Python 爬虫实例—— 爬取 动态页面
Posted 编程人生改变命运
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫实例—— 爬取 动态页面相关的知识,希望对你有一定的参考价值。
今天使用python 和selenium爬取动态数据,主要是通过不停的更新页面,实现数据的爬取,要爬取的数据如下图
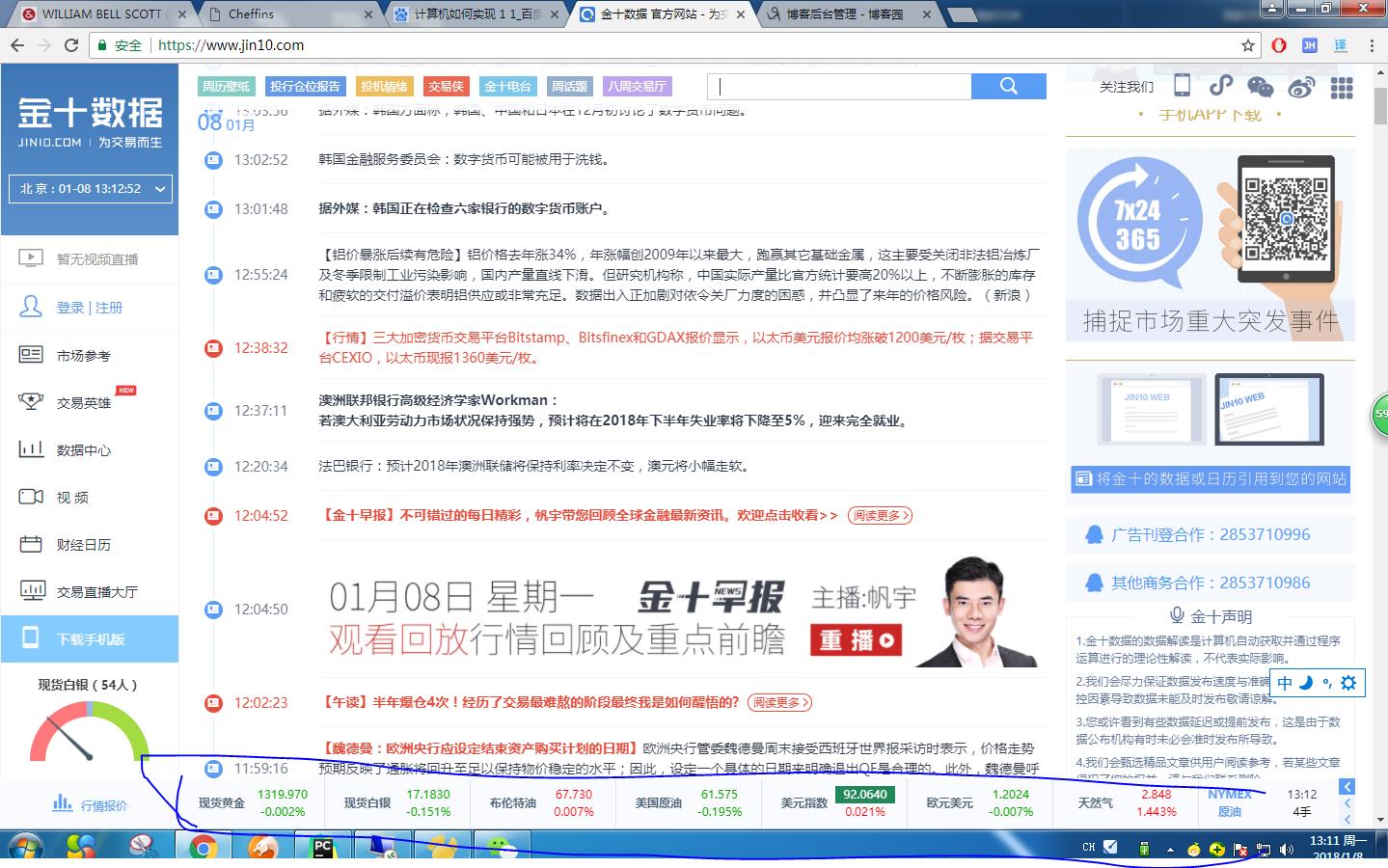
源代码:
#-*-coding:utf-8-*- import time from selenium import webdriver import os import re #引入chromedriver.exe chromedriver = "C:/Users/xuchunlin/AppData/Local/Google/Chrome/Application/chromedriver.exe" os.environ["webdriver.chrome.driver"] = chromedriver browser = webdriver.Chrome(chromedriver) #设置浏览器需要打开的url url = "https://www.jin10.com/" # 使用for循环不停的刷新页面,也可以每隔一段时间刷新页面 for i in range(1,100000): browser.get(url) result= browser.page_source gold_price = "" gold_price_change = "" try: gold_price = re.findall(\'<div id="XAUUSD_B" class="jin-price_value" style=".*?">(.*?)</div>\',result)[0] gold_price_change = re.findall(\'<div id="XAUUSD_P" class="jin-price_value" style=".*?">(.*?)</div>\',result)[0] except: gold_pric = "------" gold_price_change = "------" print gold_price print gold_price_change time.sleep(1)
以上是关于Python 爬虫实例—— 爬取 动态页面的主要内容,如果未能解决你的问题,请参考以下文章