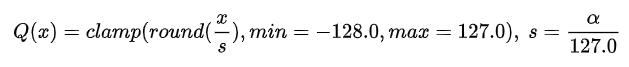
同样的,对于 LOG 非线性量化可以用如下式子进行表达:
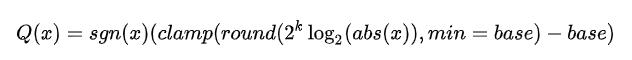
2、量化策略
从上述的映射关系中,如果知道了阈值,那么其对应的线性映射参数也就知道了,整个量化过程也就明确了。那么该如何确定阈值呢?一般来说,对于权重的量化,由于权重的数据分布是静态的,一般直接找出 MIN 和 MAX 线性映射即可;而对于推理激活值来说,其数据分布是动态的,为了得到激活值的数据分布,往往需要一个所谓校准集的东西来进行抽样分布,有了抽样分布后再通过一些量化算法进行量化阈值的选取。
2.1 MinMax 量化
MinMax 是最简单的量化方法,量化示意如下:
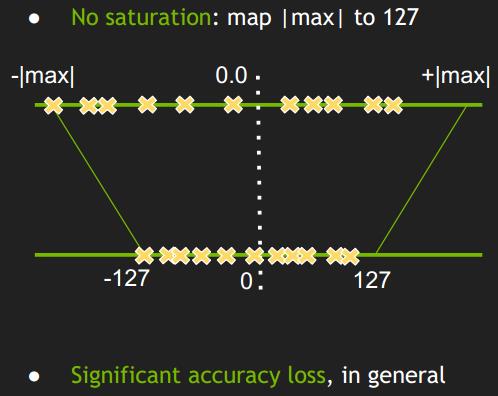
MinMax 其实就是简单的把浮点数直接映射到 int8 的数据范围,MinMax 方法由浮点映射到定点的数学表达如下:
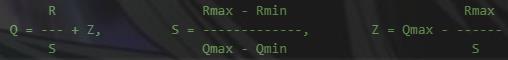
其中,R:真实浮点值(fp32);Q:量化后的定点值(int8,Q属于[-127, 127]);Z:表示0浮点值对应的量化定点值;S:定点量化后可表示的最小刻度。
这种量化方式,主要关注浮点范围的最大值和最小值,然后通过尺度 S 线性映射。这种量化方法往往会使精度下降较多,一般后面还会跟一个 requantize 的微调优化。实际上,把 MinMax 量化应用于网络权重这样静态分布的数据的时候,对于网络推理最后的精度损失影响不大,且量化操作开销更小,量化过程效率更高,这是 Nvidia 经过大量实验得出的结论。
2.2 KLD 量化
KLD 量化是用 KL 散度来衡量两个分布之间的相似性,是 Nvidia TensorRT 中对于激活值采用的量化方法,KLD 量化的示意如下:
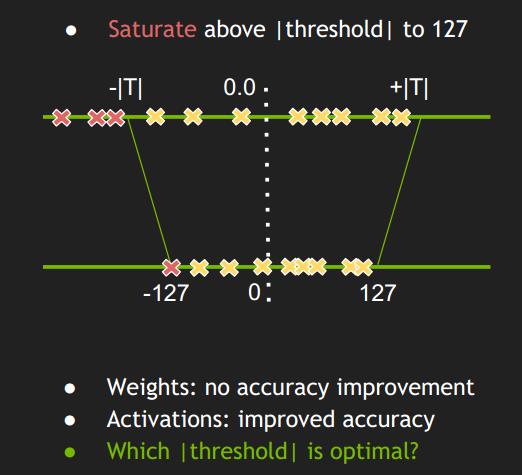
- 这种方法不是直接将 [min, max] 映射到 [-127,127],而是去寻找一个阈值|T| < max(|max|, |min|),将其 [-T, T] 映射到 [-127, 127]。认为只要阈值选取得当,就能将阈值外的值舍弃掉,也不会对精度损失造成大的影响;
- 超出阈值 ±|T| 外的直接映射为阈值。比如上图中的三个红色点,直接映射为-127,这种映射关系为饱和的(Saturate );
KLD 量化方法试图将 fp32 数值分布和 int8 数值分布抽象成两个分布,用阈值 |T| 来更新两个数值分布,并用 KL 散度来衡量两个分布的相似性,若 KL 散度值越小,说明这两个分布越相似,也说明这个阈值 |T| 选择的最好。
下面的图是 TensorRT 中的关于 KL 散度校准的伪代码,这个图也完美诠释了 KLD 整个量化过程。

2.3 ADMM 量化
ADMM 交替方向乘子法,是优化函数的一种方式,一般用于带有约束的最优解问题。类似的,梯度下降法、牛顿下降法、拉格朗日乘子法也是类似的优化方法。
其通用优化式子如下:

在 ADMM 中,其等价的优化式,也就是拉格朗日式如下:

同拉格朗日乘子法不同的是,ADMM 采用的是类似于分布迭代的方式获得最终解。其采用如下的步骤:

下面我们将量化阈值的选取策略变换成 ADMM 算法,利用前面所说的对称量化方法,把量化当成一个编码问题,编码再加上解码,就还原出了可以跟原始数据进行对比的数据。这样的逻辑下,将优化目标设计成如下表达:

2-范式易于求导,那么上述的优化目标可以转换成如下形式:

个人认为在对于对称量化不需要使用 ADMM,因为只有一个变量,使用梯度下降法也是可以得到最终的s。
2.4 EQ 量化
EQ 量化即 EasyQuant,是格灵深瞳开源的量化算法,在文章《EasyQuant: Post-training Quantization via Scale Optimization》中进行了介绍。EQ 量化方法的主要思想是:误差累计、整网决策变成单网决策、以余弦相似度为优化目标、交替优化权重缩放系数和激活值缩放系数。
假设量化公式如下(为了方便起见,采用对称量化进行说明):

假设量化目标精度为 IntN,其中的 clip 函数表示把量化后的数值规范到整型范围,如下:

EQ 量化算法把缩放系数 S 的获得看成数学优化问题,将优化目标进行了如下表达:假设传入的校准集中样本个数为 N、被量化模型的网络层个数为 L,Qil 表示未量化推理时第 l 层网络层的第 i 个样本的输出值,Q^il 表示量化推理时第 l 层网络层的第 i 个样本的输出值,因为误差累计和问题分解的手段,使用余弦相似度作为评判标准,最终的优化目标如下所示:

其中 Qil 和 Q^il 在该层为卷积的时候为:

EQ 算法最大的亮点在于对权重的缩放系数也进行了优化,其他的量化阈值选取策略基本是不考虑对权重的缩放系数进行优化,直接使用 Min-Max 得到缩放系数。加入了权重的缩放系数的优化变量,导致了多变量优化问题。如若按照常规的方式进行多变量优化,该优化目标往往难以解析,EQ 给出的解法是使用交替优化权重激活系数和激活缩放系数。
EQ 算法流程如下:

3、量化实验
这里选取了 KLD 和 ADMM 两种量化算法进行了一些实验模拟。
使用 python numpy 创造随机数据分布,下面均是以正太分布进行试验。对同个分布分别使用 KL 和 ADMM 算法进行阈值计算。
以下是三次试验的结果:

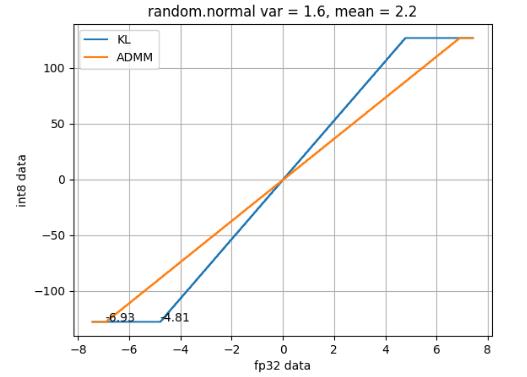
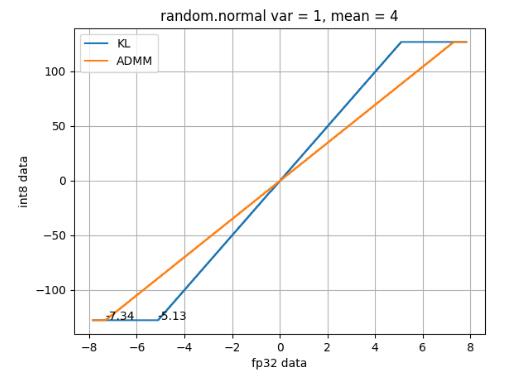
使用 KLD 和 ADMM 算法得到的阈值如下:

实验小结:单从试验结果可知,ADMM 得到的量化阈值总是比 KLD 的量化阈值要高,基本稳定在max(|均值-3 * 标准差|,|均值+ 3 * 标准差|)。按照正太分布的定义,ADMM 的阈值会覆盖 99.99% 分布的数据,因为其优化目标难以忍受太小的阈值,那样会让阈值外的数值量化 + 反量化后误差极大。
以上聊了一下一些量化算法相关的东西,包括量化类型、量化策略以及贴了个试验分析,关于量化是一个实用且值得深挖的领域,有问题欢迎讨论,我也在学习中~
好了,收工~
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理谈谈几种量化策略:MinMaxKLDADMMEQ的主要内容,如果未能解决你的问题,请参考以下文章