机器学习---吴恩达---Week6_1(机器学习改进方法)
Posted zouhq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习---吴恩达---Week6_1(机器学习改进方法)相关的知识,希望对你有一定的参考价值。
应用机器学习
Machine Learning Diagnostics(机器学习诊断)
Diagnostic is a test you can run, to get insight into what is or isn‘t working with an algorithm, and which will often give you insight as to what are promising things to try to improve a learning algorithm‘s performance. Anddiagnostics can taketake quite a lot of time to implement and understand but doing so can be a very good use of your time when you are developing learning algorithms because they can often save you from spending many months pursuing an avenue that you could have found out much earlier just was not going to be fruitful.time to implement and can sometimes,翻译:诊断是一项可以运行的测试,可以深入了解使用算法做什么或不做什么,并且通常可以让您深入了解尝试提高学习算法性能的方法。 诊断可能需要一段时间代价实现,即有时可能会花费大量时间运行,但这样做仍是可以很好地利用开发学习算法的时间,因为它们通常可以帮助避免花费数月时间来尝试一条并不会有多大成效的方法。
Evaluating a Hypothesis(评估预测函数)
回归分析出现问题时的改进思路:
- Getting more training examples(增加训练样本)
- Trying smaller sets of features(减少训练特征)
- Trying additional features(增加新的特征)
- Trying polynomial features(使用多项式回归)
- Increasing or decreasing λ(增大或减小λ)
Evaluating a Hypothesis
Given a dataset of training examples, we can split up the data into two sets: a training set and a test set. Typically, the training set consists of 70 % of your data and the test set is the remaining 30 %.(将训练集分成两部分,70%用作训练,30%用作测试)
训练过程
方法一:
- Learn Θ and minimize Jtrain(Θ) using the training set(使用训练数据获得损失函数)
- Compute the test set error Jtest(Θ)(计算测试数据部分的损失函数)
方法二:
- Learn Θ and minimize Jtrain(Θ) using the training set(使用训练数据获得损失函数)
- Compute theMisclassification error (aka 0/1 misclassification error):(计算分类错误率)---适用于多类别分类
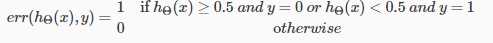
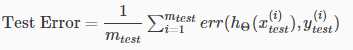
Model Selection Problem(模型选择问题)
Given many models with different polynomial degrees, we can use a systematic approach to identify the ‘best‘ function.(从多个不同阶的多项式中选出预测性最好的多项式回归模型)
Train/Validation/Test Sets
将训练数据分成三个不同的数据集,分别为训练集、交叉验证集与测试集
- Training set: 60%
- Cross validation set: 20%
- Test set: 20%
模型选择过程
- Optimize the parameters in Θ using the training set for each polynomial degree.(使用训练集得到不同模型的参数Θ )
- Find the polynomial degree d with the least error using the cross validation set.(使用验证集获得各个多项式模型的误差损失函数)
- Estimate the generalization error using the test set with Jtest(Θ(d)), (d = theta from polynomial with lower error);(对误差小的模型使用测试集获得其误差损失值)
Diagnosing Bias vs. Variance
- We need to distinguish whether bias or variance is the problem contributing to bad predictions.(偏差与方差)
- High bias is underfitting and high variance is overfitting. Ideally, we need to find a golden mean between these two.(欠拟合与过拟合)
The training error will tend to decrease as we increase the degree d of the polynomial. At the same time, the cross validation error will tend to decrease as we increase d up to a point, and then it will increase as d is increased, forming a convex curve.(训练误差不断减小,验证与测试误差减小到某点后剧烈增大)
High bias (underfitting): both Jtrain(Θ) and JCV(Θ) will be high. Also, JCV(Θ)≈Jtrain(Θ).
High variance (overfitting): Jtrain(Θ) will be low and JCV(Θ) will be much greater than Jtrain(Θ).
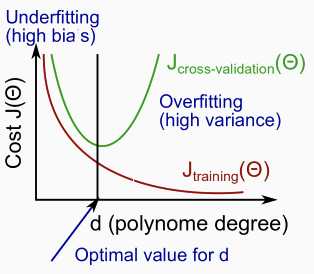
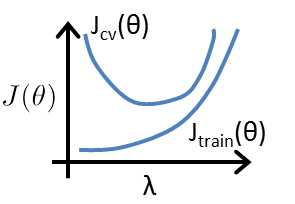
Regularization and Bias/Variance(正则化与偏差方差)
问题:
In the figure above, we see that as λ increases, our fit becomes more rigid. On the other hand, as λ approaches 0, we tend to over overfit the data.(对于过拟合模型,λ偏小表现过拟合,λ 偏大,表现欠拟合)
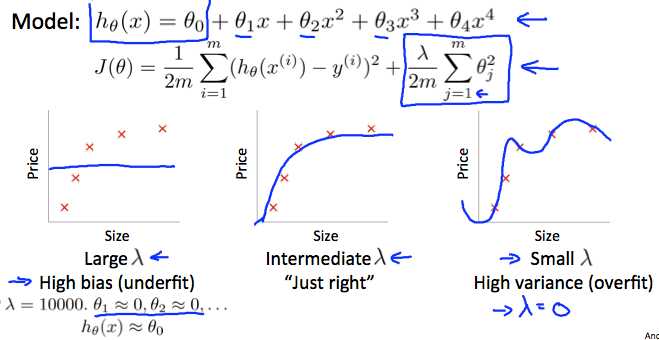
选择合适的λ的方法:
- Create a list of lambdas (i.e. λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24});(使用一定区间范围的λ )
- Create a set of models with different degrees or any other variants.(使用不同λ 的模型)
- Iterate through the λs and for each λ go through all the models to learn some Θ.λ(获得对应模型的参数值)
- Compute the cross validation error using the learned Θ (computed with λ) on the JCV(Θ) without regularization or λ = 0.(使用得到的参数值和λ 计算验证误差)
- Select the best combo that produces the lowest error on the cross validation set.(选择最好具有最小验证误差的λ )
- Using the best combo Θ and λ, apply it on Jtest(Θ) to see if it has a good generalization of the problem.(使用上述最优模型的参数值与λ 进行测试观察是否能够预测问题)
Learning Curves(学习曲线)
Experiencing high bias:
Low training set size: causes Jtrain(Θ) to be low and JCV(Θ) to be high.(小训练数据:训练集误差小,验证集误差大)
Large training set size: causes both Jtrain(Θ) and JCV(Θ) to be high with Jtrain(Θ)≈JCV(Θ).(大训练数据:训练集误差增大,验证误差减小,二者同一水平)
If a learning algorithm is suffering from high bias, getting more training data will not (by itself) help much.高偏差情况,增大训练数据不能有效改善线训练结果)

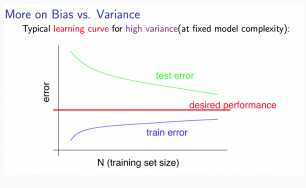
Experiencing high variance:
Low training set size: Jtrain(Θ) will be low and JCV(Θ) will be high.(小训练数据:训练误差小,验证误差大)
Large training set size: Jtrain(Θ) increases with training set size and JCV(Θ) continues to decrease without leveling off. Also, Jtrain(Θ) < JCV(Θ) but the difference between them remains significant.(大训练数据:训练集误差增大,验证误差减小,二者具有一个明显gap)
If a learning algorithm is suffering from high variance, getting more training data is likely to help..高方差情况,增大训练数据可以有效改善线训练结果)
不同问题的针对解决办法
- Getting more training examples: Fixes high variance(增加训练数据---解决高方差)
- Trying smaller sets of features: Fixes high variance(减少训练特征---解决高方差)
- Adding features: Fixes high bias(增加训练特征---解决高偏差)
- Adding polynomial features: Fixes high bias(增加多项式拟合---解决高偏差)
- Decreasing λ: Fixes high bias(增大λ---解决高偏差)
- Increasing λ: Fixes high variance.(减小λ---解决高方差)
Diagnosing Neural Networks(神经网络诊断)
- A neural network with fewer parameters is prone to underfitting. It is also computationally cheaper.(小型神经网络容易欠拟合,计算量小)
- A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the overfitting.(大型神经网络容易过拟合,增大λ可以解决此问题,不过计算量大)
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.(默认使用一个隐藏层是好的开始,可以使用通过不同的验证集选择合适的隐藏层层数)
Model Complexity Effects:(模型复杂度影响)
- Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.(低阶多项式高偏差低方程,拟合性较差)
- Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.(高阶多项式拟合性较好,一般具有低偏差高方差的特点)
- In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.(实际应用应选择拟合性和的同时预测性强的多项式模型)
以上是关于机器学习---吴恩达---Week6_1(机器学习改进方法)的主要内容,如果未能解决你的问题,请参考以下文章
机器学习- 吴恩达Andrew Ng Week6 知识总结 Machine Learning System Design
机器学习- 吴恩达Andrew Ng Week6 Regularized Linear Regression and Bias/Variance知识总结
机器学习- 吴恩达Andrew Ng 编程作业技巧 for Week6 Advice for Applying Machine Learning