机器学习- 吴恩达Andrew Ng Week6 知识总结 Machine Learning System Design
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习- 吴恩达Andrew Ng Week6 知识总结 Machine Learning System Design相关的知识,希望对你有一定的参考价值。
Coursera课程地址
因为Coursera的课程还有考试和论坛,后续的笔记是基于Coursera
https://www.coursera.org/learn/machine-learning/home/welcome
ML:机器学习系统设计 Machine Learning System Design
1. 优先处理什么 Prioritizing what to work on: Spam classification example
垃圾邮件拆分词,用分类方法分类

我们可以通过不同的方式解决机器学习问题:
- 收集大量数据(例如“蜜罐”项目但并不总是有效)
- 开发复杂的功能(例如:在垃圾邮件中使用电子邮件标题数据)
- 开发算法以不同的方式处理您的输入(识别垃圾邮件中的拼写错误)。
很难说哪些选项会有所帮助。

2. 误差分析 Error analysis
解决机器学习问题的推荐方法是:
- 从一个简单的算法开始,快速实现,并尽早测试。
- 绘制学习曲线以确定更多数据、更多特征等是否有帮助
- 错误分析:手动检查交叉验证集中示例的错误并尝试发现趋势。

将错误结果作为单个数值获取非常重要。否则很难评估算法的性能。

您可能需要在输入有用之前对其进行处理。例如,如果您输入的是一组单词,您可能希望将具有不同形式(失败/失败/失败)的同一个单词视为一个单词,因此必须使用“词干提取软件”将它们全部识别为一个。

3. 偏斜类的错误度量 Error metrics for skewed classes
有时很难判断错误的减少是否实际上是算法的改进。

- 例如:在预测癌症诊断时,其中 0.5% 的示例患有癌症,我们发现我们的学习算法有 1% 的错误。但是,如果我们简单地将每个示例归类为 0,那么即使我们没有改进算法,我们的错误也会减少到 0.5%。
这通常发生在倾斜的类中;也就是说,当我们的类在整个数据集中非常罕见时。
或者换一种说法,当我们从一个分类中获得的例子比来自另一分类的例子多得多。
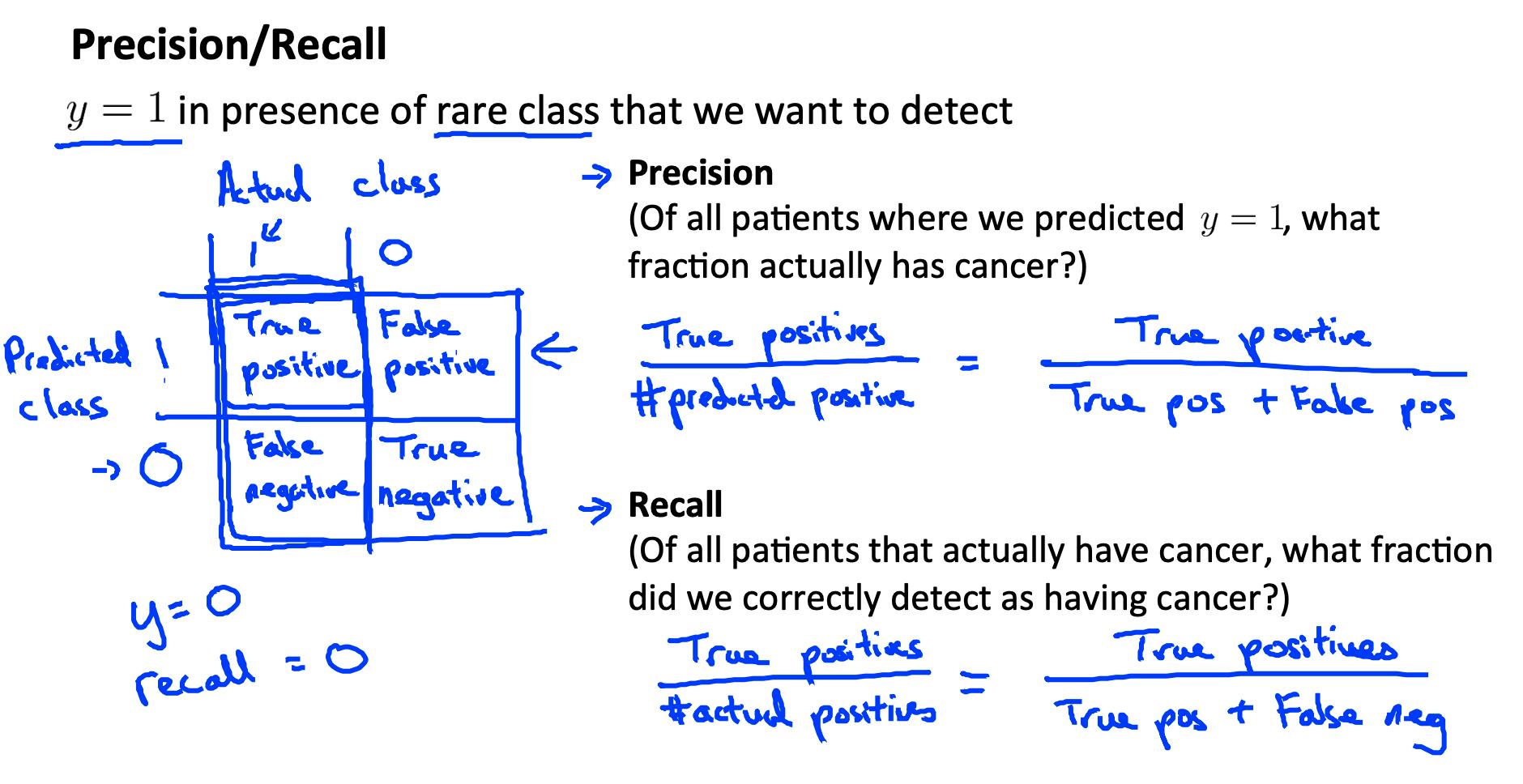
为此,我们可以使用准确率Precision/召回率Recall。
- 预测:1,实际:1 — 真阳性
- 预测:0,实际:0 — 真负
- 预测:0,实际,1 — 假阴性
- 预测:1,实际:0 — 误报
精确度:在我们预测的所有患者中,y=1,实际患有癌症的比例是多少?
真正的积极因素 / 预测阳性总数 = 真正的积极因素 / (真阳性+假阳性)
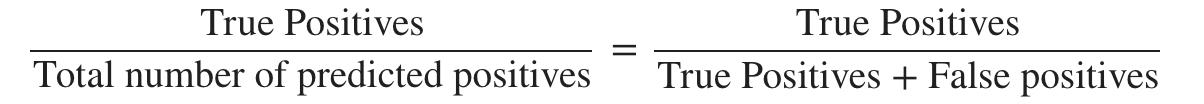
回想一下:在所有实际患有癌症的患者中,我们正确检测出患有癌症的比例是多少?
实际阳性总数 \\ 真正的积极因素 = 真正的积极因素 \\ (真正的积极因素+假阴性)
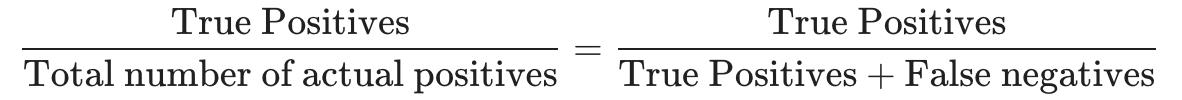
这两个指标让我们更好地了解分类器的表现。我们希望准确率和召回率都很高。
在本节开头的示例中,如果我们将所有患者归类为 0,那么我们的召回将是0 / (0 + f) = 0 ,因此尽管错误率较低,但我们可以很快看到它的召回率更差。
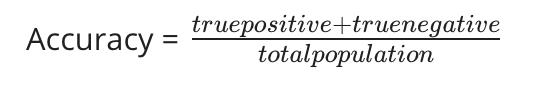
注 1:如果一个算法只预测负数,就像它在一个练习中所做的那样,精度没有定义,不可能除以 0。F1 分数也不会被定义。
4. 权衡精度和召回率 Trading off precision and recall
我们可能想要使用逻辑回归对两个类别进行可靠的预测。一种方法是提高我们的门槛:

- 预测 1 如果: Hθ(x) >= 0.7
- 预测 0 如果: Hθ(x) < 0.7
这样,我们只有在患者有 70% 的机会时才能预测癌症。
这样做,我们将获得更高的精度但更低的召回率(请参阅上一节中的定义)。
在相反的例子中,我们可以降低阈值:
- 预测 1 如果: Hθ(x) >= 0.3
- 预测 0 如果: Hθ(x) < 0.3
这样,我们就得到了一个非常安全的预测。这将导致较高的召回率但较低的精度。
阈值越大,精度越高,召回率越低。
阈值越低,召回率越大,精度越低。
为了将这两个指标合二为一,我们可以取F 值。
一种方法是取平均值:(P + R) / 2
这行不通。如果我们预测所有 y=0,那么尽管召回率为 0,但平均值会提高。如果我们将所有示例预测为 y=1,那么尽管精度为 0,但非常高的召回率将提高平均值。
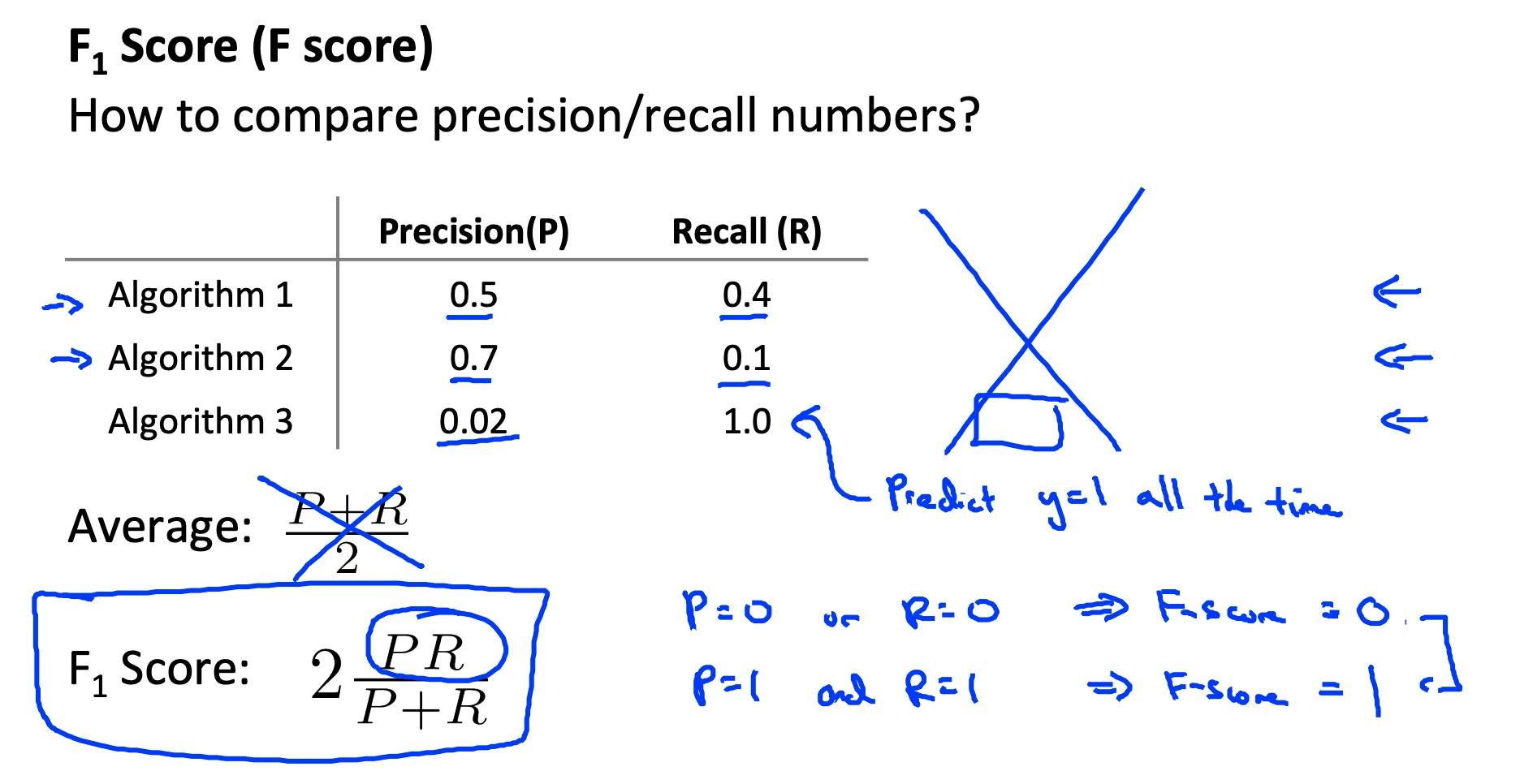
更好的方法是计算F 分数(或 F1 分数): F Score = 2 * PR / (P + R)
为了使 F Score 大,精度和召回率都必须大。
我们希望在交叉验证集上训练精度和召回率,以免使我们的测试集产生偏差。
5. 机器学习数据 Data for machine learning
我们应该训练多少数据?
在某些情况下,如果给定足够的数据,“劣等算法”可以胜过使用较少数据的高级算法。

我们必须选择我们的特征以获得足够的信息。一个有用的测试是:给定输入 x,人类专家能否自信地预测 y?

大数据的基本原理:如果我们有一个低偏差算法(许多特征或隐藏单元构成一个非常复杂的函数),那么我们使用的训练集越大,过拟合就越少(算法越准确)测试集)。

6. 测验说明
当测验说明告诉您输入“两位十进制数字”的值时,它的真正含义是“两位有效数字”。因此,例如,值 0.0123 应输入为“0.012”,而不是“0.01”。
参考
- https://class.coursera.org/ml/lecture/index
- http://www.cedar.buffalo.edu/~srihari/CSE555/Chap9.Part2.pdf
- http://blog.stephenpurpura.com/post/13052575854/managing-bias-variance-tradeoff-in-machine-learning
- http://www.cedar.buffalo.edu/~srihari/CSE574/Chap3/Bias-Variance.pdf
参考
https://www.coursera.org/learn/machine-learning/resources/LIZza
https://www.coursera.org/learn/machine-learning/supplement/gFC7y/lecture-slides
以上是关于机器学习- 吴恩达Andrew Ng Week6 知识总结 Machine Learning System Design的主要内容,如果未能解决你的问题,请参考以下文章