Flink编程入门
Posted advise09
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink编程入门相关的知识,希望对你有一定的参考价值。
1. Flink的引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
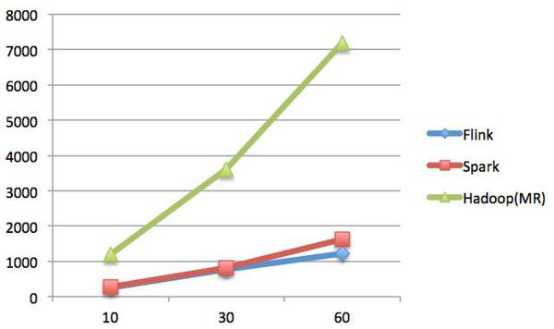
首先,我们可以通过下面的性能测试初步了解两个框架的性能区别,它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink计算性能上略好。
测试环境:
1.CPU:7000个;
2.内存:单机128GB;
3.版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
4.数据:800MB,8GB,8TB;
5.算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
6.迭代:K=10,3组数据
迭代次数(纵坐标是秒,横坐标是次数)
Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
2. Flink简介
很多人可能都是在 2015 年才听到 Flink 这个词,其实早在 2008 年,Flink 的前身已经是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。Flink 的最新版本目前已经更新到了 0.10.0 了,在很多人感慨 Spark 的快速发展的同时,或许我们也该为 Flink 的发展速度点个赞。
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。
Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似与 Storm。如果之前了解过 Storm 或者 Flume 的读者,可能会更容易理解 Flink 的架构和很多概念。下面让我们先来看下 Flink 的架构图。
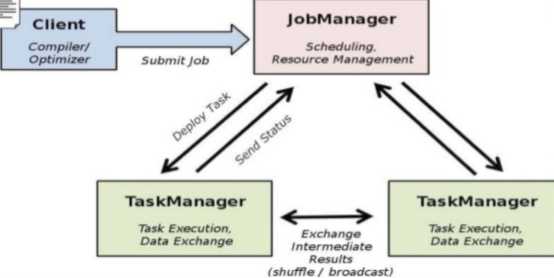
我们可以了解到 Flink 几个最基础的概念,Client、JobManager 和 TaskManager。Client 用来提交任务给 JobManager,JobManager 分发任务给 TaskManager 去执行,然后 TaskManager 会心跳的汇报任务状态。看到这里,有的人应该已经有种回到 Hadoop 一代的错觉。确实,从架构图去看,JobManager 很像当年的 JobTracker,TaskManager 也很像当年的 TaskTracker。然而有一个最重要的区别就是 TaskManager 之间是是流(Stream)。其次,Hadoop 一代中,只有 Map 和 Reduce 之间的 Shuffle,而对 Flink 而言,可能是很多级,并且在 TaskManager 内部和 TaskManager 之间都会有数据传递,而不像 Hadoop,是固定的 Map 到 Reduce。
3. 技术的特点(可选)
关于Flink所支持的特性,我这里只是通过分类的方式简单做一下梳理,涉及到具体的一些概念及其原理会在后面的部分做详细说明。
3.1. 流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
3.2. API支持
对Streaming数据类应用,提供DataStream API
对批处理类应用,提供DataSet API(支持Java/Scala)
3.3. Libraries支持
支持机器学习(FlinkML)
支持图分析(Gelly)
支持关系数据处理(Table)
支持复杂事件处理(CEP)
3.4. 整合支持
支持Flink on YARN
支持HDFS
支持来自Kafka的输入数据
支持Apache HBase
支持Hadoop程序
支持Tachyon
支持ElasticSearch
支持RabbitMQ
支持Apache Storm
支持S3
支持XtreemFS
3.5. Flink生态圈
一个计算框架要有长远的发展,必须打造一个完整的 Stack。不然就跟纸上谈兵一样,没有任何意义。只有上层有了具体的应用,并能很好的发挥计算框架本身的优势,那么这个计算框架才能吸引更多的资源,才会更快的进步。所以 Flink 也在努力构建自己的 Stack。
Flink 首先支持了 Scala 和 Java 的 API,Python 也正在测试中。Flink 通过 Gelly 支持了图操作,还有机器学习的 FlinkML。Table 是一种接口化的 SQL 支持,也就是 API 支持,而不是文本化的 SQL 解析和执行。对于完整的 Stack 我们可以参考下图。
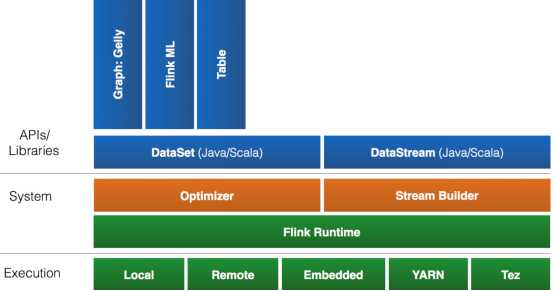
Flink 为了更广泛的支持大数据的生态圈,其下也实现了很多 Connector 的子项目。最熟悉的,当然就是与 Hadoop HDFS 集成。其次,Flink 也宣布支持了 Tachyon、S3 以及 MapRFS。不过对于 Tachyon 以及 S3 的支持,都是通过 Hadoop HDFS 这层包装实现的,也就是说要使用 Tachyon 和 S3,就必须有 Hadoop,而且要更改 Hadoop 的配置(core-site.xml)。如果浏览 Flink 的代码目录,我们就会看到更多 Connector 项目,例如 Flume 和 Kafka。
以上是关于Flink编程入门的主要内容,如果未能解决你的问题,请参考以下文章
Flink系列文档-(YY02)-Flink编程基础-入门示例