BOOK动态渲染页面爬取--Selenium库
Posted motoharu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BOOK动态渲染页面爬取--Selenium库相关的知识,希望对你有一定的参考价值。
动态渲染页面爬取
JavaScript动态渲染
其中一种方式是Ajax请求,通过直接分析Ajax再用requests来实现数据爬取
另外一种方式是模拟浏览器运行
一、 Selenium库
Selenium是自动化测试工具,可以驱动浏览器执行特定动作(点击、下拉),还可以获取浏览器当前呈现页面的源代码,可见即可爬
1、模拟 Chrome浏览器,一定要先配置chromedriver
(1)先查看Chrome版本,在浏览器中输入chrome://version/

(2)下载地址:https://npm.taobao.org/mirrors/chromedriver/
下载与浏览器同版本的chromedriver

将下载的chromedriver复制到安装的Chrome文件夹下
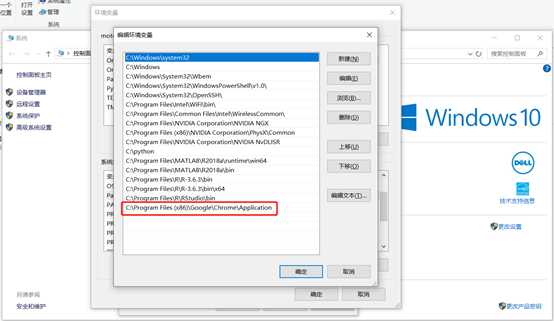
(3) 配置环境变量
将Chrome目录复制到PATH内
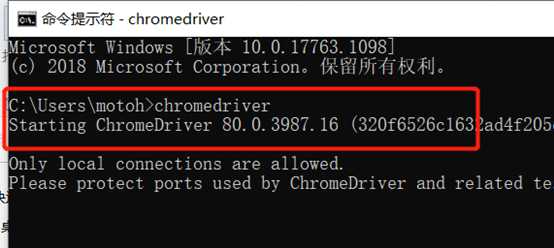
(4)测试是否安装成功
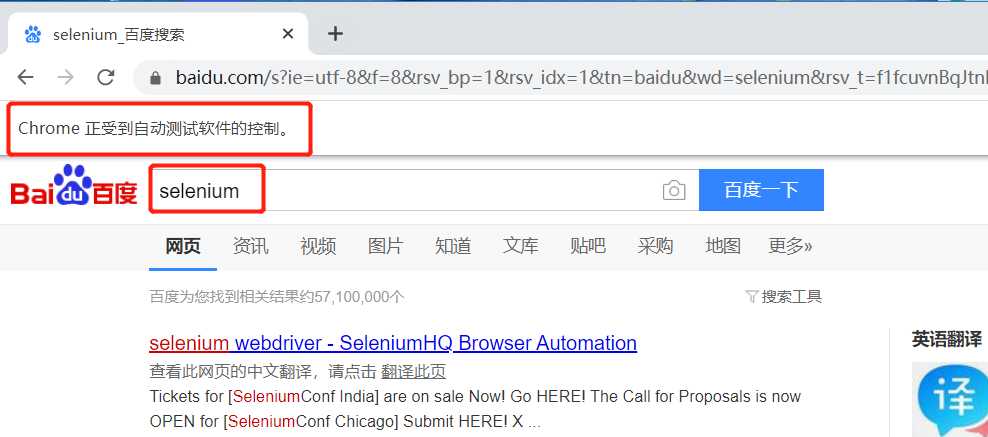
2、小小实例,模拟Chrome浏览器,访问百度,搜索‘selenium’
from selenium import webdriver
from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait
##chromedriver的目录 chrome_driver=r‘C:Program Files (x86)GoogleChromeApplicationchromedriver.exe‘ browser = webdriver.Chrome(executable_path=chrome_driver) browser.get(‘http://www.baidu.com‘) input = browser.find_element_by_id(‘kw‘) input.send_keys(‘selenium‘) input.send_keys(Keys.ENTER) wait = WebDriverWait(browser, 10) wait.until(EC.presence_of_all_elements_located((By.ID, ‘content_left‘))) print(browser.current_url) print(browser.get_cookies()) print(browser.page_source)
运行结果:浏览器自动打开,进入百度,然后搜索
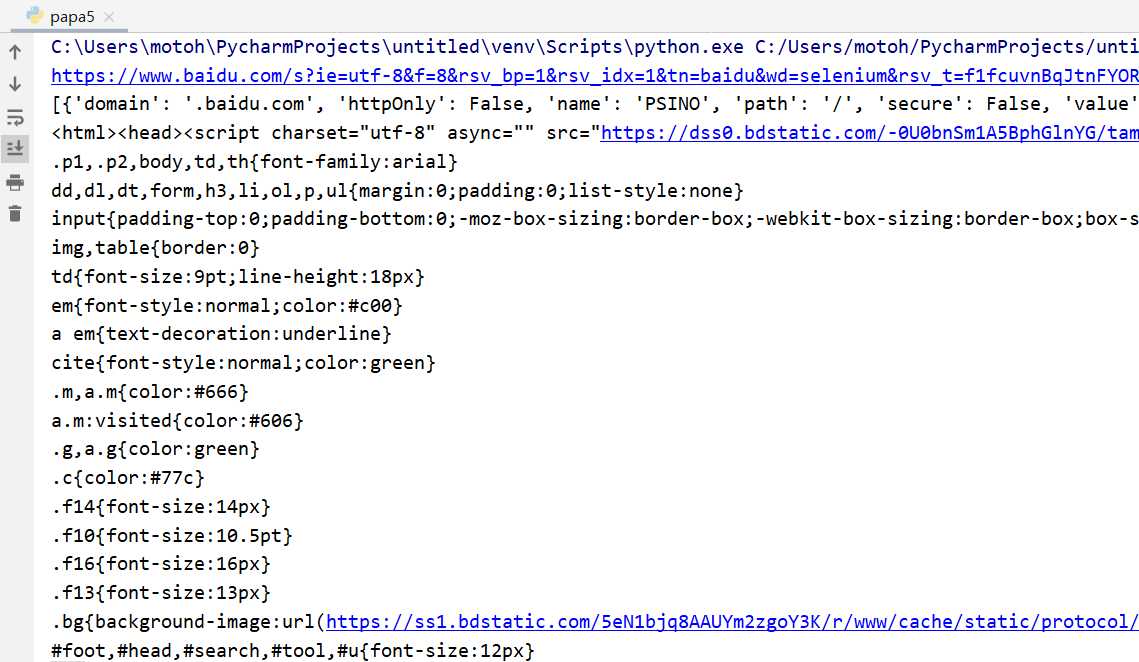
输出当前的URL、Cookies、源代码等等
报错:FileNotFoundError: [WinError 2] 系统找不到指定的文件
打开报错提示中subprocess.py
找到 __init__函数 中的shell = False 改成shell = True
3、声明浏览器对象
from selenium import webdriver ## 浏览器对象初始化并赋值给 browser 对象 ## selenium支持各种浏览器 browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.Edge() browser = webdriver.Ie() ## 还支持无界面浏览器 browser = webdriver.PhantomJS() ## 支持手机端浏览器 browser = webdriver.android() browser = webdriver.BlackBerry() browser = webdriver.Safari()
4、访问页面
from selenium import webdriver # 浏览器对象初始化并赋值给 browser 对象 browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) ## 输出淘宝页面的源代码 print(browser.page_source) browser.close()
5、查找节点
①获取单个节点的方法
## 查找单个节点 ## 查找淘宝首页的搜索框 ## <input id="q" name="q" aria-label="请输入搜索文字" accesskey="s" autofocus="autofocus" autocomplete="off" class="search-combobox-input" aria-haspopup="true" aria-combobox="list" role="combobox" x-webkit-grammar="builtin:translate"> from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) ## find_element_by_id() 根据 id 获取 input_first = browser.find_element_by_id(‘q‘) ## find_element_by_name() 根据 name 获取 input_second = browser.find_element_by_name(‘q‘) ## CSS选择器获取 input_third = browser.find_elements_by_css_selector(‘#q‘) ## XPath选择器获取 input_forth = browser.find_element_by_xpath(‘//*[@id="q"]‘) ## 4个查找结果相同 ## 返回结果为 WebElement 类型 print(input_first, input_second, input_third, input_forth) browser.close()
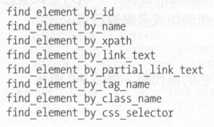
find_element(查找方式By , 值)
from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) ## find_element(By.ID, ‘q‘) 等价于 browser.find_element_by_id(‘q‘) input_first = browser.find_element(By.ID, ‘q‘) print(input_first) browser.close()
②获取多个节点的方法
find_element()只能返回第一个结果
find_elements()只能返回查找到的所有结果,返回列表类型
from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) ## 返回查找到的所有结果, 列表类型 lis = browser.find_elements_by_css_selector(‘.service-bd li‘) print(lis) browser.close() list = browser.find_elements(By.CSS_SELECTOR, ‘.service-bd li‘) print(list)

6、节点交互
Selenium可以驱动浏览器执行一些操作
※输入文字 send_key( )
※清空文字 clear( )
※点击按钮 click( )
from selenium import webdriver import time browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) ## 获取搜索输入框 input = browser.find_element_by_id(‘q‘) ## 输入 ‘T恤‘ 关键字进 input.send_keys(‘T恤‘) time.sleep(1) ## 清空搜索框 input.clear() ## 输入 ‘连衣裙‘ 关键字 input.send_keys(‘连衣裙‘) botton = browser.find_element_by_class_name(‘btn-search‘) ## 点击搜索按钮,完成搜索 botton.click()
7、动作链ActionChains:鼠标拖拽、键盘按键等
## 实现模拟鼠标拖拽 from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = ‘https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘ browser.get(url) browser.switch_to.frame(‘iframeResult‘) source = browser.find_element_by_css_selector(‘#draggable‘) target = browser.find_element_by_css_selector(‘#droppable‘) actions = ActionChains(browser) actions.drag_and_drop(source, target) actions.perform()
8、执行JavaScript
Selenium API 没有提供的功能,都可以用执行JavaScript 来实现
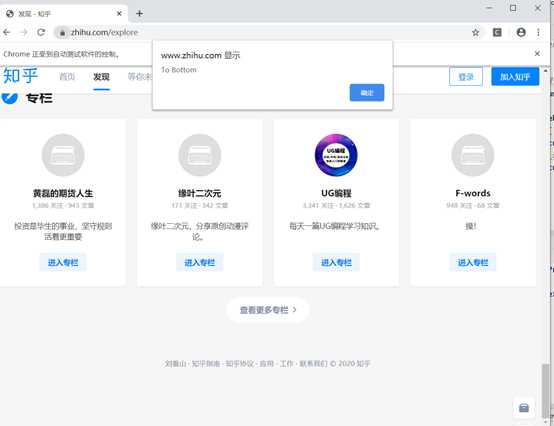
比如:下拉进度条
# 模拟下拉进度条
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.zhihu.com/explore‘)
## execute_script()方法将进度条拖至最底部
browser.execute_script(‘window.scrollTo(0, document.body.scrollHeight)‘)
## 弹出alert提示框
browser.execute_script(‘alert("To Bottom")‘)
运行结果:
9、获取节点信息
page_source可以获得页面源代码,再用解析库来提取信息
但Selenium提供了选择节点的方法,返回WebElement类型,就可以不用解析库进行解析
from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() browser.get(‘https://www.zhihu.com/explore‘) ## 获取属性 get_attribute() col = browser.find_element_by_id(‘collection‘) print(col.get_attribute(‘class‘)) ## 获取文本值 text input = browser.find_element_by_css_selector(‘.ExploreRoundtableCard-questionTitle‘) print(input.text) ## 获取id等其他属性值 print(input.id) print(input.location) print(input.tag_name) print(input.size)
10、切换 Frame
switch_to.frame()
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
browser.get(‘https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable‘)
## 切换到 子Frame
browser.switch_to.frame(‘iframeResult‘)
try:
logo = browser.find_element_by_class_name(‘logo‘)
except NoSuchElementException:
print(‘No logo‘)
## 切换到 父Frame
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name(‘logo‘)
print(logo)
print(logo.text)
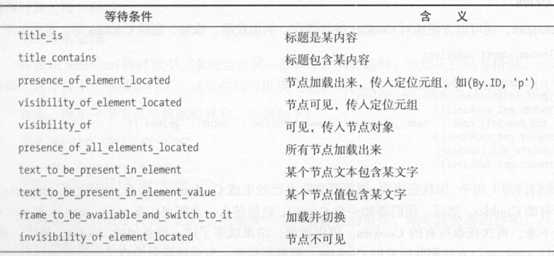
11、延时等待
Selenium中,get()方法在网页框架加载结束后执行,但是有些额外的Ajax请求可能没有加载完,需要延时等待一段时间,确保节点全部加载。
※隐式等待
如果没有找到指定节点,则继续等待设定时间,超出设定时间抛出异常
implicitly_wait()
from selenium import webdriver browser = webdriver.Chrome() ## 隐式等待 10s browser.implicitly_wait(10) browser.get(‘https://www.zhihu.com/explore‘) input = browser.find_element_by_class_name(‘App-main‘) print(input)
※显式等待【比隐式好一点】
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.get(‘https://www.taobao.com‘) ## 设定最长等待时间 wait = WebDriverWait(browser, 10) ## 10s内 ID为 q 的节点成功加载,则返回该节点,否则抛出异常 input = wait.until(EC.presence_of_element_located((By.ID, ‘q‘))) ## 10s该按钮是可点击的,就返回这个按钮,否则抛出异常 button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ‘.btn-search‘))) print(input, button)

12、前进和后退
## 前进和后退 import time from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.baidu.com‘) browser.get(‘https://www.taobao.com‘) browser.get(‘https://www.zhihu.com‘) ## 后退 browser.back() time.sleep(5) ## 前进 browser.forward() browser.close()
13、对cookies进行操作:获取、添加、删除cookies
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘https://www.zhihu.com/explore‘)
## get_cookies()获取所有cookies
print(browser.get_cookies())
## 以字典形式添加新的 cookies
browser.add_cookie({‘name‘:‘name‘, ‘domain‘:‘www.zhihu.com‘, ‘value‘:‘germey‘})
print(browser.get_cookies())
## 删除所有 cookies
browser.delete_all_cookies()
print(browser.get_cookies())
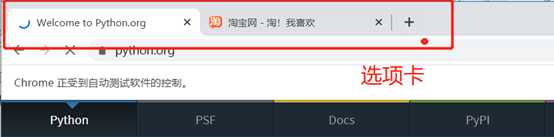
14、选项卡管理
# 对选项卡进行操作 import time from selenium import webdriver browser = webdriver.Chrome() browser.get(‘https://www.baidu.com‘) ## window.open() javascript语句新开启一个选项卡 browser.execute_script(‘window.open()‘) print(browser.window_handles) ## 切换到新的选项卡 browser.switch_to_window(browser.window_handles[1]) browser.get(‘https://www.taobao.com‘) time.sleep(1) ## 切换到第一个选项卡 browser.switch_to_window(browser.window_handles[0]) browser.get(‘https://python.org‘)
15、异常处理
## 节点未找到节点
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get(‘https://www.baidu.com‘)
except TimeoutException:
print(‘超时‘)
try:
browser.find_element_by_id(‘hello‘)
except NoSuchElementException:
print(‘未找到指定节点‘)
finally:
browser.close()
以上是关于BOOK动态渲染页面爬取--Selenium库的主要内容,如果未能解决你的问题,请参考以下文章