爬取动态页面2
Posted knighterrant
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取动态页面2相关的知识,希望对你有一定的参考价值。
动态页面的爬取思路:
1. ajax -----数据放在 json 中,在里面是否有url
2. js 数据 通过 搜索原页面上的数据关键字 :ctrl + f , 全局搜索关键字
例子:
开始网站 url = ‘https://www.xuexi.cn/‘
爬取的页面1:
url 1= ‘https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html‘
需求:爬取url1 所有新闻的详情页面
分析思路:图示
用 js 数据动态生成的思路 : 通过 搜索原页面上的数据关键字 :ctrl + f , 全局搜索关键字
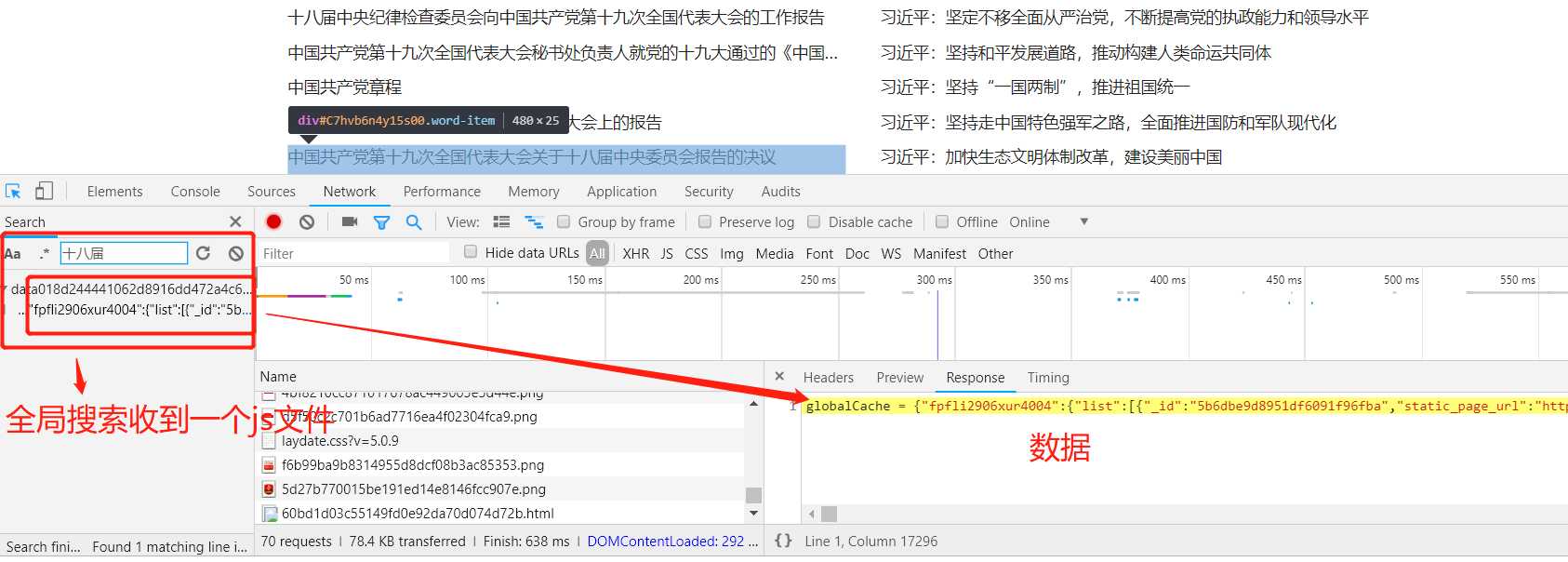
爬取的页面2:
url 2= ‘https://www.xuexi.cn/261c9a142ef8e6375ed554815a26d585/f2d8ff735982530b7a8c9bb90fa99f68.html‘
需求:爬取url2 所有新闻的详情页面
分析思路:
先按思路 ,js 动态生成数据的思路,找,没找到在按ajax 动态生成数据的思路。
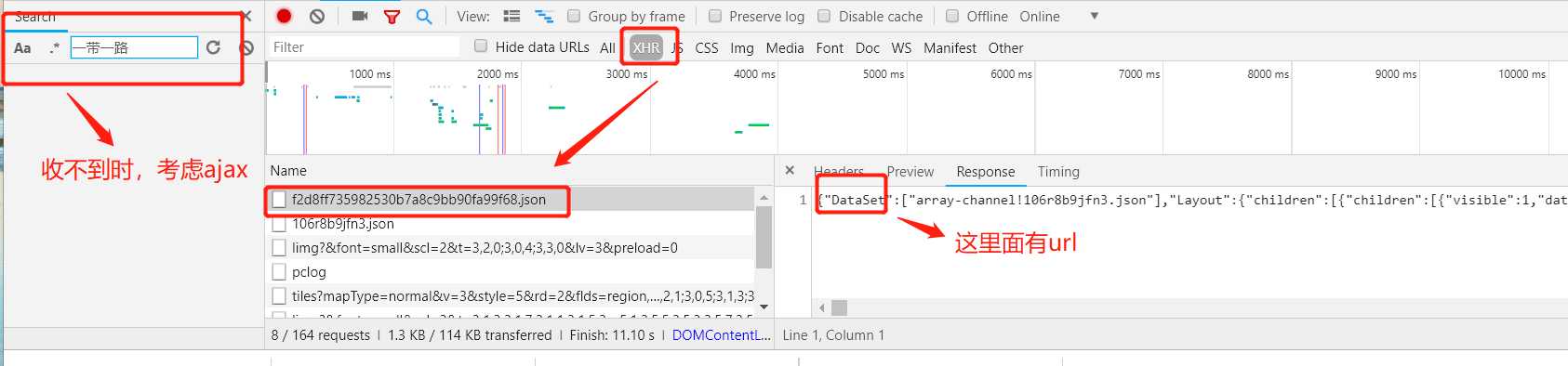
用 ajax动态生成的思路 : ajax -----数据放在 json 中,在里面是否有数据。(此处为ajax)
图示:

代码:
import requests 分析之后得到获取数据的url地址: url1 文需求1 的数据地址,url2 为需求2 的数据获取地址。 url1 = ‘https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/data018d244441062d8916dd472a4c6a0a0b.js‘ url2 = ‘https://www.xuexi.cn/lgdata/261c9a142ef8e6375ed554815a26d585/f2d8ff735982530b7a8c9bb90fa99f68.json‘ headers={ ‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.67 Safari/537.36‘ }
res1 = requests.get(url=url2,headers=headers)
res2 = requests.get(url=url2,headers=headers)
print(res1.content.decode())
print(res2.content.decode())
以上是关于爬取动态页面2的主要内容,如果未能解决你的问题,请参考以下文章