模型推理量化实现分享一:详解 min-max 对称量化算法实现
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理量化实现分享一:详解 min-max 对称量化算法实现相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
O_o >_< o_O O_o ~_~ o_O
大家好,我是极智视界,本文剖析一下 min-max 对称量化算法实现,以 Tengine 的实现为例。
Tengine 是 OpenAILab 开源的优秀端侧深度学习推理框架,其核心主要由 C 语言实现,包裹的功能代码嵌套了 C++。量化是推理加速必不可少的优化环节,成熟的推理框架一般会把量化模块剥离出来形成独立的一套工具,如 Tengine、NCNN、昇腾、寒武纪都这么做,这主要是因为量化过程和硬件非强相关,解耦开来能干更多的事。
min-max 和 kl 量化算法是硬件厂商适配推理引擎的基础和标配, 其中 kl 量化深受用户喜爱,如英伟达的 TensorRT 也正是采用了 kl 量化策略;而这里要介绍的 min-max 的特点是逻辑简单、效果良好,作为量化实现分享系列的开篇比较合适,这里带大家一起研究一下 Tengine 中 minx-max 量化策略的具体实现。
1、量化使用
量化主要分为激活值(动态)量化、权值&偏置(静态)量化,而权值&偏置的量化是对精度影响比较大的,激活值的量化对整体影响较小,但也需要量化,才有可能协同达到整体满意的效果。对于一般量化来说,权值&偏置的量化会采用逐通道 perChannel 的方式,而激活值的量化一般是逐层 perLayer 的方式。解释一下为啥会这样,对于量化来说,卷积肯定是大头,对于卷积来说,若激活值量化采用逐通道方式,这和卷积核参数共享是相悖的,所以一般激活值就用逐层量化,以契合卷积参数共享。
这里主要看一下 Tengine 量化需要的传参:
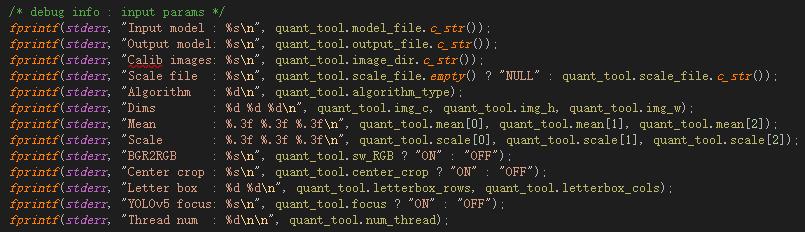
- Input model:传入的 fp32 tmfile 模型文件;
- Output model:生成的 int8 tmfile 模型文件;
- Calib images:传入的激活值量化校准图片;
- Scale file:生成的校准表文件;
- Agorithm:量化算法,可选 MIN-MAX、KL、ACIQ、DFQ、EQ;
- Dims:输入校准图的 shape,这里传三维 c h w,n 在代码中写死 n = 1;
- Mean:图像预处理均值;
- Scale:图像预处理缩放尺度;
- BGR2RGB:通道转换;
- Center crop:图像预处理,裁剪;
- Letter box:图像预处理,保持横纵比的前提下对图像做 resize;
- YOLOv5 focus:类似 yolov5 的预处理注意力机制;
- Thread num:量化多线程设置;
2、min-max 量化
min-max 是最简单的量化算法,主要逻辑如下:
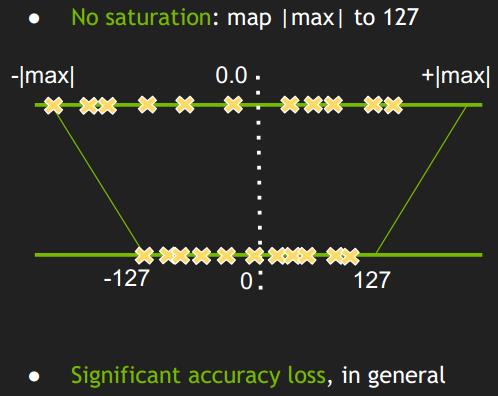
在 Tengine 中实现 min-max 方法的主要代码如下:
case ALGORITHM_MIN_MAX:
if (quant_tool.scale_file.empty())
quant_tool.scale_file = "table_minmax.scale";
quant_tool.activation_quant_tool();
save_graph_i8_perchannel(quant_tool.model_file.c_str(), quant_tool.scale_file.c_str(), quant_tool.output_file, quant_tool.inplace, false);
/* Evaluate quantitative losses */
if (quant_tool.evaluate)
fprintf(stderr, "[Quant Tools Info]: Step Evaluate, evaluate quantitative losses\\n");
quant_tool.assess_quant_loss(0);
break;
其中最主要的量化搜索策略接口是 quant_tool.activation_quant_tool() 和 save_graph_i8_perchannel,对于 min-max 来说这两个接口分别做了两件事:
(1) 激活值量化,生成 table_minmax.scale;
(2) 权值&偏置量化,生成 scale_weight.txt 和 scale_bias.txt;
2.1 激活值量化
看 Tengine 源码一定要抓住 struct graph* ir_graph,graph 这个结构体是精髓。
激活值量化是个动态的过程,需要动态的获取每层的数据分布,这也就是为啥需要你喂一定数量校准图片的原因。
先说一下预处理模块,这个其他量化算法是通用的:
// 将 input_tensor 和 input_data 地址绑定,而 input_tensor=>ir_graph->tensor_list。注意:这一步一定要看到,不然后续代码很难看懂
tensor_t input_tensor = get_graph_input_tensor(ir_graph, 0, 0);
if (set_tensor_shape(input_tensor, dims, 4) < 0)
fprintf(stderr, "Set input tensor shape failed\\n");
return -1;
if (set_tensor_buffer(input_tensor, input_data.data(), img_size * sizeof(float)) < 0)
fprintf(stderr, "Set input tensor buffer failed\\n");
return -1;
// prerun graph,做一些初始化配置
if (prerun_graph_multithread(ir_graph, this->opt) < 0)
fprintf(stderr, "Prerun multithread graph failed.\\n");
return -1;
// 图像预处理,传出 input_data,这个和前面的 input_tensor & ir_graph->tensor_list[0] 输入参 绑定,修改了 input_data 即修改了 ir_graph.tensor_list,这样就能看懂
get_input_data_cv(imgs_list[nums].c_str(), input_data.data(), img_c, img_h, img_w, mean, scale, sw_RGB, center_crop, letterbox_rows, letterbox_cols, focus);
然后 run 一下,把中间激活值记录到 ir_graph->tensor_list[i] 里:
if (run_graph(ir_graph, 1) < 0)
fprintf(stderr, "Run graph failed\\n");
return -1;
激活激活值的 min、max 值:
/* get the min/max value of activation tensor */
for (int i = 0; i < ir_graph->tensor_num; i++)
struct tensor* act_tensor = ir_graph->tensor_list[i];
if (act_tensor->tensor_type == TENSOR_TYPE_VAR || act_tensor->tensor_type == TENSOR_TYPE_INPUT)
float* start_addr = (float*)act_tensor->data;
float* end_addr = (float*)act_tensor->data + act_tensor->elem_num;
max_activation[i] = std::max(max_activation[i], *std::max_element(start_addr, end_addr));
min_activation[i] = std::min(min_activation[i], *std::min_element(start_addr, end_addr));
计算激活值量化尺度,对于 softmax 层 scale 默认为 1 / 127.f:
/* save the calibration file with min-max algorithm */
FILE* fp_minmax = fopen("table_minmax.scale", "wb");
for (int i = 0; i < ir_graph->tensor_num; i++)
struct tensor* t = ir_graph->tensor_list[i];
if (t->tensor_type == TENSOR_TYPE_VAR || t->tensor_type == TENSOR_TYPE_INPUT)
float act_scale = 1.f;
int act_zero_point = 0;
act_scale = std::max(std::abs(max_activation[i]), std::abs(min_activation[i])) / 127.f;
/* the scale of softmax is always scale = 1 / 127.f */
for (int j = 0; j < ir_graph->node_num; j++)
struct node* noden = ir_graph->node_list[j];
struct tensor* tensor_tmp = get_ir_graph_tensor(ir_graph, noden->output_tensors[0]);
if (!(tensor_tmp->tensor_type == TENSOR_TYPE_INPUT || tensor_tmp->tensor_type == TENSOR_TYPE_VAR))
continue;
std::string tmp_op_name = get_op_name_from_type(noden->op.type);
std::string cur_name = t->name;
std::string tmp_name = tensor_tmp->name;
if ((cur_name == tmp_name) && tmp_op_name == "Softmax")
act_scale = 1 / 127.f;
break;
fprintf(fp_minmax, "%s %f %d\\n", ir_graph->tensor_list[i]->name, act_scale, act_zero_point);
2.2 权值 & 偏置量化
权值 & 偏置量化和激活值量化不太一样,激活值量化需要校准图片推理以获得输入数据的动态分布,而权值 & 偏置是静态的,单纯的量化过程不需执行前向推理。
2.2.1 创建 graph
加载 tmfile,构建 graph:
struct graph* ir_graph = (struct graph*)create_graph(nullptr, "tengine", model_file);
if (nullptr == ir_graph)
fprintf(stderr, "Create graph failed.\\n");
return -1;
2.2.2 优化激活值量化 scale
这里主要做一个 quant.inplace 的优化,这是针对非卷积算子的量化处理策略。
if (inplace == 0)
for (int i = 0; i < ir_graph->tensor_num; i++)
struct tensor* ir_tensor = ir_graph->tensor_list[i];
if (ir_tensor->tensor_type == TENSOR_TYPE_VAR || ir_tensor->tensor_type == TENSOR_TYPE_INPUT)
ir_tensor->scale = layer_scale[ir_tensor->name];
ir_tensor->zero_point = layer_zeropoint[ir_tensor->name];
else
std::tr1::unordered_map<std::string, bool> layer_pass;
for (int i = ir_graph->tensor_num - 1; i >= 0; i--)
struct tensor* ir_tensor = ir_graph->tensor_list[i];
if (ir_tensor->tensor_type == TENSOR_TYPE_VAR || ir_tensor->tensor_type == TENSOR_TYPE_INPUT)
if (layer_pass[ir_tensor->name] == false)
uint32_t ir_node_idx = ir_tensor->producer;
struct node* t_node = ir_graph->node_list[ir_node_idx];
std::string op_name = get_op_name_from_type(t_node->op.type);
bool poolTrue = false;
bool reluTrue = false;
if (op_name == "Pooling")
struct pool_param* pool_param = (struct pool_param*)t_node->op.param_mem;
if (pool_param->pool_method == 0)
poolTrue = true;
else if (op_name == "ReLU")
struct relu_param* relu_param = (struct relu_param*)t_node->op.param_mem;
if (relu_param->negative_slope == 0.f)
reluTrue = true;
if (op_name == "Flatten" || op_name == "Reshape" || op_name == "Squeeze" || op_name == "Clip" || op_name == "Slice" || poolTrue || reluTrue)
struct tensor* t_in_tensor = ir_graph->tensor_list[t_node->input_tensors[0]];
if (layer_scale[ir_tensor->name] != 0)
ir_tensor->scale = layer_scale[ir_tensor->name];
ir_tensor->zero_point = layer_zeropoint[ir_tensor->name];
if (t_in_tensor->tensor_type == TENSOR_TYPE_VAR || t_in_tensor->tensor_type == TENSOR_TYPE_INPUT)
recursion_pass_through(ir_graph, ir_tensor->name, t_in_tensor, layer_used, layer_scale, layer_zeropoint, layer_pass);
else
ir_tensor->scale = layer_scale[ir_tensor->name];
ir_tensor->zero_point = layer_zeropoint[ir_tensor->name];
layer_pass[ir_tensor->name] = true;
2.2.3 权值 & 偏置量化
量化的整个过程和激活值量化类似,即先搜索 min、max 值,后做截断缩放处理。这里不仅需要计算 scale,而且还要做截断缩放处理的原因是需要生成 int8 tmfile 量化模型文件。这里还有一点需要注意的是权值量化精度为 int8,偏置量化精度为 int32,因为权值做完矩阵乘后值很有可能就会溢出 int8,所以需要权值矩阵乘后的值用 int32 存储,然后与 int32 的偏置做加法。
除了以上这些,和激活值量化还有个区别是,激活值量化是 perLayer 的,而权值 & 偏置量化是 perChannel 的。
权值 int8 量化:
/* quantize the weight data from fp32 to int8 */
if (op_name == "Convolution" || op_name == "FullyConnected" || op_name == "Deconvolution")
struct tensor* weight_tensor = ir_graph->tensor_list[noden->input_tensors[1]];
int channel_num = weight_tensor->dims[0];
int cstep = int(weight_tensor->elem_num / channel_num);
float* weight_data = (float*)weight_tensor->data;
int8_t* i8_weight_data = (int8_t*)sys_malloc(weight_tensor->elem_num * sizeof(int8_t));
float* weight_scale_list = (float*)sys_malloc(channel_num * sizeof(float));
int* weight_zp_list = (int*)sys_malloc(channel_num * sizeof(int));
fprintf(fp_weight, "%s ", weight_tensor->name);
/* calculate the quant scale value of weight perchannel, scale = abs(min, max) / 127 */
if (internal)
// TODO
for (int ch = 0; ch < channel_num; ch++)
weight_scale_list[ch] = weight_tensor->scale_list[ch];
weight_zp_list[ch] = 0;
else
for (int ch = 0; ch < channel_num; ch++)
float* weight_data_ch_start = weight_data + ch * cstep;
float* weight_data_ch_end = weight_data + (ch + 1) * cstep;
float weight_max = *std::max_element(weight_data_ch_start, weight_data_ch_end);
float weight_min = *std::min_element(weight_data_ch_start, weight_data_ch_end);
weight_scale_list[ch] = std::max(std::abs(weight_max), std::abs(weight_min)) / 127.f;
weight_zp_list[ch] = 0;
fprintf(fp_weight, "%8.8f ", weight_scale_list[ch]);
fprintf(fp_weight, "\\n");
/* quantize the value of weight from Float32 to Int8, value_i8 = (value_fp32 / scale).round().clip(-127, 127) */
for (int ch = 0; ch < channel_num; ch++)
for (int j = 0; j < cstep; j++)
if (weight_data[ch * cstep + j] == 0 || weight_scale_list[ch] == 0)
i8_weight_data[ch * cstep + j] = 0;
else
float int8_data = round(weight_data[ch * cstep + j] / weight_scale_list[ch]);
int8_data = int8_data > 127.f ? 127.f : int8_data;
int8_data = int8_data < -127.f ? -127.f : int8_data;
i8_weight_data[ch * cstep + j] = int8_t(int8_data);
weight_tensor->scale_list = weight_scale_list;
weight_tensor->zp_list = weight_zp_list;
weight_tensor->data_type = TENGINE_DT_INT8;
weight_tensor->elem_size = sizeof(int8_t); // int8, signed char
weight_tensor->data = i8_weight_data;
weight_tensor->quant_param_num = channel_num;
偏置 int32 量化:
/* quantize the weight data from fp32 to int32 */
if (noden->input_num > 2)
struct tensor* input_tensor = ir_graph->tensor_list[noden->input_tensors[0]];
struct tensor* bias_tensor = ir_graph->tensor_list[noden->input_tensors[2]];
float* bias_scale_list = (float*)sys_malloc(bias_tensor->dims[0] * sizeof(float));
int* bias_zp_list = (int*)sys_malloc(bias_tensor->dims[0] * sizeof(int32_t));
float* bias_data = (float*)bias_tensor->data;
int* int32_bias_data = (int*)sys_malloc(bias_tensor->elem_num * sizeof(int32_t));
int bstep = int(bias_tensor->elem_num / channel_num);
fprintf(fp_bias, "%s ", bias_tensor->name);
/* calculate the quant scale value of bias perchannel, scale = scale_weight * scale_in */
for (int ch = 0; ch < channel_num; ch++)
bias_scale_list[ch] = weight_scale_list[ch] * input_tensor->scale;
bias_zp_list[ch] = 0;
fprintf(fp_bias, "%8.8f ", bias_scale_list[ch]);
fprintf(fp_bias, "\\n");
/* quantize the value of bias from Float32 to Int32, value_i32 = (value_fp32 / scale).round() */
for (int ch = 0; ch < channel_num; ch++)
for (int bi = 0; bi < bstep; bi++)
if (bias_data[ch * bstep + bi] == 0 || bias_scale_list[ch] == 0)
int32_bias_data[ch * bstep + bi] = 0;
else
int32_bias_data[ch * bstep + bi] = int(round(bias_data[ch * bstep + bi] / bias_scale_list[ch]));
bias_tensor->scale_list = bias_scale_list;
bias_tensor->zp_list = bias_zp_list;
bias_tensor->data_type = TENGINE_DT_INT32;
bias_tensor->elem_size = sizeof(int32_t); // int32, signed int
bias_tensor->data = int32_bias_data;
bias_tensor->quant_param_num = channel_num;
到这里权值 & 偏置的量化就介绍的差不多咯。
以上详细介绍了 min-max 量化算法的实现,主要以 Tengine 为例进行代码说明,希望我的分享能对你的学习有一点帮助。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理量化实现分享一:详解 min-max 对称量化算法实现的主要内容,如果未能解决你的问题,请参考以下文章