模型推理谈谈为什么量化能加速推理
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理谈谈为什么量化能加速推理相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文主要讨论一下为什么量化能加速模型推理。
前面已经写过几篇关于模型量化相关的文章:《【模型推理】谈谈几种量化策略:MinMax、KLD、ADMM、EQ》、《【模型推理】谈谈模型量化组织方式》、《【模型推理】谈谈非线性激活函数的量化方式》,要了解相关知识可以查阅,这里主要讨论一下为什么量化能加速模型推理。
量化经常会涉及到 Quantize 和 Dequantize 的过程,其实对于不量化的 flow,量化是会增加操作子的,所以对于量化能加速的原因,可能并没有想象的那么简单。这里以 Conv 层来进行说明量化与不量化的速度区别。
假设输入通道为 C1,输出为 C2HW,卷积核的大小为 K,下述为各个不同类型运算指令的时钟周期:
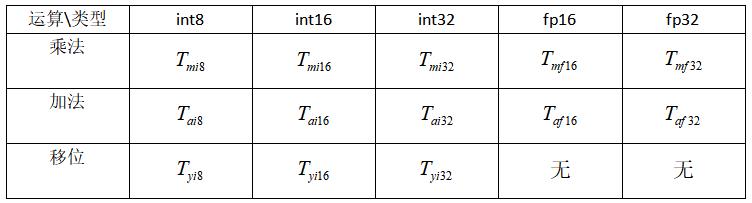
假设未量化的 Conv 算子使用 fp16 精度进行推理,其耗时如下:
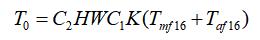
先抛开 Quantize 层和 Dequantize 层不看,单独计算量化为 int8 卷积后的耗时,需要注意的是,为了保证运算不溢出,不能够总是使用 int8 来进行卷积运算,中间计算结果有时需要使用 int16 甚至是 int32 数据类型来保存。下述 n1 表示做多少次 int8 乘加才不会溢出 int16 类型,n2 表示做多少次 int16 乘加才不会溢出 int32 类型:
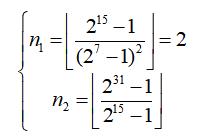
可以看到当进行 2 次 int8 乘加,就需要把原中间结果保存在 int16 寄存器中的数据累加到 int32 寄存器上;进行 n2 次 int16 加,就需要把本来中间结果保存在 int32 寄存器中的数据累加到 int64 寄存器上。因此,可以得到以下量化卷积后的时间:
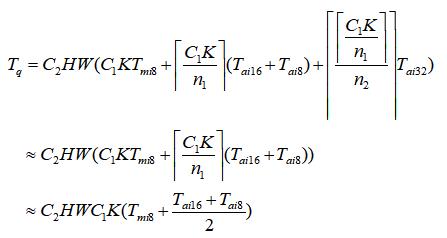
上述卷积还未添加 Requantize 操作,其运算操作耗时如下:
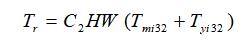
最终量化后的卷积操作耗时如下:
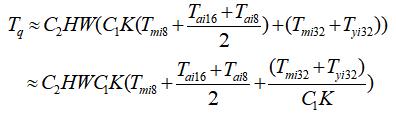
整型运算的算力往往要比浮点运算的算力高一倍,指令周期方面整形运算的周期是浮点运算的四分之一。单纯从上述的量化前后的卷积周期耗时来看,确实是会有速度上的提升。
然后我们来考虑加入 Quantize 层和 Dequantize 层,需要引入如下的指令时钟周期:
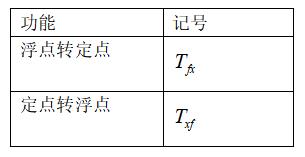
我们可以很容易得到加入 Quantize 层和 Dequantize 后的总体耗时,如下:
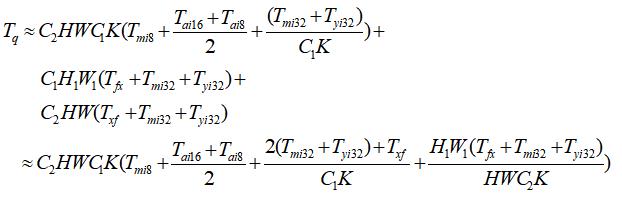
从上述公式,可知加入量化和反量化后,需要涉及到其他众多指令的时钟周期,这样是无法直接判断是否会比未量化的卷积更加快,这个问题需要结合不同的推理部署环境来看。
其实对于部署量化模型,大多数情况之所以可以加速,不止是因为浮点变整型运算指令周期缩短的原因,在很多专门为神经网络部署设计的芯片上,往往会存在专门为整型运算设计的加速单元。此外,有些硬件是不存在浮点运算单元的,这个时候可以使用量化模型进行部署。
以上从指令周期缩短的角度分析了一下量化提速的原因,量化提速是一个系统工程,需考虑的因素较多。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理谈谈为什么量化能加速推理的主要内容,如果未能解决你的问题,请参考以下文章