模型推理谈谈推理引擎的推理组织流程
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理谈谈推理引擎的推理组织流程相关的知识,希望对你有一定的参考价值。
本文主要讨论一下推理引擎的推理组织流程,包括 英伟达 tensorrt、华为 CANN 以及 TVM。
对于用户和大多开发者来说,其实不用太关心推理引擎内部是怎么实现推理的,比如你在使用 tensorrt 的时候你只要知道使用流程,怎么去生成 Eng,怎么调用 Eng 去 doInference 就好了。但是你不好奇吗,它到底是怎么 create Eng,怎么 load Eng 去做 inference 的,Eng 到底是个什么东西,它也不能像 .pth、.cfg、.pb 一样用 netron 来直观可视化。这里我们就对 tensorrt、CANN、TVM 的推理组织流程展开讨论一下。
1、TensorRT
tensorrt 是一个非常好用的高性能推理框架,它的使用方式主要有以下两种:
(1)将 tensorrt 嵌入到成熟的 AI 框架中,如 TF-TRT、Torch-TRT、ONNX-TRT、TVM-TRT 等,大多做法是将 tensorrt 支持的算子优先以 tensorrt 的方式执行,tensorrt 不支持的算子回退到原框架执行;
(2)直接使用 C++ API 或 Python API 去搭 tensorrt 的推理引擎,至于 tensorrt 不原生支持的算子,我可以采用更细粒度的算子进行拼接或替换(如用 resize 替换 upsample,用 clip 激活函数替换 relu6 等)甚至可以直接用 cuda 来自定义算子。
tensorrt 的推理流程如下:
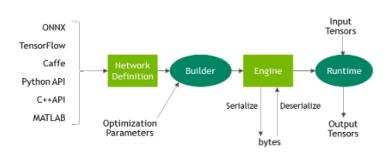
Network Definition 是用于解析模型之后在 tensorrt 中的网络定义,Builder 主要作用是把 Network Definition 按照对应的硬件生成相应的可执行程序,也就是 Engine。如果你进行在线推理的话,其实直接接着进 runtime 就好了。而实际中,我们往往需要把这个 Engine 保存成一个离线模型 .eng,以便于 runtime 过程的解耦,因为 runtime 往往在用户现场,而 runtime 之前的操作往往在家里。这个时候就需要用到 serialize 和 deserialize 了。
通过 serialize(序列化)来生成二进制文件 .eng,也即这里的 Optimized Plans,这个就是所谓的离线模型了。
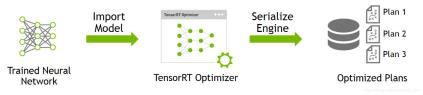
等去部署的时候,只要我们手里有离线模型就好了,然后借助 deserialize(反序列化)成硬件可执行程序 Engine 后继续执行推理就好了。

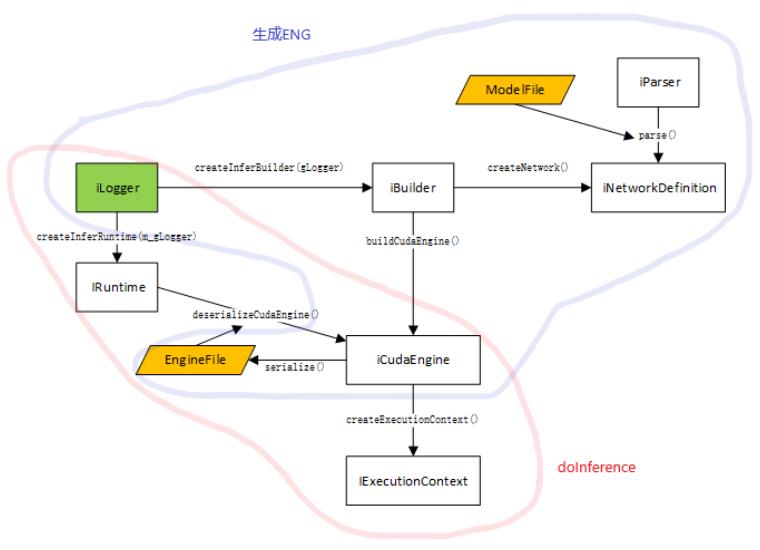
所以这么看来,整个 tensorrt createEng 和 doInference 的流程是这样的:
2、CANN
昇腾的 CANN 可能大家接触就没 tessorrt 那么多了,先简单介绍一下。
昇腾 CANN(Compute Architecture for Neural Networks)是华为针对 AI 全场景推出的异构计算框架,它对上支持业界主流的前端AI 框架,向下对用户屏蔽系列化芯片的硬件差异,以丰富的软件栈功能使能(我发现华为很喜欢用 “使能” 这两个词,我也用一下哈哈)用户全场景的人工智能应用。CANN 的架构如下:

下面来谈谈 CANN create .om(昇腾的离线模型)的组织流程。
其实 CANN 公开的信息要比 tensorrt 丰富许多,CANN TBE 软件栈的逻辑架构如下:
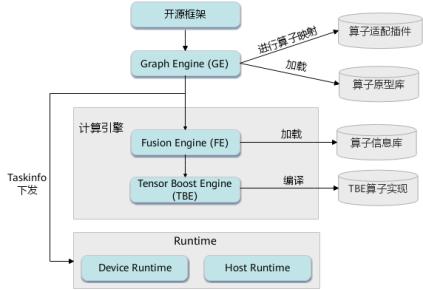
其中 Graph Engine(GE)+ Fusion Engine(FE)+ Tensor Boost Engine(TBE)就相当于 tensorrt 里的 builder,下面来看看 GE + FE + TBE 的组织方式:
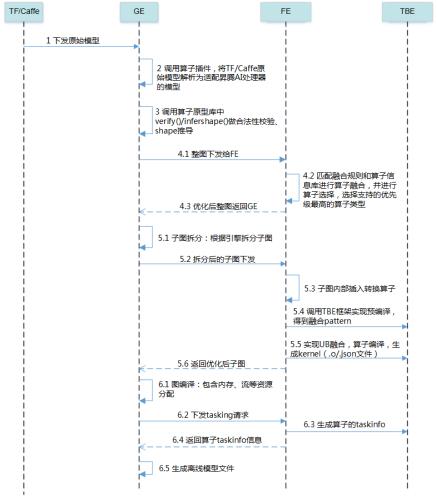
GE 是图引擎,FE 是融合引擎,TBE 是张量加速引擎。GE 主要作用是解析前端框架、链接后端、调度排布的融合引擎;FE 主要作用是实现算子融合、UB 融合;TBE 主要作用是提供了算子在华为加速卡中的实现编译、任务执行。结合上图,整个流程分成这么几个阶段:2~4 为算子适配替换、5 为子图拆分优化、6 为调度与流程排布。不难看出,经过 6.1 阶段后,实际推理过程中已经不存在所谓的网络层的概念,此时是由一个个 taskinfo 组成了离线模型 .om 文件,最终的 Runtime 时是通过调用 .om 内的信息进行任务下发。
3、TVM
大家都知道,昇腾 CANN 是基于 TVM 的,因此 CANN 的模型编译过程和 TVM 比较相似。TVM 的模型编译流程如下,其离线模型组织的位置在 relay.build -> graph optimize 之后。
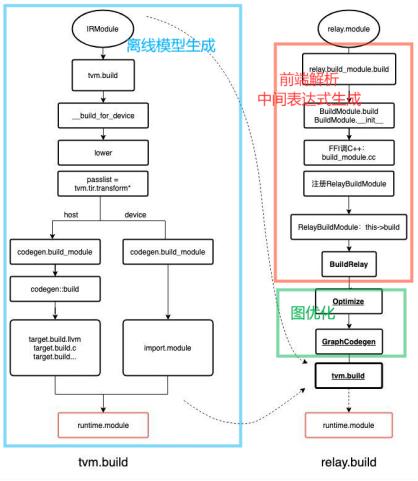
整个 TVM 的编译流逻辑如下[图片参考自]:
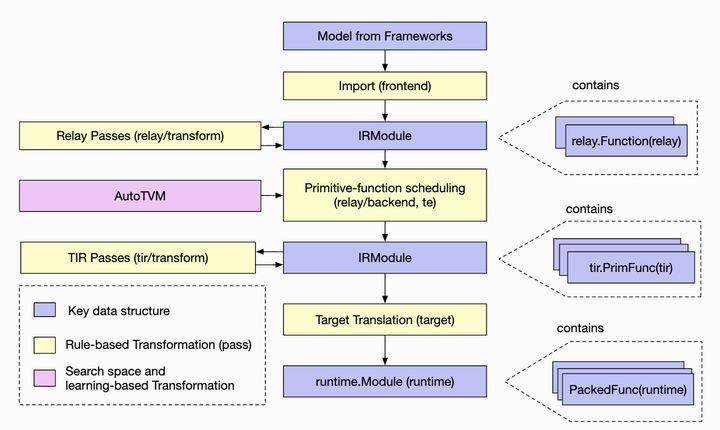
TVM 通过 relay.frontend.from_AIFrameworks 来接 AI 框架的模型转换成 relay IR,在 relay IR 上做图优化,完了后面接 compile engine 模块,去做 compute + schedule,然后进行子图编译,这时就到了 TIR 层,会走 TIR PASS,最后是 CodeGen,CodeGen 主要实现了内存分配及指定硬件设备上代码生成,完了就可以序列化成 TVM 的离线模型了(.json 和 .params)。
以上我们讨论了 tensorrt、CANN、TVM 的推理组织流程,如有说的不妥,欢迎交流~
收工~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理谈谈推理引擎的推理组织流程的主要内容,如果未能解决你的问题,请参考以下文章