爬虫学习 ----- 第二章 爬取静态网站 ---------- 03 . re 模块学习 ---- re屠戮电影天堂
Posted Zero_Adam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习 ----- 第二章 爬取静态网站 ---------- 03 . re 模块学习 ---- re屠戮电影天堂相关的知识,希望对你有一定的参考价值。
目录:
1. 【案例】re屠戮电影天堂
1.目的:
- 定位到2021新片精品
- 从2021新片精品中提取到子页面的链接地址
- 请求子页面的链接地址,拿到我们想要的下载地址…
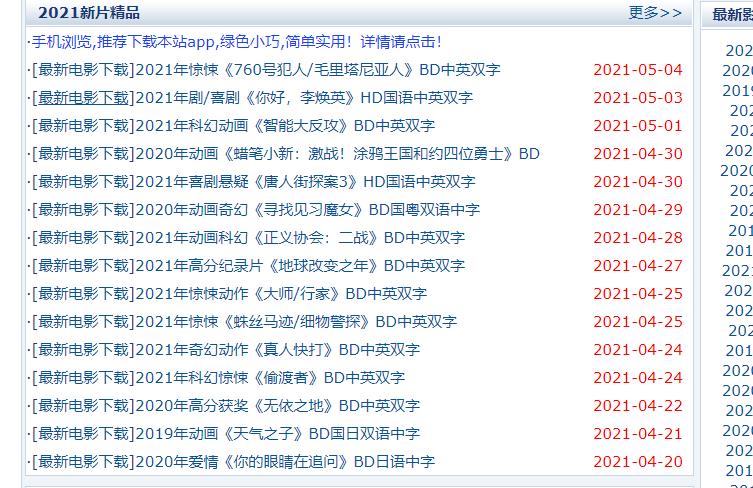
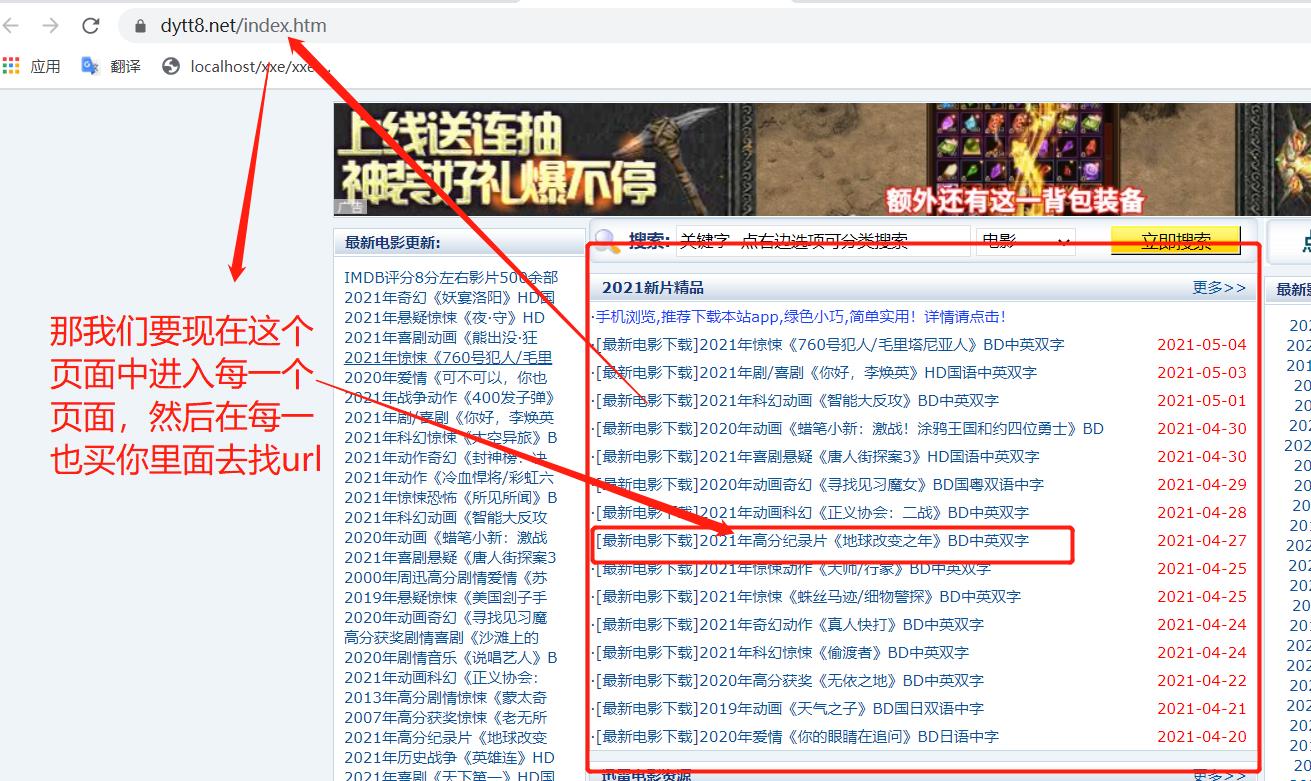
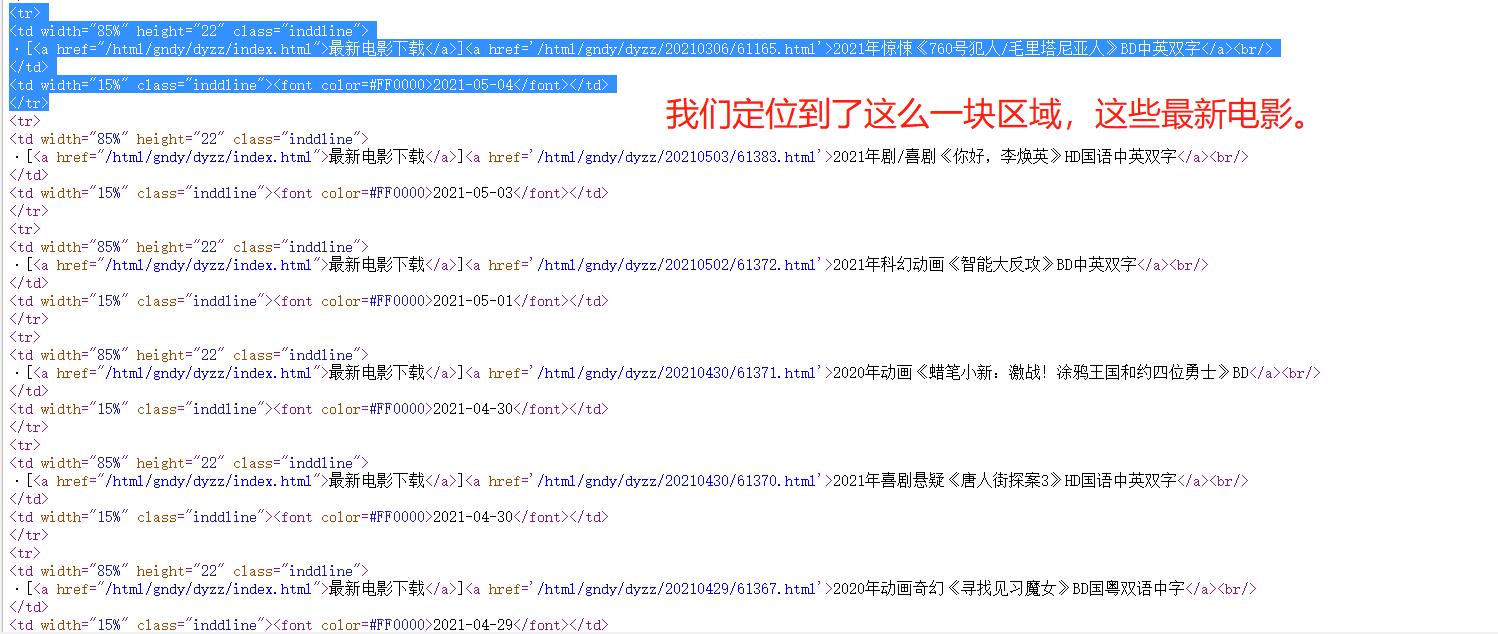
1. 定位到2021新片精品
我想得到这里的电影的下载地址。
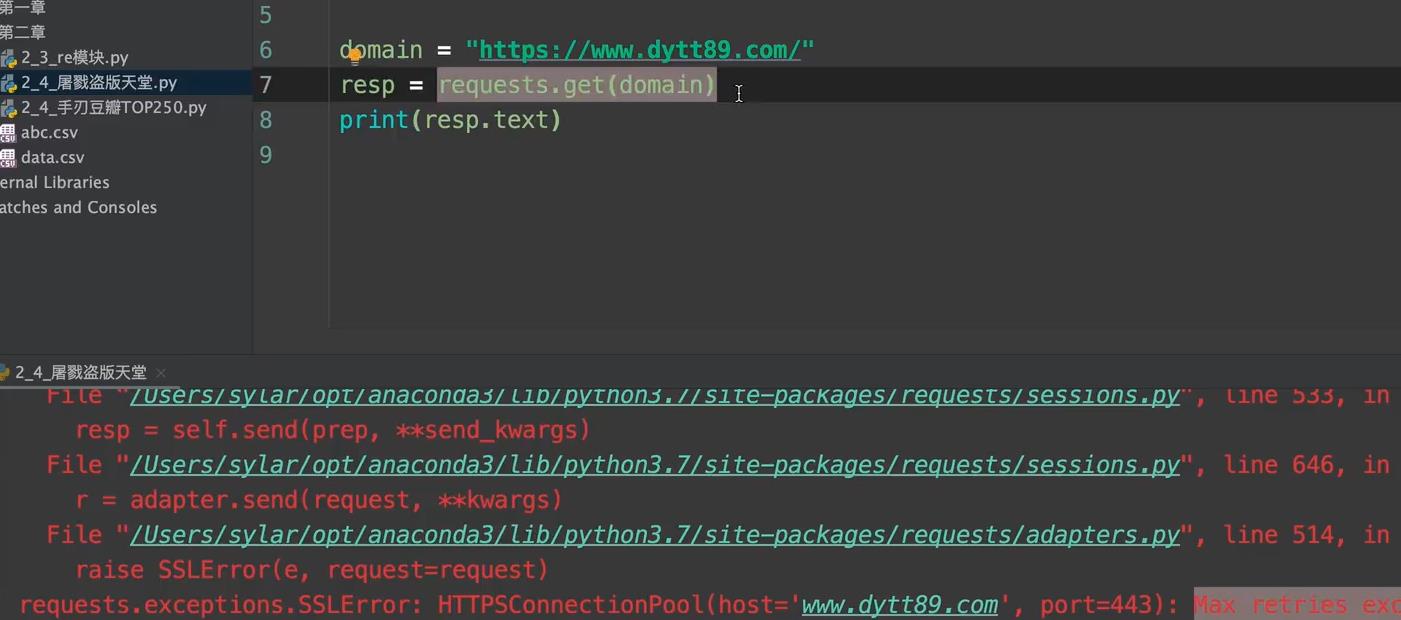
1. 出现错误???
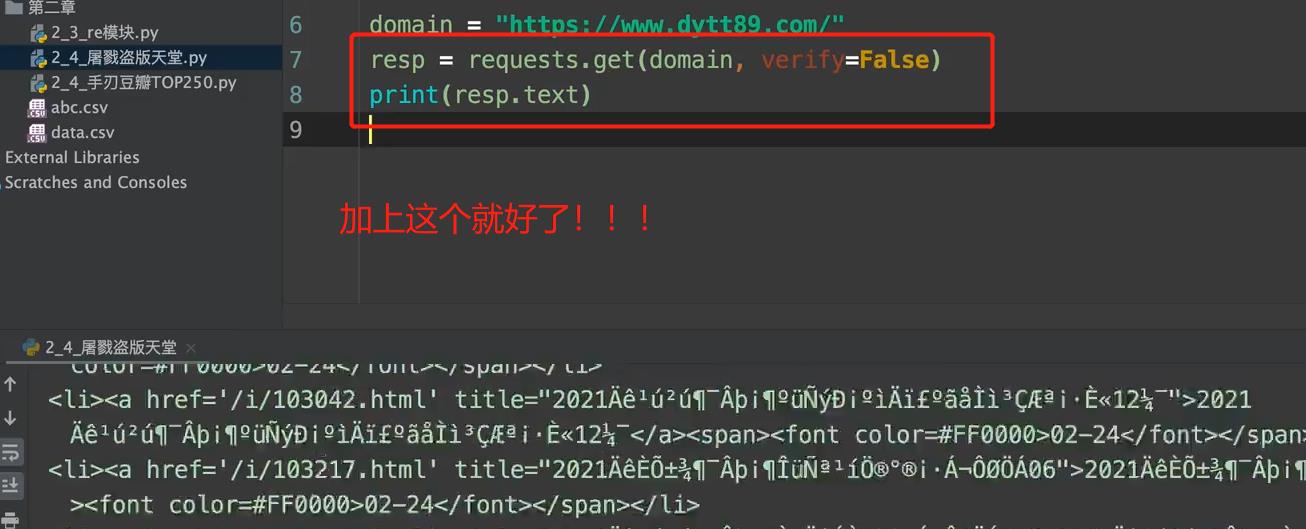
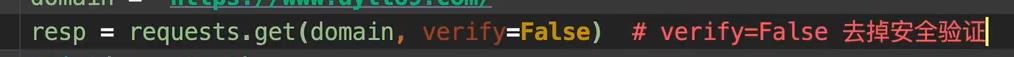
2. 网页乱码???
python抓包回来,默认进行utf8编码了,但是 如果网页的编码不是utf8的话,就会出现这样的乱码
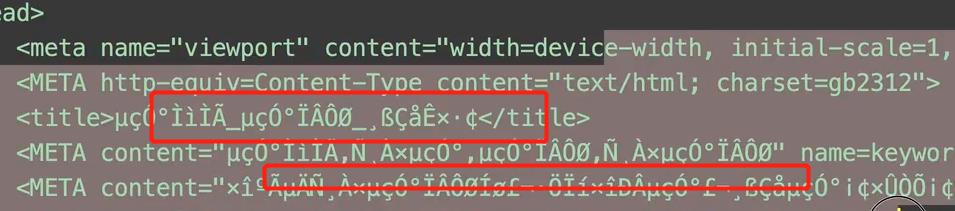
网站的编码通常会进行声明,

然后我们进行换一下编码就好了

我们的唯一标识就是 2021新片精品


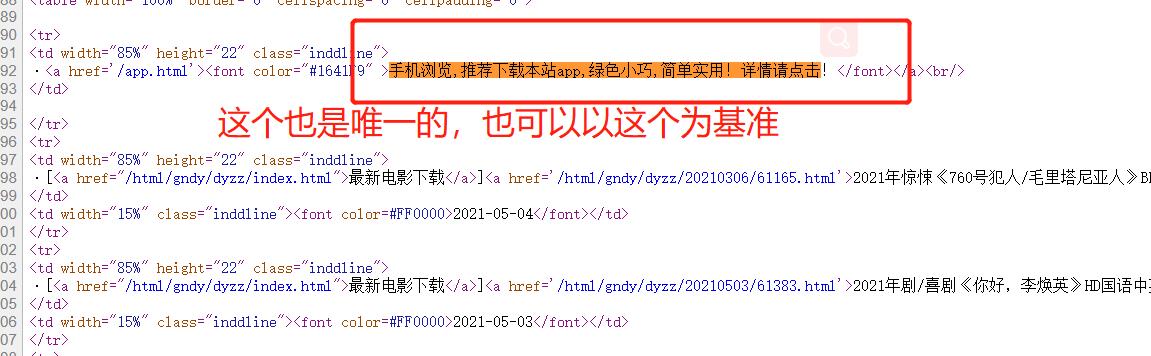
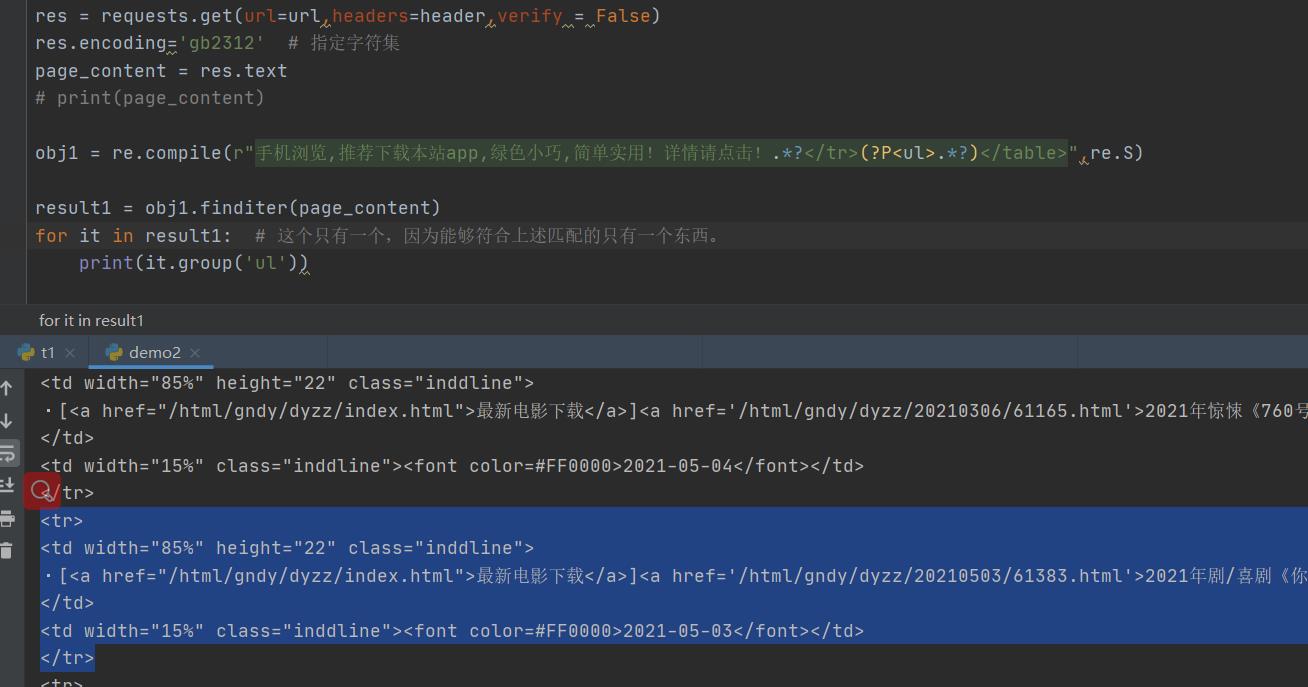
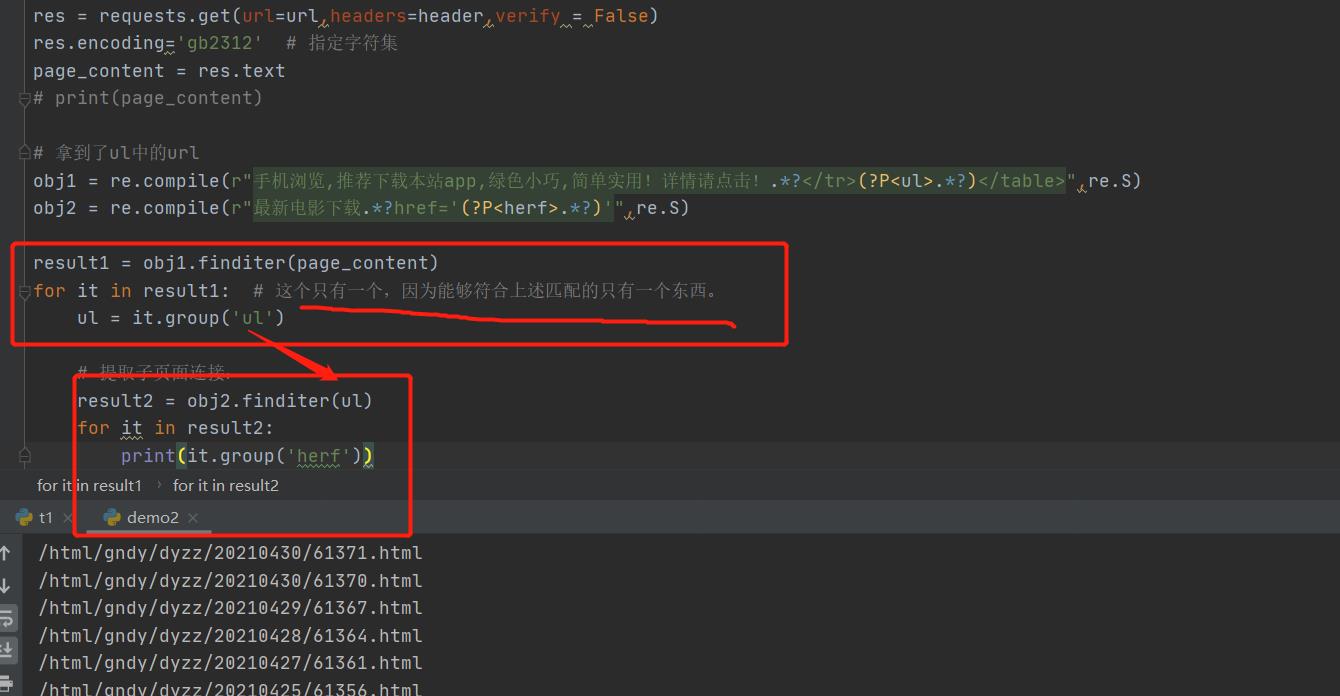
2.从2021新片精品中提取到子页面的链接地址
3.请求子页面的链接地址,拿到我们想要的下载地址…
# -*- coding: utf-8 -*-
# @Time: 2021/5/5 14:05
# @Author: adam
# @File: demo2.py
import csv
import re
import requests
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
domain='https://www.dytt8.net/index.htm'
res = requests.get(url=domain,headers=header,verify = False)
res.encoding='gb2312' # 指定字符集
page_content = res.text
# print(page_content)
# 拿到了ul中的url
obj1 = re.compile(r"手机浏览,推荐下载本站app,绿色小巧,简单实用!详情请点击!.*?</tr>(?P<ul>.*?)</table>",re.S)
obj2 = re.compile(r"最新电影下载.*?href='(?P<herf>.*?)'",re.S)
child_href_list = []
result1 = obj1.finditer(page_content)
for it in result1: # 这个只有一个,因为能够符合上述匹配的只有一个东西。
ul = it.group('ul')
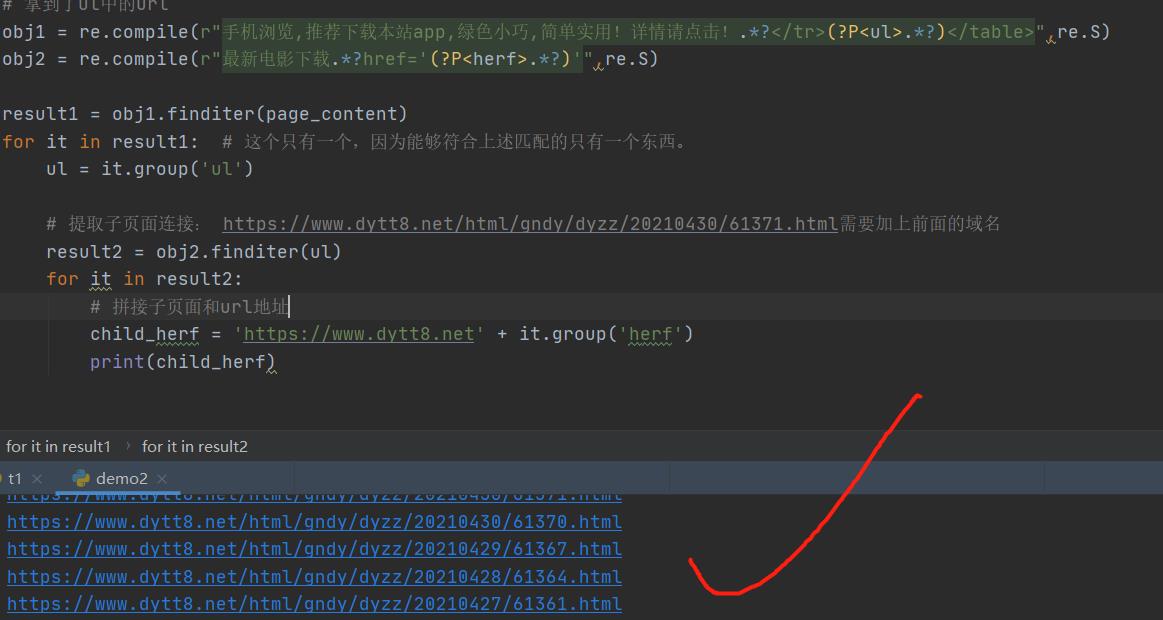
# 提取子页面连接: https://www.dytt8.net/html/gndy/dyzz/20210430/61371.html需要加上前面的域名
result2 = obj2.finditer(ul)
for it in result2:
# 拼接子页面和url地址
child_herf = 'https://www.dytt8.net' + it.group('herf')
child_href_list.append(child_herf) # 把子页面的连接保存在一个 列表中。
# 提取 子页面内容。
for herf in child_href_list:
child_resp = requests.get(url=herf,verify=False)
child_resp.encoding='gb2312'
child_page_content = child_resp.text
print(child_page_content)
break # 测试用的
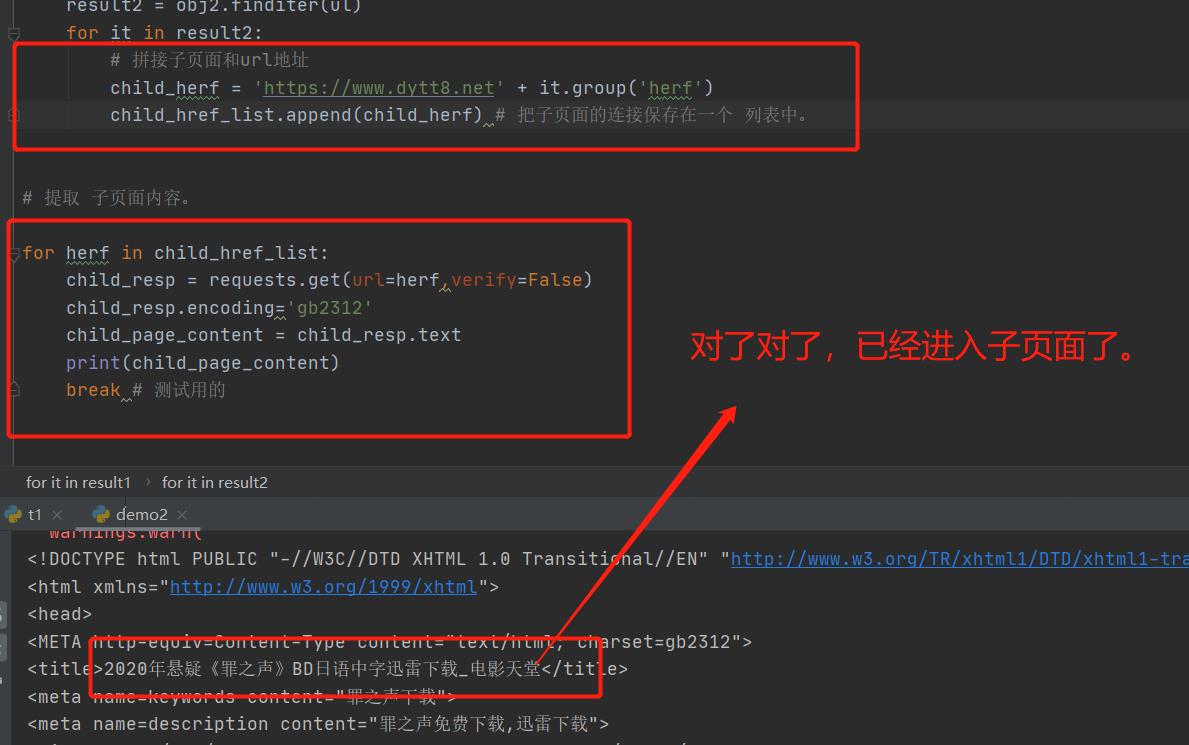
进入页面之后,就是找下载地址了。

nice,就只有这个一个地方,直接就找到url了。
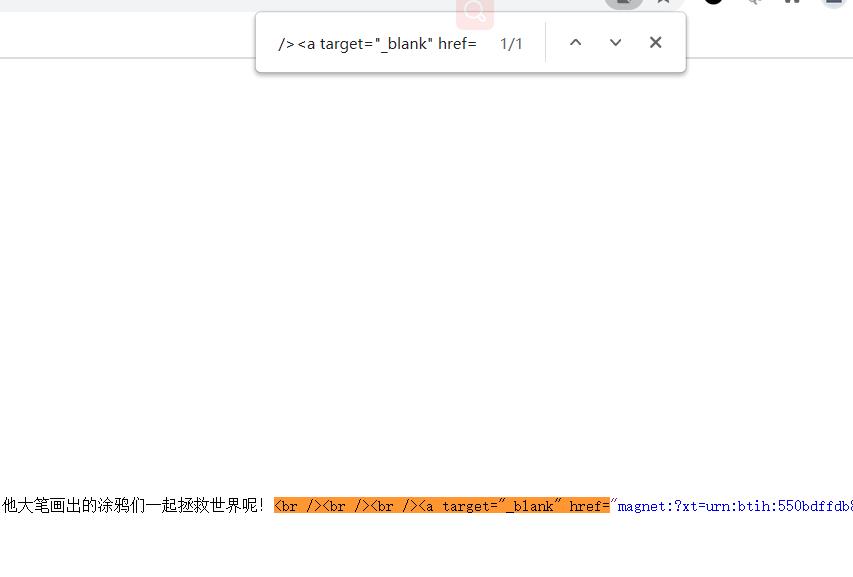
最终代码:
# -*- coding: utf-8 -*-
# @Time: 2021/5/5 14:05
# @Author: adam
# @File: demo2.py
import csv
import re
import requests
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
domain='https://www.dytt8.net/index.htm'
res = requests.get(url=domain,headers=header,verify = False)
res.encoding='gb2312' # 指定字符集
page_content = res.text
# print(page_content)
# 拿到了ul中的url
obj1 = re.compile(r"手机浏览,推荐下载本站app,绿色小巧,简单实用!详情请点击!.*?</tr>(?P<ul>.*?)</table>",re.S)
obj2 = re.compile(r"最新电影下载.*?href='(?P<herf>.*?)'",re.S)
obj3 = re.compile(r'◎片 名(?P<movie_name>.*?)<br />.*?<br /><br /><br /><a target="_blank" href="(?P<movie_url>.*?)"')
child_href_list = []
result1 = obj1.finditer(page_content)
for it in result1: # 这个只有一个,因为能够符合上述匹配的只有一个东西。
ul = it.group('ul')
# 提取子页面连接: https://www.dytt8.net/html/gndy/dyzz/20210430/61371.html需要加上前面的域名
result2 = obj2.finditer(ul)
for itt in result2:
# 拼接子页面和url地址
child_herf = 'https://www.dytt8.net' + itt.group('herf')
# print(child_herf)
child_href_list.append(child_herf) # 把子页面的连接保存在一个 列表中。
# 提取 子页面内容。
for herf in child_href_list:
child_resp = requests.get(url=herf,verify=False)
child_resp.encoding='gb2312'
child_page_content = child_resp.text
# print(child_page_content)
# break # 测试用的
result3 = obj3.finditer(child_page_content)
for ittt in result3:
print(ittt.group('movie_name'),end=' ')
print(ittt.group('movie_url'))
以上是关于爬虫学习 ----- 第二章 爬取静态网站 ---------- 03 . re 模块学习 ---- re屠戮电影天堂的主要内容,如果未能解决你的问题,请参考以下文章