深度学习模型量化(低精度推理)大总结
Posted 洪流之源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习模型量化(低精度推理)大总结相关的知识,希望对你有一定的参考价值。
模型量化作为一种能够有效减少模型大小,加速深度学习推理的优化技术,已经得到了学术界和工业界的广泛研究和应用。模型量化有 8/4/2/1 bit等,本文主要讨论目前相对比较成熟的 8-bit 低精度推理。 通过这篇文章你可以学习到以下内容:1)量化算法介绍及其特点分析,让你知其然并知其所以然; 2)Pytorch 量化实战,让你不再纸上谈兵;3)模型精度及性能的调优经验分享,让你面对问题不再束手无策;4)完整的量化文献干货合集,让你全面系统地了解这门主流技术。
1.CPU 推理性能提升 2-4 倍,模型大小降低至1/4,模型量化真的这么好使?
维基百科中关于量化(quantization)的定义是: 量化是将数值 x 映射到 y 的过程,其中 x 的定义域是一个大集合(通常是连续的),而 y 的定义域是一个小集合(通常是可数的)【1】。8-bit 低精度推理中, 我们将一个原本 FP32 的 weight/activation 浮点数张量转化成一个 int8/uint8 张量来处理。模型量化会带来如下两方面的好处:
- 减少内存带宽和存储空间
深度学习模型主要是记录每个 layer(比如卷积层/全连接层) 的 weights 和 bias, FP32 模型中,每个 weight 数值原本需要 32-bit 的存储空间,量化之后只需要 8-bit 即可。因此,模型的大小将直接降为将近 1/4。
不仅模型大小明显降低, activation 采用 8-bit 之后也将明显减少对内存的使用,这也意味着低精度推理过程将明显减少内存的访问带宽需求,提高高速缓存命中率,尤其对于像 batch-norm, relu,elmentwise-sum 这种内存约束(memory bound)的 element-wise 算子来说,效果更为明显。
- 提高系统吞吐量(throughput),降低系统延时(latency)
直观理解,试想对于一个 专用寄存器宽度为 512 位的 SIMD 指令,当数据类型为 FP32 而言一条指令能一次处理 16 个数值,但是当我们采用 8-bit 表示数据时,一条指令一次可以处理 64 个数值。因此,在这种情况下,可以让芯片的理论计算峰值增加 4 倍。在CPU上,英特尔至强可扩展处理器的 AVX-512 和 VNNI 高级矢量指令支持低精度和高精度的累加操作,详情可以参考文献【2】。
2.量化设计
按照量化阶段的不同,一般将量化分为 quantization aware training(QAT) 和 post-training quantization(PTQ)。QAT 需要在训练阶段就对量化误差进行建模,这种方法一般能够获得较低的精度损失。PTQ 直接对普通训练后的模型进行量化,过程简单,不需要在训练阶段考虑量化问题,因此,在实际的生产环境中对部署人员的要求也较低,但是在精度上一般要稍微逊色于 QAT。本文介绍的主要方法也是针对 PTQ 。关于 QAT 的内容,因为理论较为复杂,我打算后续重新写一篇文章详细介绍。
在介绍量化算法之前,我们先看一下浮点数和 8-bit 整数的完整表示范围。

表1 数据表示范围
量化算法负责将 FP32 数据映射到 int8/uint8 数据。实际的 weight/activiation 浮点数动态范围可能远远小于 FP32 的完整表示范围,为了简单起见,在下面的量化算法介绍中,我们直接选取 FP32 张量的最大值(max)和最小值(min)来说明量化算法,更为详细的实际动态范围确定方法将在后续部分说明。量化算法分为对称算法和非对称算法,下面我们主要介绍这两种算法的详细内容及其区别。
- 非对称算法 (asymmetric)
如下图所示,非对称算法那的基本思想是通过 收缩因子(scale) 和 零点(zero point) 将 FP32 张量 的 min/max 映射分别映射到 8-bit 数据的 min/max。

图1. 非对称算法示意图
如果我们用 x_f 表示 原始浮点数张量, 用 x_q 表示量化张量, 用 q_x 表示 scale,用 zp_x 表示 zero_point, n 表示量化数值的 bit数,这里 n=8, 那么非对称算法的量化公式如下:

公式1. 非对称算法公式
上述公式中引入了 zero_point 的概念。它通常是一个整数,即 zp_x= rounding(q_x * min_x_f)。因此,在量化之后,浮点数中的 0 刚好对应这个整数。这也意味着 zero_point 可以无误差地量化浮点数中的数据 0,从而减少补零操作(比如卷积中的padding zero)在量化中产生额外的误差【3,4】。
但是,从上述公式我们可以发现 x_q 的结果只能是一个非负数,这也意味着其无法合理地处理有符号的 int8 量化,Pytorch 的处理措施是将零点向左移动 -128,并限制其在 [-128,127] 之间【5】。
- 对称算法(symmetric)
对称算法的基本思路是通过一个收缩因子(scale)将 FP32 tensor 中的最大绝对值映射到 8-bit数据的最大值,将最大绝对值的负值映射到 8-bit 数据的最小值。以 int8 为例,max(|x_f|)被映射到 127,-max(|x_f|)被映射到-128。 如下图所示:

图2. 对称算法示意图
与非对称算法相比,对象算法一般不采用 zero_point, 其量化公式如下:

公式2. 对称算法公式
如果 FP32 张量的值能够大致均匀分布在 0 的左右,这种算法将数值映射到 int8 数据之后也能均匀的分布在 [-128, 127]之间。 但是对于分布不均与的 FP32 张量,量化之后将不能够充分利用 8-bit 的数据表示能力。
- 对称算法 VS 非对称的算法
非对称算法一般能够较好地处理数据分布不均与的情况,为了验证这个问题,我们用 python 做了一个小实验。FP32 原始数据均匀分布在 [-20, 1000],这也意味着数据分布明显倾向于正数一方。下图展示了实验结果。从图中可以看出,对于这种FP32 数据分布不均匀的情况下,对称算法的量化数据分布与原始数据分布相差很大。由对称算法(symmetric)产生的 量化数据绝大部分都位于[0,127] 这个表示范围内,而 0 的左侧有相当于一部分范围内没有任何的数据。int8 本来在数据的表示范围上就明显少于 FP32,现在又有一部分表示范围没发挥左右,这将进一步减弱量化数据的表示能力,影响量化模型的精度。与之相反,非对称算法(asymmetric)则能较好地解决 FP32 数据分布不明显倾向于一侧的问题,量化数据的分布与原始数据分布情况大致相似,较好地保留了 FP32 数据信息。

图3. 对称算法 VS 非对称算法
- 引入 zero-point 对算子的影响
卷积(convolution(Conv))和全连接(fully-connected (FC))中的主要操作都是乘加。为了简化问题说明,我们这里将其具体实现形式简化成乘加。以 y_f 表示浮点数输出,y_q 表示量化输出, b_f 表示浮点数偏置。在低精度模式下,CPU 的计算过程中一般过程是两个量化数据乘加之后先还原到 FP32 高精度,然后再量化成低精度。
对称算法的计算过程如下:

公式3. 对称算法的量化计算还原到 FP32 的过程

公式4. 对称算法 requantization 过程
非对称算法的计算过程如下:

公式5. 非对称算法量化计算还原到 FP32 的过程

公式6. 非对称算法 requantization 过程
从上面的对比我们不难看出带有 zero_point 的非对称量化算法在计算的时候将会多出来如下三项计算:
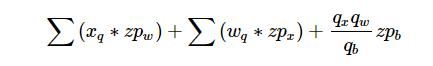
公式7. 引入 zero_piont 多出来的计算项
这也意味着多余的乘加操作将会降低 asymmetric 算法的性能。其中最后一项为常量,由于在推理的时候 weights 是常量,第二项也可以离线计算。为了优化这部分操作,很多加速库都做了不同的处理详情可以参照文献【6,7】。
如果看过 Pytorch 量化算法实现,你一定很疑惑为什么它的的 symmtric 量化算法也采用了zero_point。这个其实也不难理解,我们回头看一下 symmtric 算法的量化公式,如果量化类型为 uint8,FP32数据均匀分布在零点左右,这个公式将会把很多原来为负值的 FP32 数据都量化成 0,只保留了原有FP32中非负数部分的量化数据。 Pytorch 的操作相当于显示地利用 zero_point 将 rounding 之前的量化结果直接往右移动了 128,从而保留了FP32中负数部分的数据。因此,我个人认为这是 Pytorch 对这种特定场景的一种优化。
- 浮点数动态范围的选取
从上面对两种量化算法的介绍我们不难发现,为了计算 scale 和 zero_point 我们需要知道 FP32 weight/activiation 的实际动态范围。对于推理过程来说, weights 是一个常量张量,不需要额外数据集进行采样即可确定实际的动态范围。 但是 activation 的实际动态范围则必须经过采样获取(一般把这个过程称为数据校准(calibration) )。目前各个深度学习框架中,使用最多的有最大最小值(MinMax), 滑动平均最大最小值(MovingAverageMinMax) 和 KL 距离(Kullback–Leibler divergence) 三种。如果量化过程中的每一个 FP32 数值都在这个实际动态范围内,我们一般称这种为不饱和状态;反之如果出现某些 FP32 数值不在这个实际动态范围之内我们称之为饱和状态。
最大最小值(MinMax)
这是最简单也是使用比较多的一种采样方法。它的基本思想是直接从 FP32 张量中选取最大值和最小值来确定实际的动态范围,如下公式所示。

公式8. MinMax
对 weights 而言,这种采样方法是不饱和的。对于 activation 而言,在采样数据部分是不饱和的,但是如果验证集中出现实际动态范围之外的数据,则会出现饱和现象。这种算法的优点是简单直接,但是对于 activation 而言,如果采样数据中出现离群点,则可能明显扩大实际的动态范围,比如实际计算时 99% 的数据都均匀分布在[-100, 100]之间,但是在采样时有一个离群点的数值为10000,这时候采样获得的动态范围就变成[-100, 10000]。
滑动平均最大最小值(MovingAverageMinMax)
与 MinMax 算法直接替换不同,MovingAverageMinMax 会采用一个超参数 c (Pytorch 默认值为0.01)逐步更新动态范围。

公式9. MovingAverageMinMax
这种方法获得的动态范围一般要小于实际的动态范围。对于 weights 而言,由于不存在采样的迭代,因此 MovingAverageMinMax 与 MinMax 的效果是一样的。
KL 距离采样方法(Kullback–Leibler divergence)【8】
量化是对原始 FP32数据的一种重新编码。一般认为量化之后的数据分布与原始分布越相似,量化对原始数据信息的损失也就越小。KL 距离一般被用来度量两个分布之间的相似性。其基本公式如下:
![]()
公式10. KL 距离公式
其中P,Q表示两个不同的分布。
动态范围的选取直接决定了量化数据的分布情况,处于动态范围之外的数据将被映射成量化数据的边界点。如下图所示,横坐标表示activation 的取值,纵坐标表示每个取值的归一化统计个数。从图可以看出绝大部分数值都分布在白色直线的左端。通过 KL 距离采样方法就会将动态范围限制在白线左侧的部分,白线右边的值将都会被映射成量化数据的最大值。
图4. KL 距离动态范围选取例子
KL 距离采样方法通过直方图来模拟两个分布。其伪代码如下:
1 Input: FP32 histogram H with 2048 bins: bin[ 0 ], …, bin[ 2047 ]
2 For i in range( 128 , 2048 ):
3 reference_distribution_P = [ bin[ 0 ] , ..., bin[ i-1 ] ] // take first ‘ i ‘ bins from H
4 outliers_count = sum( bin[ i ] , bin[ i+1 ] , … , bin[ 2047 ] )
5 reference_distribution_P[ i-1 ] += outliers_count
6 P /= sum(P) // normalize distribution P
7 candidate_distribution_Q = quantize [ bin[ 0 ], …, bin[ i-1 ] ] into 128 levels // explained later
8 expand candidate_distribution_Q to ‘ i ’ bins // explained later
9 Q /= sum(Q) // normalize distribution Q
10 divergence[ i ] = KL_divergence( reference_distribution_P, candidate_distribution_Q)
11 End For
12 Find index ‘m’ for which divergence[ m ] is minimal
13 threshold = ( m + 0.5 ) * ( width of a bin )我们来看一下上述伪代码,第 1 行表示将所有的浮点数值放入 2048 个直方桶里,13行表示通过桶的位置来确定数据的动态范围。
假设我们选第 i 个桶对应的值作为动态范围的右端边界。动态范围右边的数据都被映射到量化边界点,因此动态范围右边的数据被统一放到了第 i-1 个桶里。 因为 KL 距离要求两个分布必须相同的元素个数,第 8 行对候选分布进行了扩充操作。
下面用一个简单的例子我们看一下第 7 行的 quantize 操作以及第 8 行的 expand 操作:
假设 P 有 8 个桶,quantize 之后有两个桶。quantize 不是桶上面介绍的量化公式来计算的,而是通过合并操作来处理。因为 8/2=4,所以相邻的4个桶会合并成一个,即:
P = [ 1, 0, 2, 3, 5, 3, 1, 7] =》[1 + 0 + 2 + 3 , 5 + 3 + 1 + 7] = [6, 16]
所以 candidate_distribution_Q=[6,16]。因为 P 有 8 个元素,我们必须将 candidate_distribution_Q 也转换成 8 个元素才能计算 KL 距离。在转换的过程中,原始 P 中为 0 的位置仍将为0。然后统计每个部分的非零个数作为转换系数。因为 P 的前4个元素有3个非零值,后四个元素有4个非零值,所以:
Q = [ 6/3, 0, 6/3, 6/3, 16/4, 16/4, 16/4, 16/4] = [ 2, 0, 2, 2, 4, 4, 4, 4]
文献【8】对 activiation 推荐尝试使用这种算法。
总结一下:从上面的复杂介绍中我们可以看出: KL 距离采样方法从理论上似乎很合理,但是也有几个缺点:1)动态范围的选取相对耗时。2)上述算法只是假设左侧动态范围不变的情况下对右边的边界进行选取,对于 RELU 这种数据分布的情况可能很合理,但是如果对于右侧数据明显存在长尾分布的情况可能并不友好。除了具有像RELU等这种具有明显数据分布特征的情况,其他情况我们并不清楚从左边还是从右边来确定动态范围的边界。3)quantize/expand 方法也只是一定程度上模拟了量化的过程。
- 量化粒度
量化粒度一般分为 张量级量化(tensor-wise)和 通道级量化 (channel-wise)。Tensor-wise 量化为一个张量指定一个 scale,是一种粗粒度的量化方式。Channel-wise 量化为每一个通道指定一个 scale 属于一种细粒度的量化方式。
张量级量化(tensor-wise/per_tensor/per_layer)
Activation 和 weights 都可以看做是一个张量,因此在这种量化方式,两者并没有区别。
通道级量化(channel-wise/per_channel)
在深度学习中,张量的每一个通道通常代表一类特征,因此可能会出现不同的通道之间数据分布较大的情况。对于通道之间差异较大的情况仍然使用张量级的量化方式可能对精度产生一定的影响,因此通道级量化就显得格外重要。
对于 activation 而言,在卷积网络中其格式一般为 NCHW。其中 N 为 batch_size,C 为通道数,H 和W分别为高和宽。这时量化将会有C个 scale,即以通道为单位进行量化。
对于 weights 而言,在卷积网络中其格式一般为 OIHW,其中 O 为输出通道数, I 为输入通道数,H 和 W分别为卷积核高和宽。这时量化将会有 O 个scale,即以输出通道为单位进行量化。
对比分析
在卷积网络中,一般建议对 weights 进行通道级的量化会取得较好地实验结果。下图展示了文献【3】在一些主流卷积网络上的实验结果,这里 activation 选择了张量级量化,实验对比了 weights 采用不同的量化方法时的精度情况。从对比结果可以看出 weights 采用非对称通道级量化时可以获得较低的精度损失。

表2. weights选用不同量化算法对精度的影响
- Calibration
上文我们提到,为了获取 activation 的 scale 和 zero_point 数据,我们必须对 FP32 推理的样本数据采样,这个过程一般就称为 calibration。 文献【8】中建议使用 1000 个左右的样本进行 calibration。
3. Pytorch 模型量化实战
第2部分我们详细介绍了量化设计所涉及的算法已经calibration 的过程。这部分我们首先介绍 pytorch 量化的基本步骤,然后通过 Pytorch 提供的 API 来展示 resnet50 这个卷积网络的量化过程及其实验结果。
- 不得不谈的 torch.nn.Module 类
torch.nn.Module 类是所有神经网络模型的基类。一个模块可以包含子模块,通常一个神经网络模型也是一个模块,它以树状结构来组织各个子模块。比如,一个 resnet50 模型是一个模块,一个torch.nn.Conv2d 算子也可以封装成一个模块。下面的一个例子展示了一个含有两个卷积操作的简单模型。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))Model 本身也是 Module 类的子类,Module 类的子类都需要定义 __init_ 和 forward,前者定义子类的树状结构,后者定义计算逻辑。

图5. Model 的树状结构图
从上面打印出的模型树状结构可以看到 forward 中使用的算子可能不一定在 __init__ 定义的树状结构中,比如 relu 就没有出现在 Model 的树状结构中。这也意味着程序无法直接 __init__ 定义的模型类结构中判断该模型的完整算子列表。
- Pytorch Post-training 量化的基本步骤【9】
对于一个已经训练好的模型,post-training 量化的基本步骤如下:
1)准备模型:
插桩:在需要 quantize 和 dequantize 操作的 module 中插入 QuantStub 和DeQuantStub。
去重: 保证每一个 module 对象不能被重复使用,重复使用的需要定义多个对象,比如 一个 nn.relu 对象不能在 forward 中使用两次,否则在 calibration 阶段无法观测正确的浮点数动态范围。。
转换:非 module 对象表示的算子不能转换成 quantized module。比如 "+" 算术运算符无法直接转成 quantize module。
2)fuse modules
为了提高精度和性能,一般将 conv + relu, conv + batchnorm + relu, linear + relu 等类似的操作 fuse 成一个操作。
3)设置量化算法
为 activations/weights 指定量化算法 比如 symmtric/asymmtric/minmax 等等。Pytorch 采用 qconfig 来封装量化算法,一般通过将 qconfig 作为 module 的属性来指定量化算法。常用的 qconfig 有 default_per_channel_qconfig, default_qconfig等,详情可以参考文献【9】。
4)传播 qconfig 和插入 observer
通过 torch.quantization.prepare() 向子 module 传播 qconfig,并为子 module 插入 observer。 Observer 可以在获取 FP32 activations/weights 的动态范围。
5) calibration
运行 calibration 推理程序搜集 FP32 activations 的动态范围。
6)module 转化
通过 torch.quantization.convert 函数可以将 FP32 module 转化成 int8 module. 这个过程会量化 weights, 计算并存储 activation 的 scale 和 zero_point。
- Pytorch 量化 resnet50
下面我们通过 torchvision 【11】中的 resnet50 模型拉说明上述量化步骤的具体使用,并通过实验数据展示量化对模型大小和推理性能的影响。
模型准备
下面的代码分别展示了 FP32 的 Bottoleneck 和修改后可以用于量化 QuantizableBottoleneck。后者是前者的子类。由于 relu 在 forward 调用了两次,因此,在calibration过程中不能够正确绑定 observer,子类改成成定义 relu1 和 relu2 两个对象。同时out += identity 中 "+=" 是一个无状态的运算符,需要替换成 nn.quantized.FloatFunctional()。同时子类还定义了 fuse_model 函数用于 fuse 符合特定模式的算子序列为一个算子(参看torchvision/models/quantization/resnet.py 和rchvision/models/resnet.py)。
class Bottleneck(nn.Module):
expansion = 4
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class QuantizableBottleneck(Bottleneck):
def __init__(self, *args, **kwargs):
super(QuantizableBottleneck, self).__init__(*args, **kwargs)
self.skip_add_relu = nn.quantized.FloatFunctional()
self.relu1 = nn.ReLU(inplace=False)
self.relu2 = nn.ReLU(inplace=False)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out = self.skip_add_relu.add_relu(out, identity)
return out
def fuse_model(self):
fuse_modules(self, [['conv1', 'bn1', 'relu1'],
['conv2', 'bn2', 'relu2'],
['conv3', 'bn3']], inplace=True)
if self.downsample:
torch.quantization.fuse_modules(self.downsample, ['0', '1'], inplace=True)
同时,由于resnet50整个模型中的算子都可以转换成int8操作,因此只需要插入一对 QuantStub 和 DeQuantStub。
class QuantizableResNet(ResNet):
def __init__(self, *args, **kwargs):
super(QuantizableResNet, self).__init__(*args, **kwargs)
self.quant = torch.quantization.QuantStub()
self.dequant = torch.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
# Ensure scriptability
# super(QuantizableResNet,self).forward(x)
# is not scriptable
x = self._forward_impl(x)
x = self.dequant(x)
return x
def fuse_model(self):
r"""Fuse conv/bn/relu modules in resnet models
Fuse conv+bn+relu/ Conv+relu/conv+Bn modules to prepare for quantization.
Model is modified in place. Note that this operation does not change numerics
and the model after modification is in floating point
"""
fuse_modules(self, ['conv1', 'bn1', 'relu'], inplace=True)
for m in self.modules():
if type(m) == QuantizableBottleneck or type(m) == QuantizableBasicBlock:
m.fuse_model()
Calibration 和模型转换
if args.post_training_quantize:
# perform calibration on a subset of the training dataset
# for that, create a subset of the training dataset
ds = torch.utils.data.Subset(
dataset,
indices=list(range(args.batch_size * args.num_calibration_batches)))
data_loader_calibration = torch.utils.data.DataLoader(
ds, batch_size=args.batch_size, shuffle=False, num_workers=args.workers,
pin_memory=True)
model.eval()
model.fuse_model()
torch.save(model.state_dict(), "fp32_resnet_50.modle")
evaluate(model, criterion, data_loader_test, device=device)
model.qconfig = torch.quantization.get_default_qconfig(args.backend)
torch.quantization.prepare(model, inplace=True)
# Calibrate first
print("Calibrating")
evaluate(model, criterion, data_loader_calibration, device=device, print_freq=1)
torch.quantization.convert(model, inplace=True)
if args.output_dir:
print('Saving quantized model')
if utils.is_main_process():
torch.save(model.state_dict(), os.path.join(args.output_dir,
'quantized_post_train_model.pth'))
print("Evaluating post-training quantized model")
torch.save(model.state_dict(), "int8_resnet_50.modle")
evaluate(model, criterion, data_loader_test, device=device)
return参看:references/classification/train_quantization.py。其中torch.utils.data.Subset 表示从数据集中选取一部分数据作为 calibration 数据集。
实验结果
模型大小 :

图6. 模型大小的变化
精度和性能变化:

图7. FP32 模型的性能和精度

图8. 量化模型的精度和性能
从上述实验结果可以看出模型大小从 98M 下降到 25M,因此 int8 model 大约为 FP32 model 的 1/4。此外模型的 top1 精度 从73.990下降为73.960。模型的性能从 FP32 耗时6分49秒下降到2分08秒,性能提升 3X。 这些结果也验证了我们开篇提到的量化效果。
实验重现步骤
git clone https://github.com/pytorch/vision.git
cd vision
python references/classification/train_quantization.py --data-path='xxx/imagenet/img/' --device='cpu' --test-only --backend='fbgemm' --model='resnet50' --post-training-quantize
4.经验分享
- 精度问题
由于 8-bit 整数的动态表示范围明显低于 FP32 浮点数,在模型量化的时候通常会出现精度不达标的问题。下面我们分一下几种情况来分析精度问题:
精度损失距离目标精度差别较小
这种情况下一般可以排除代码实现问题, 可以通过尝试不同的量化算法来改进精度。此外,如果已知有些算子 activation 数据分布比较特殊,也需要做一些特殊处理。
精度损失较大
首先, 要排除实现的 bug 问题,在排查过程中可以采用逐层替换的方式。比如,从前往后逐层将 FP32 算子替换成量化算子,观察精度的变化情况。这里有一点需要特别注意,Pytorch 中 QuantStub本身也是module,同一个该类型的对象也不能在 forward 使用多次,否则也会造成精度问题。
其次,除了实现 bug 之外,精度也可能是由于某几层的影响造成的,此时为了精度考虑,我们也可以考虑将这几层影响较大的层回退到 FP32 进行处理。
再者, 从算子层面考虑,如果我们已经知道某层的影响较大,我们可以通过对比量化前后的数据分布情况来探究根本原因。
- 性能问题
量化的目的就是在保证精度损失可控的情况下尽量提高性能。分析性能时,我们可以采用分解的方式查看每个算子的时间消耗占比情况。比如,pytorch 提供了 torch.autograd.profiler.profile() 工具,这个函数可以帮助我们分析每一个算子的时间消耗占比情况,通过这个占比情况我们就可以看出模型的性能瓶颈点。得知瓶颈位置之后,我们可以通过查看算子的源码实现或者借助 Vtune 等分析工具来查看为什么这个算子时间消耗这么高。比如,笔者在做某个 NLP 模型时,就发现 pytorch 1.3 版本的dequantize/quantize 算子耗时较高,后来通过 vtune 工具发现这两个算子在向量化和并行化上都没有做好,于是我们可以借助 SIMD, openMP 等来提高算子的效率可以参照文献【10】。
- sky-lake CPU 溢出问题
文献【2】 中提到,在 sky-lake CPU 上,指令在计算时 u8 * s8 = s16 可能存在溢出问题。 FBGEMM 的官方 github 上也有一个相关的 issue【15】。为了解决这个问题,pytorch 的 quantization 算法在实现时,引入了一个 reduce_range 的标志,如果 reduce_range = True (默认为 True)则表示只采用 7-bit 来表示量化整数。这时需要注意的是,在 cascade-lake 及其以后的机型中并不存在这个问题,这是如果强行置为 True 很可能会降低模型的精度。因此如果你发现你的精度有损失,不妨可以先检查一下这个标志位的值。
5.目前有哪些针对低精度推理的工具包?
- 深度学习框架
目前主流的深度学习框架基本上都支持量化,比如 Pytorch, TensorFlow, Caffe, Mxnet, PaddlePaddle等等。
- 加速包
- MKLDNN/MKL
- FBGEMM
- TensorRT
- QNNPACK
6.总结
上面我们介绍了各种量化的方法及其优缺点,并通过实验验证了量化对精度和性能的影响。看完这篇文章希望大家已经能够动手实施模型量化工作,有什么问题也欢迎在评论去留言。
7.参考文献
1.Quantization wikipedia
https://en.wikipedia.org/wiki/Quantization_(signal_processing)
2.低数值精度深度学习推理与训练
https://software.intel.com/zh-cn/articles/accelerate-lower-numerical-precision-inference-with-intel-deep-learning-boost
3.Quantization Algorithms
https://nervanasystems.github.io/distiller/algo_quantization.html
4.Quantizing deep convolutional networks for efficient inference: A whitepaper
https://arxiv.org/abs/1806.08342
5.Pytorch observer 实现
https://github.com/pytorch/pytorch/blob/master/torch/quantization/observer.py
6.GMMLOMP
https://github.com/google/gemmlowp/blob/master/doc/quantization.md#implementation-of-quantized-matrix-multiplication
7.FBGEMM
https://engineering.fb.com/ml-applications/fbgemm/
https://github.com/pytorch/FBGEMM
8.8-bit Inference with TensorRT
http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
9.Pytorch Quantization Introduction
https://pytorch.org/docs/stable/quantization.html#quantization-workflows
10.性能问题
https://github.com/pytorch/pytorch/pull/30153
11.Pytorch tutorial
https://pytorch.org/tutorials/
12.Torchvision
https://github.com/pytorch/vision/tree/master/torchvision/models
13.Introduction to quantization
https://pytorch.org/docs/stable/quantization.html
14.What Is int8 Quantization and Why Is It Popular for Deep Neural Networks?
https://www.mathworks.com/company/newsletters/articles/what-is-int8-quantization-and-why-is-it-popular-for-deep-neural-networks.html
15.sky-lake 溢出问题
https://github.com/pytorch/FBGEMM/issues/125
其它量化文章:
以上是关于深度学习模型量化(低精度推理)大总结的主要内容,如果未能解决你的问题,请参考以下文章