量化感知训练实践:实现精度无损的模型压缩和推理加速
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了量化感知训练实践:实现精度无损的模型压缩和推理加速相关的知识,希望对你有一定的参考价值。
简介:本文以近期流行的YOLOX[8]目标检测模型为例,介绍量化感知训练的原理流程,讨论如何实现精度无损的实践经验,并展示了量化后的模型能够做到精度不低于原始浮点模型,模型压缩4X、推理加速最高2.3X的优化效果。
1. 概述
对深度学习模型进行低比特量化,可以有效地降低模型部署时在存储、计算、通信上的开销,是一种常见的模型压缩和推理优化技术。然而,模型量化在实际应用中仍然存在不少挑战,最为常见的问题就是模型精度下降(如无特殊说明,本文中“模型精度”是指准确率等模型应用于具体任务的效果指标)。以计算机视觉领域为例,在目标检测、图像分割等复杂任务上,量化带来的精度下降更为明显。
通过在模型训练阶段引入量化相关约束,即量化感知训练(Quantization-aware training,QAT),能够更好地解决模型量化的精度问题。本文以近期流行的YOLOX[8]目标检测模型为例,介绍量化感知训练的原理流程,讨论如何实现精度无损的实践经验,并展示了量化后的模型能够做到精度不低于原始浮点模型,模型压缩4X、推理加速最高2.3X的优化效果。
2. 量化原理
在数字信号处理领域,量化是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。具体到深度学习领域,模型量化是指将浮点激活值或权重(通常以32比特浮点数表示)近似为低比特的整数(16比特或8比特),进而在低比特的表示下完成计算的过程。通常而言,模型量化可以压缩模型参数,进而降低模型存储开销;并且通过降低访存和有效利用低比特计算指令等,能够取得推理速度的提升,这对于在资源受限设备上部署模型尤为重要。
给定浮点类型的值,可以通过如下公式将它转化成8比特量化值:

其中,表示量化的scale, 与
与 分别表示量化值域的最小值与最大值,
分别表示量化值域的最小值与最大值, 表示输入浮点值,
表示输入浮点值, 表示量化后的值。量化值转化为浮点值只需执行反操作即可:
表示量化后的值。量化值转化为浮点值只需执行反操作即可:

进一步的,在将输入数据和权重进行量化后,我们就能够将神经网络的常见操作转换为量化操作。以卷积操作为例,其量化版本典型的计算流程如图1所示:

图1 典型的量化卷积算子计算流程图
- 权重与输入先量化成8bit,进行卷积操作,用32bit来存储中间结果;
- bias量化为32bit,与进行相加为
 ;
; - 利用、
 以及
以及 的量化scale将32bit的转化为8bit的
的量化scale将32bit的转化为8bit的 ;
; - 如果该层的下一层也是量化OP,则可直接输出给下一层;如果是非量化OP,则将反量化为浮点值后,再输出给下一层。
从上述量化计算的原理能够容易看出,将浮点数转化为低比特整数进行计算会不可避免地引入误差,神经网络模型中每层量化计算的误差会累积为模型整体精度的误差。常见的训练后量化(Post Training Quantization,PTQ)方案中,通过统计在典型输入数据情况下,待量化变量的数值分布,来选择合适的量化参数(scale,zero point等),将因量化而引入的信息损失降低到最小。
但是PTQ方案往往还是无法实现精度无损的模型量化,为了进一步降低量化带来的精度下降,我们可以采用量化感知训练的方案,在训练的计算图中引入伪量化的操作,通过微调训练(finetuning)让模型权重“适应”量化引入的误差,以实现更好的、甚至无损的量化模型精度。
3. YOLOX量化训练
我们以YOLOX-s目标检测模型(GitHub repo[1])为例,使用公开的预训练模型参数,在COCO2017数据集上进行量化训练实验。量化训练算法选择LSQ[2,3],该系列算法利用梯度来更新量化的scale与zero_point,在不需要精细调节参数的情况下能够获得较好的性能。为了通过量化训练获得更好的量化模型精度,我们需要重点关注如下几点设置:
3.1 与部署后端相匹配的量化方式
不同的部署后端,可能采用不用的量化计算实现方式,需要匹配训练和部署阶段的量化方式以避免引入额外误差。以PyTorch[7]默认的CPU后端为例,基本的量化方式为
- weight: per-channel,int8,对称量化
- activation: per-tensor,uint8,非对称量化
- 量化对象: 所有的Conv2d
以移动端框架MNN为例,基本的量化方式为:
- weight: per-channel,int8,对称量化
- activation: per-tensor,int8,对称量化
- 量化对象: 所有的Conv2d
通常在具体推理框架上部署量化模型时,还会对类似conv-bn、conv-relu/relu6、conv-bn-relu/relu6这样的卷积层进行算子融合,因此需要设置为量化融合后的activation。YOLOX中的SiLU激活函数通常不会被融合,output activation的量化仅需要设置到bn的输出,而不是SiLU的输出。训练时一个典型的卷积层量化位置如图2所示。
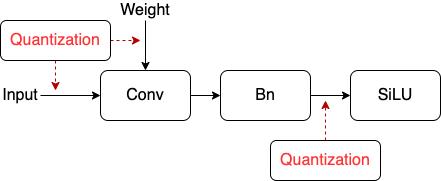
图2 量化位置示意图
同时,QAT时所有的BN全部fold入相应的卷积中,实验采取了文献[6]中的fold策略。由于模拟量化的引入可能会使得BN层的running_mean与running_var不稳定,从而导致量化训练无法收敛。因此,我们在量化训练中固定BN的running_mean与running_var。
此外,特定部署后端的实现可能需要将activation量化为7bit数值范围,以防止计算溢出。带有avx512_vnni指令集的CPU型号上,则没有相应要求。
3.2 量化训练参数初始化
为了避免导致训练loss不稳定甚至训练发散的情况,我们利用训练后量化(Post training quantization,PTQ)所得的量化参数来初始化LSQ量化训练中activation scale参数。基本的步骤是:
- 选取几十张典型图片,在预训练模型上进行推理,并收集统计各个待量化的activation信息。
- 使用如MSE、KL散度等metric来计算各activation的最佳scale。
基本的实现方式可以使用PyTorch的HistogramObserver计算activation scale & zero point,PerChannelMinMaxObserver计算weight scale。
3.3 训练超参数
在QAT阶段,我们使用已经收敛的预训练模型权重,并且使用PTQ量化参数进行QAT初始化。这种情况下,模型参数已接近收敛,因此我们将整体训练的超参数和原始YOLOX训练保持一致,将学习率设置为原始训练收敛阶段的学习率,即5e-4。
3.4 特定后端算子实现的计算误差
因为数值表示精度问题,round操作的结果在训练框架与推理后端上可能并不是相同的,例如:
import torch
torch.tensor(2.5).cuda().round() # 输出tensor(2., device='cuda:0')
torch.tensor(3.5).cuda().round() # 输出tensor(4., device='cuda:0')
2.5和3.5的四舍五入行为在PyTorch上并不是相同的,而该行为差异在常见的部署后端框架上可能不存在。这种问题会导致QAT模拟精度和后端实际运行时的精度存在明显差异,因此需要在量化训练阶段进行修正。例如针对MNN后端,我们可以采取如下操作来避免这个差异。
def round_pass(x):
"""
A simple way to achieve STE operation.
"""
# y = torch.round(x) # for PyTorch backend
y = (x + torch.sign(x) * 1e-6).round() # for mnn backend, round前添加一个小的数值
y_grad = x
return (y - y_grad).detach() + y_grad
4. 实验结果与分析
4.1 精度和加速效果
按照上述方式在YOLOX-s模型上进行量化训练,使用COCO2017 validation set进行精度验证,结果如表1所示。两种后端上真实量化的模型的精度性能均和浮点模型齐平。
| 量化方式 | 模型 (YOLOX-s) | mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 |
| - | 浮点模型 | 40.5 | 59.3 | 43.8 |
| 权重:对称量化 激活值:对称量化 | PTQ | 39.3 | 58.5 | 43.0 |
| QAT | 40.8 | 59.9 | 44.1 | |
| 真实量化模型 | 40.6 | 59.7 | 44.2 | |
| 权重:对称量化 激活值:非对称量化 | PTQ | 39.9 | 58.9 | 43.2 |
| QAT | 40.7 | 59.8 | 43.9 | |
| 真实量化模型 | 40.5 | 59.8 | 43.7 |
表1 浮点模型、QAT模型及后端真实量化模型的精度对比
速度实验中,我们选取PyTorch[7]后端及x86测试平台进行测试,测试的图片分辨率为1x3x640x640。不同资源数下的结果如表2所示。在精度无损的前提下,量化模型的推理速度最高可以提升2.35x,同时模型尺寸为原来的1/4。
| 后端 | 浮点速度 (ms) | 量化速度 (ms) | 加速比 | 设备 | 线程数 |
| PyTorch | 321.2 | 189.9 | 1.70x | Intel(R) Xeon(R) Platinum 8369HC CPU @ 3.30GHz | 1 |
| 218.3 | 106.2 | 2.06x | 2 | ||
| 117.3 | 57.7 | 2.03x | 4 | ||
| 75.3 | 34.1 | 2.21x | 8 | ||
| 57.9 | 24.7 | 2.35x | 16 |
表2 浮点模型、QAT模型及后端真实量化模型的速度对比
4.2 量化参数初始化的影响
LSQ及LSQ+论文中提出了相应的量化信息初始化方法,实际使用中会发现该种初始化方法对于学习率的设定会比较敏感。一方面,若量化参数的初始值距离收敛值较远,需要通过设置较大的学习率来训练他们。另一方面,较大的学习率会使得模型本身参数跳出已收敛的状态,使得模型进入“重训练”的状态,不确定性增加。而用PTQ来初始化量化参数,可以使得参数处于较优的初始状态,利用浮点模型收敛时的学习率去进行finetune即可获得较好的性能。固定学习率为4e-5的前提下,PTQ及LSQ初始化的训练结果与曲线如图4所示。LSQ初始化的训练曲线在开启mossac数据增强时是逐渐向下的,而PTQ初始化是逐渐向上的。

图4 固定finetune学习率下,不同初始化方法的训练曲线
4.3 训练超参数的影响
学习率的设定会直接影响到最终QAT模型的性能。以原始模型训练收敛阶段的学习率(5e-4)为基准,如果QAT阶段使用相同的学习率,QAT初期的模型精度会逐渐下降,如图4中PTQ初始化红色曲线训练早期所示,但是最终精度会提升至原始非量化模型的水平。如果QAT使用更低学习率(例如5e-4),模型精度会相比于PTQ初始化状态逐渐上升,但是最终精度提升不大:
| 学习率 | mAP@50:95 | |
| Baseline | - | 40.8 |
| PTQ | - | 39.4 |
| QAT | 5e-6 | 39.9 |
| QAT | 7.5e-6 | 39.8 |
| QAT | 2.5e-6 | 39.8 |
上述现象的一种可能原因是,在小学习率下模型权重、量化scale基本不变。实际上是基于PTQ的初始解空间继续向局部更好的收敛点靠近,跳出局部解空间的可能性较低。因此,在PTQ初始化的前提下,学习率可以直接设置成浮点模型训练收敛阶段的值。
4.4 训练轮数的选择
上述QAT的结果是训练300 epochs后的模型,减少训练epoch数量的结果,如下所示:
| 学习率 | AP @50:95 | mAP @0.5 | mAP @0.75 | |
| QAT(300 epoch) | 5e-4 | 40.8 | 59.9 | 44.1 |
| QAT(15 epoch) | 5e-4 | 39.6 | 58.5 | 43.3 |
| QAT(30 epoch) | 5e-4 | 39.8 | 58.8 | 43.0 |
可以看出随着训练轮数的增大,QAT的结果会更好。QAT训练轮数较低,结果会不如直接用小学习率进行finetune。我们可以得出经验性的trade-off:如果计算资源充足,可以选择训练更长的时间来获得更好的性能。如果计算资源较少,则可以用小学习率训练较短的时间,以获得高于PTQ的性能。
4.5 修正特定算子计算误差的影响
特定算子在训练框架与后端框架中的行为会有细微的差别,这会导致量化训练精度与实际量化模型的精度产生较大的差异。以MNN[5]为例,在YOLOX模型中存在如下两类OP会导致该现象。
修正round操作的影响
是否对round进行修正的结果如表3所示。从训练角度而言,round经过修正后的性能会略好于未修正的。同时如果在训练时round的行为与后端不一致的话,可能会导致真实量化模型的精度发生较大的变化。
| mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | |
| 修正 | 40.8 | 59.9 | 44.1 |
| 未修正 | 40.5 | 59.9 | 32.9 |
表3 round修正对于量化训练的影响
Sigmoid快速实现引入的误差
为了提升指数计算的速度,后端框架通常会采取一些快速近似计算。这对于浮点模型而言,通常不会引入较大的误差。但是对于量化模型而言,这个误差可能因为量化操作而被放大。
如图3所示,对于YOLOX的主要pattern(Conv -> SiLU -> Conv),前一层Conv的输出经过SiLU函数后,快速近似计算引入的误差会被后一层卷积输入处的量化操作(除以scale)而缩放。scale越小,缩放的程度越大。以YOLOX-s为例,是否对指数计算进行近似的量化模型精度如表4所示。

图3 YOLOX量化pattern
| mAP @0.5:0.95 | mAP @0.5 | mAP @0.75 | |
| 近似 | 40.2 | 59.5 | 43.7 |
| 未近似 | 40.6 | 59.7 | 44.2 |
表4 指数计算的近似带来的模型性能误差
5. 总结
本文通过在YOLOX目标检测模型上的量化实践,验证了通过量化感知训练(QAT)能够在精度无损的情况下,获得显著的模型压缩和推理加速。我们对量化精度误差因素进行了具体分析,指出了解决精度问题的一系列实践手段,并通过实验验证了效果,这可以作为我们在实际应用模型量化时的经验参考。虽然量化相关方法已经被大量研究,但是在实际复杂任务中应用量化仍然面临不少挑战,真正将量化压缩落地,更需要通过模型和系统两方面的协同。此外,还有更多量化训练相关的技术方案(如混合精度量化、更低比特量化等)值得探索和完善。
关于我们
本文中关于量化训练实践工作由阿里云-PAI模型压缩团队和微软NNI团队合作完成,也感谢MNN团队的技术支持。更多模型压缩的算法实现可参考NNI(GitHub repo[4]),更多模型推理优化技术方案可见阿里云PAI-Blade。
参考文献&代码仓库
[1] https://github.com/Megvii-BaseDetection/YOLOX
[2] Esser S K, McKinstry J L, Bablani D, et al. Learned step size quantization[J]. arXiv preprint arXiv:1902.08153, 2019.
[3] Bhalgat Y, Lee J, Nagel M, et al. Lsq+: Improving low-bit quantization through learnable offsets and better initialization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 696-697.
[4] https://github.com/microsoft/nni
[5] Jiang X, Wang H, Chen Y, et al. Mnn: A universal and efficient inference engine[J]. arXiv preprint arXiv:2002.12418, 2020.
[6] Jacob B, Kligys S, Chen B, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2704-2713.
[7] Paszke A, Gross S, Massa F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. Advances in neural information processing systems, 2019, 32: 8026-8037.
[8] Ge Z, Liu S, Wang F, et al. Yolox: Exceeding yolo series in 2021[J]. arXiv preprint arXiv:2107.08430, 2021.
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于量化感知训练实践:实现精度无损的模型压缩和推理加速的主要内容,如果未能解决你的问题,请参考以下文章