python爬虫入门
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫入门相关的知识,希望对你有一定的参考价值。
python爬虫入门(7)
需求:
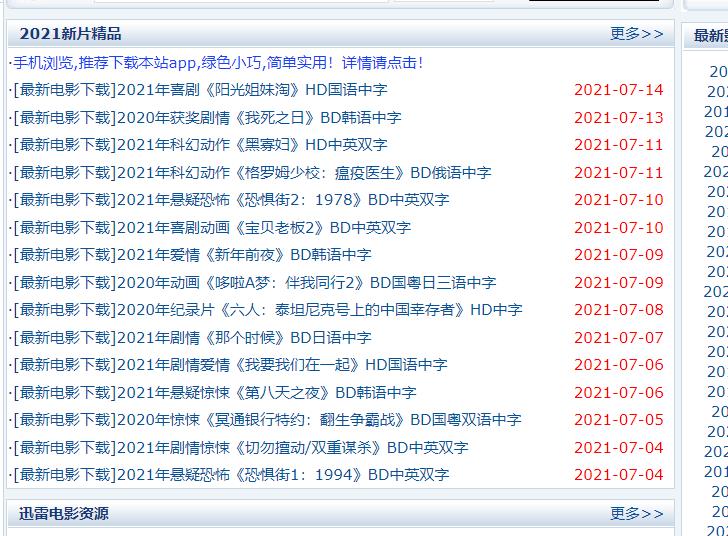
爬取电影天堂
电影天堂首页有很多分区,我选择爬取2021新片精品这一分区
文章目录
一.逐步实现
思路分析:
先定位至此:
再在这里面找到子页面的地址,然后请求子页面的链接地址,拿到下载地址(迅雷种子)
1.检验状态码和编码
import requests
domain = "https://dy.dytt8.net/index.htm"
resp = requests.get(domain)#视频教程里还添加了一个参数叫veify=False,之后遇到啥去掉安全验证的时候留意一下
print(resp.status_code)
print(resp.apparent_encoding)
#print(resp.text)也能看到charset=gb2312
resp.close()
# resp.encoding="gb2312"
#或
resp.encoding="gbk"
print(resp.text)
2.找到分区,提取分区源代码
找到2021新片精品分区的源代码,可以按ctrl+f迅速找到所在位置
分析目标,写出正则表达式

import re
obj1 = re.compile(r'2021新片精品.*?<ul>(?P<_2021新片精品分区>.*?)</ul>',re.S)
#如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
#而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配
result1=obj1.finditer(resp.text)
for it in result1:
partition = it.group("_2021新片精品分区")
print(partition)
3.从分区源代码中中提取子页面链接
观察分区的源代码,写出正则表达式
obj2 = re.compile(r'最新电影下载</a>]<a href="(?P<子页面链接>.*?)"')
- 提取:
for it in result1:
print(resp.status_code)
partition = it.group("_2021新片精品分区")
result2=obj2.finditer(partition)
for itt in result2:
print(itt.group("子页面链接"))
- 但此时还不是可以直接访问的域名,可以拼接一下:域名+子页面链接
#拼接子页面的url地址: 域名+子页面地址
for it in result1:
print(resp.status_code)
partition = it.group("_2021新片精品分区")
result2 = obj2.finditer(partition)
for itt in result2:
child_herf = "https://dy.dytt8.net/"+itt.group("子页面链接").strip("/")
print(child_herf)
- 为了方便,把子页面链接放进列表里:
child_href_list = []
for it in result1:
partition = it.group("_2021新片精品分区")
result2 = obj2.finditer(partition)
for itt in result2:
child_href = "https://dy.dytt8.net/"+itt.group("子页面链接").strip("/")
# 具体问题具体分析,视频里直接用的domain+itt.group("子页面链接")
child_href_list.append(child_href)
4.请求子页面链接地址,拿到需要下载的链接
查看一个子页面的源代码,进行分析,写出正则表达式
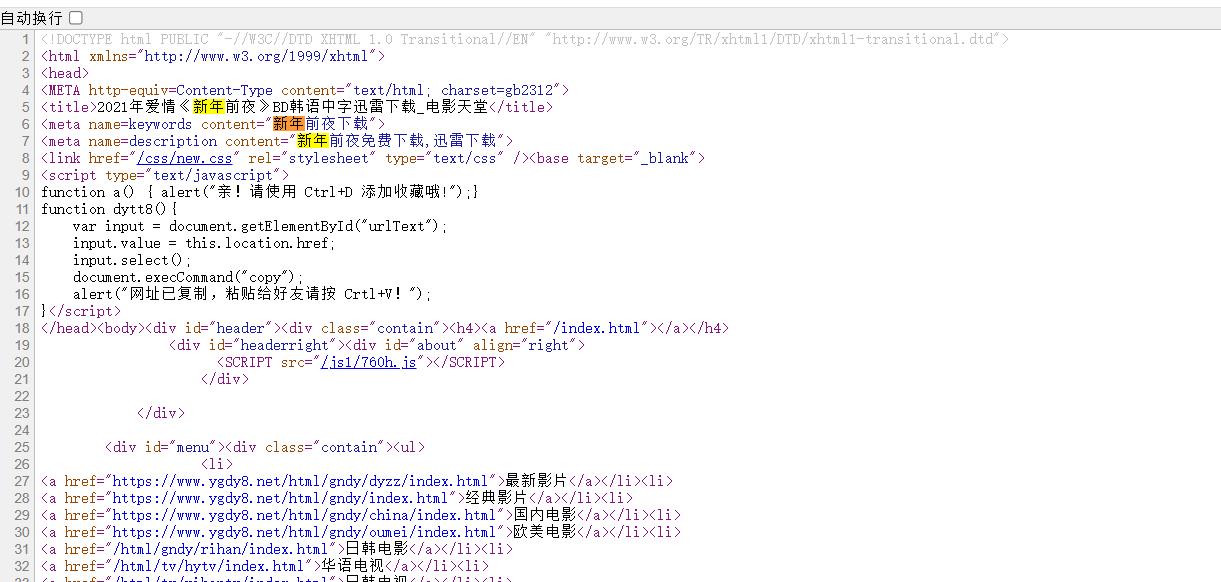
直接复制到正则表示里比较好,自己照着写的不一定是源码,很可能少了空格啥的导致正则表达式检索不到
obj3 = re.compile(r'◎片 名(?P<电影名字>.*?)<br />◎年 代.*?'
r'<a target="_blank" href="(?P<迅雷磁力链接>.*?)">'
r'<strong><font style="BACKGROUND-COLOR: #ff9966"><font color="#0000ff"><font size="4">磁力链', re.S)
# 别忘记加re.S不然找不到结果!
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gb2312'
result3 = obj3.search(child_resp.text)
print(result3.group("电影名字"))
print(result3.group("迅雷磁力链接"))
不要忘了re.S!!!
5.保存到文件
这是一段会报错的代码
import csv
f = open(f"movie.csv", mode="a")
csvwriter = csv.writer(f)
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gb2312'
result3 = obj3.search(child_resp.text)
# print(result3.group("电影名字"))
# print(result3.group("迅雷磁力链接"))
dic = result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
可运行代码:
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gbk'
result3 = obj3.search(child_resp.text)
dic = result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
resp.close()#关闭请求
解释在后文
二.完整代码
# 电影天堂
import requests
import re
import csv
domain = "https://dy.dytt8.net/index.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0 Win64 x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
f = open(f"movie.csv", mode="a")
csvwriter = csv.writer(f)
# 视频教程里还添加了一个参数叫veify=False,之后遇到啥去掉安全验证的时候留意一下
resp = requests.get(domain, headers=headers)
resp.encoding = "gbk"
obj1 = re.compile(r'2021新片精品.*?<ul>(?P<_2021新片精品分区>.*?)</ul>', re.S)
# 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
# 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配
obj2 = re.compile(r"最新电影下载</a>]<a href='(?P<子页面链接>.*?)'")
# 提取子页面链接
obj3 = re.compile(r'◎片 名(?P<电影名字>.*?)<br />◎年 代.*?'
r'<a target="_blank" href="(?P<迅雷磁力链接>.*?)">'
r'<strong><font style="BACKGROUND-COLOR: #ff9966"><font color="#0000ff"><font size="4">磁力链', re.S)
# 别忘记加re.S不然找不到结果!
result1 = obj1.finditer(resp.text)
# 为了方便放到一个列表里面:
child_href_list = []
for it in result1:
partition = it.group("_2021新片精品分区")
result2 = obj2.finditer(partition)
for itt in result2:
child_href = "https://dy.dytt8.net/"+itt.group("子页面链接").strip("/")
# 具体问题具体分析,视频里直接用的domain+itt.group("子页面链接")
child_href_list.append(child_href)
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gbk'
result3 = obj3.search(child_resp.text)
dic = result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
resp.close()#关闭请求
三.遇到的问题
1.(?P<分区名字>)
一开始我用的是<2021新片精品分区>,结果报错如下

解决方案:

看来是数字不能作为开头,于是我改成了下划线
2.提取子页面链接

提取一定要注意细节,一开始写的r'最新电影下载</a>]<a href="(?P<子页面链接>.*?)"'发现输出结果是空的
应该改为r'最新电影下载</a>]<a href='(?P<子页面链接>.*?)''因为后面的子页面链接是单引号括起来的,
但此时又报错了,之前爬取豆瓣那里也遇到过,然后改成了r"(省略)",就好了
3.‘gbk’ codec can’t encode character ‘\\ufffd’
- 在最后一步保存文件时,这段代码遇到了这个问题
import csv
f = open(f"movie.csv", mode="a")
csvwriter = csv.writer(f)
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
child_resp.encoding = 'gb2312'
result3 = obj3.search(child_resp.text)
# print(result3.group("电影名字"))
# print(result3.group("迅雷磁力链接"))
dic = result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
- 于是我参考一篇博客,将代码修改成了:
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
text = child_resp.text.replace('\\ufffd', '')#用空字符串代替
text.encode(encoding = 'gb2312')
result3 = obj3.search(text)
# print(result3.group("电影名字"))
# print(result3.group("迅雷磁力链接"))
dic=result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
- 紧接着又报错:
'gb2312' codec can't encode character '\\xc4' in position 255: illegal multibyte sequence - 然后我把代码改成:
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
text = child_resp.text.replace('\\ufffd', '')
text = child_resp.text.replace('\\xc4', '')
text = child_resp.text.replace('\\xcf', '')
text.encode(encoding='gb2312')
result3 = obj3.search(text)
# print(result3.group("电影名字"))
# print(result3.group("迅雷磁力链接"))
dic = result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
resp.close()
- 紧接着又来了报错:
UnicodeEncodeError: 'gb2312' codec can't encode character '\\xcf' in position 256: illegal multibyte sequence,
于是我就加上了text = child_resp.text.replace('\\xcf', '')
for href in child_href_list:
child_resp = requests.get(href, headers=headers)
text = child_resp.text.replace('\\ufffd', '')
text = child_resp.text.replace('\\xc4', '')
text = child_resp.text.replace('\\xcf', '')
text.encode(encoding='gb2312')
result3 = obj3.search(text)
# print(result3.group("电影名字"))
# print(result3.group("迅雷磁力链接"))
dic = result3.groupdict("")
#groupdict返回一个字典,包含所有经命名的匹配子群,键值是子群名
csvwriter.writerow(dic.values())
resp.close()
- 谁知道,接着报错:
UnicodeEncodeError: 'gb2312' codec can't encode character '\\xc4' in position 255: illegal multibyte sequence - 然后我搜到说把gb2312换成
gbk就好了…结果成功了,没有报错,csv文件也正常显示那些数据了
可是第一个报错就是说gbk有问题啊…这到底是为啥?
一开始以为gbk和gb2312是一样的,查了一下它们的区别,也许是因为这个吧😭 😢 😢

太爱这张可爱的图啦!!!
以上是关于python爬虫入门的主要内容,如果未能解决你的问题,请参考以下文章