Python高级应用程序设计任务要求
Posted 庄伟淞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务要求相关的知识,希望对你有一定的参考价值。
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取电影天堂华语电视剧信息和下载链接
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取电影天堂华语电视剧信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案依靠request库访问,用BeautifulSoup分析网页结构获取数据,采集信息进行数据持久化,保存在本地文件中。
技术难点主要包括对页面结构分析、对数据的采集和数据持久化。
二、主题页面的结构特征分析(15分)
1.最新电影列表页面结构分析

2.电影链接解析


三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1. 模块引入
程序代码: #!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import os import re
2. 定义全局数组
# 定义全局数组 videos_name = [] videos_url = [] videos = []
3. 获取页面源码函数
# 获取电影列表的url和名称并保存到数组中 def getVodList(url): # 伪装浏览器 ua = {\'user-agent\':\'Mozilla/5.0\'} # 开始爬取页面 r = requests.get(url, headers=ua) r.raise_for_status() # 设置网页编码格式为GBK r.encoding = \'gbk\' #parse soup = BeautifulSoup(r.text, \'html.parser\') #table.tbspan soup.find_all(\'table\', class_=\'tbspan\') #parse Title and Url # 循环遍历a标签提取电影信息 for table in soup.find_all("a", class_=\'ulink\'): # 将电影名称存入 电影名称数组中 videos_name.append(table.get_text()) # 将电影链接存入 电影链接数组中 videos_url.append(table.get(\'href\'))
4. 页面解析
# 获取具体 def getVideoInfo(url): #获取目标页面 ua = {\'user-agent\':\'Mozilla/5.0\'} # 拼接电影具体链接,爬取具体某个电影页面 r = requests.get(\'https://www.dytt8.net\' + url, headers=ua) r.raise_for_status() r.encoding = \'gbk\' #parse soup = BeautifulSoup(r.text, \'html.parser\') #td-bgcolor for table in soup.find_all(\'td\', attrs={"bgcolor": "#fdfddf"}): # 获取电影下载链接 down_url = table.get_text() # 返回电影下载的链接 return down_url
5. 数据持久化
# 数据持久化存入new_move_list.txt def saveData(ulist): \'\'\' 保存数据 \'\'\' try: # 创建新文件夹 os.mkdir("C:\\dytt") except: # 如果文件夹存在则什么也不做 "" try: # 在新目录下创建文件用于存储爬取到的数据 with open("C:\\\\dytt\\\\new_move_list.txt","w") as f: for i in range(len(ulist)): f.write(ulist[i]) f.write(\'\\n\') except: "Error_saveData"
6. 主函数
# 主函数 if "__name__" = "__main__": #获取目标页面 url = "https://www.dytt8.net/html/tv/hytv/index.html" # 获取数据存入videos_name,videos_url数组中 getVodList(url) #循环获取电影内页 for i, j in zip(videos_url, videos_name): down_url = getVideoInfo(i) print(\'[name] \', j) print(\'[down] \', down_url) # 封装到一个新数组中 videos.append(j + "|" + down_url) # 存入本地磁盘 saveData(videos)
7. 爬取结果图
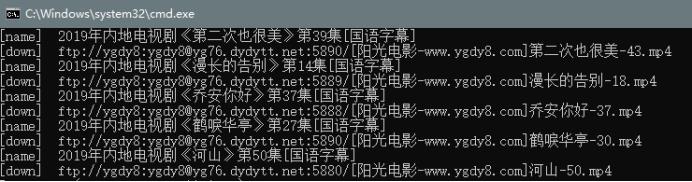
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对页面结构的分析,可以得到所需要的相关信息,存储相关信息后可以再进行其他分析。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次任务,通过对网页的分析,基本实现了python对电影天堂华语电视剧信息的采集,其中还有很多小细节需要研究。
以上是关于Python高级应用程序设计任务要求的主要内容,如果未能解决你的问题,请参考以下文章