爬取电影天堂最新电影的名称和下载链接
Posted lattesea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取电影天堂最新电影的名称和下载链接相关的知识,希望对你有一定的参考价值。
此次的目标是爬取电影天堂最新200页的最新电影的电影名称和下载链接,电影的下载链接在二级页面,所以需要先匹配一级页面的所有链接,然后逐个请求二级页面,代码如下:
"""
爬取电影天堂2019年的电影名称和链接
"""
import requests
import csv
from fake_useragent import UserAgent
from lxml import etree
import re
import time
import random
class DianyingtiantangSpider(object):
def __init__(self):
self.url = ‘https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html‘
# self.url2 = ‘https://www.dytt8.net/html/gndy/dyzz/20190918/59138.html‘
def get_headers(self):
"""
构造请求头
:return:
"""
ua = UserAgent()
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "UM_distinctid=16bdec86bc2679-07c211dd7aebc-15231708-1fa400-16bdec86bc3464; CNZZDATA1260535040=961678368-1562805532-https%253A%252F%252Fwww.baidu.com%252F%7C1562805532",
"Host": "www.dytt8.net",
"If-Modified-Since": "Thu, 19 Sep 2019 00:34:23 GMT",
"If-None-Match": "80d1b3fb816ed51:326",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": ua.random
}
return headers
def re_func(self, re_bds, html):
"""
正则表达式解析出第一页的排名链接
:param re_bds:
:param html:
:return:
"""
pattern = re.compile(re_bds, re.S)
r_list = pattern.findall(html)
return r_list
def parse_index_page(self, url):
"""
请求解析第一页的链接
:param url:
:return:
"""
text = requests.get(url=url, headers=self.get_headers())
text.encoding = ‘GBK‘
# print(text.text)
re_bds = r‘<table width="100%".*?<td width="5%".*?<a href="(.*?)".*?ulink">.*?</table>‘
# link = re.findall(‘<table width="100%".*?<td width="5%".*?<a href="(.*?)".*?ulink">.*?</table>‘, text.text)
# html = etree.HTML(text.text)
# link = html.xpath("//ul/table[@class=‘tbspan‘][1]/tbody/tr[4]/td/text()")
link = self.re_func(re_bds, text.text)
print(link)
# print(text)
return link
def parse_two_page(self, url):
"""
请求解析第二页的电影名和下载链接
:param url:
:return:
"""
text = requests.get(url=url, headers=self.get_headers())
# print(text.text)
text.encoding = ‘GBK‘
html = etree.HTML(text.text)
movie = html.xpath(‘//*[@id="header"]/div/div[3]/div[3]/div[1]/div[2]/div[1]/h1/font/text()‘)
download = html.xpath(‘//tbody/tr/td/a/@href‘)
# movie=re.findall("",text.text)
print(movie)
print(download)
# print(html)
return (movie[0], download[0])
def save_csv(self, result):
"""
保存到csv文件
:param result:
:return:
"""
with open(‘movie.csv‘, ‘a‘, newline=‘‘)as f:
writer = csv.writer(f)
writer.writerows(result)
def run(self):
"""
主函数
:return:
"""
for i in range(1, 201):
url1 = self.url.format(i)
list_result = []
link = self.parse_index_page(url1)
for j in link:
url2 = ‘https://www.dytt8.net‘ + j
try:
result = self.parse_two_page(url2)
print(result)
list_result.append(result)
time.sleep(random.uniform(1, 3))
except Exception as err:
print(err)
self.save_csv(list_result)
print("第%s页保存成功" % i)
if __name__ == ‘__main__‘:
spider = DianyingtiantangSpider()
spider.run()
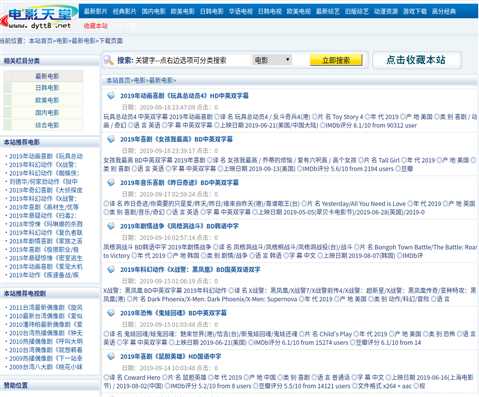
一级页面:
二级页面:
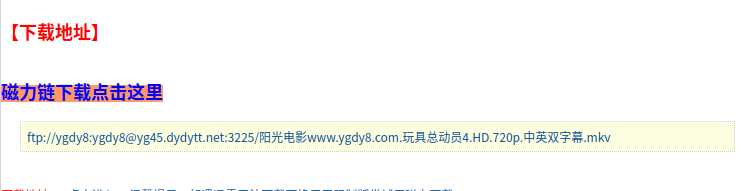
总结:
1.在爬取电影天堂的时候发现,请求一级页面的时候得到的网页源码中居然缺少了一些标签,所以刚开始总是匹配不到东西,xpath有时候并非万能,特别是遇到这种页面缺失的.这时候就不得不拿出杀手锏正则表达式了,只要页面出现的东西,正则就能拿到,当然正则有时候会匹配出一下重复值,这时候只要用到python中的集合函数set()处理一下就行.
2.还遇到了另一个问题,就是电影天堂的编码是gb2312,所以刚开始请求得到的网页中的中文是乱码,一番查询之后发现只要添加一下代码就能成功解决
text = requests.get(url=url, headers=self.get_headers())
text.encoding = ‘GBK‘
以上是关于爬取电影天堂最新电影的名称和下载链接的主要内容,如果未能解决你的问题,请参考以下文章