大数据——Flink 入门程序(wordcount)
Posted Vicky_Tang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据——Flink 入门程序(wordcount)相关的知识,希望对你有一定的参考价值。
目录
一、编程模型
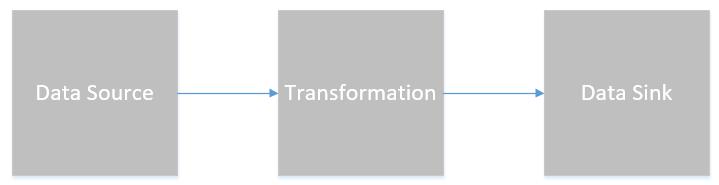
Flink提供了不同级别的编程抽象,通过调用抽象的数据集调用算子构建DataFlow就可以实现对分布式的数据进行流式计算和离线计算,DataSet是批处理的抽象数据集,DataStream是流式计算的抽象数据集,他们的方法都分别为Source、Transformation、Sink
- Source主要负责数据的读取
- Transformation主要负责对数据的转换操作
- Sink负责最终计算好的结果数据输出。
二、编程步骤
- 创建执行环境 Environment
- 加载数据源 Source
- 转换数据 Transformation
- 数据输出
- 执行程序
三、DataStream 实时 wordcount
3.1 本地执行
package cn.kgc.datasteam
//创建完执行环境后,将StreamExcutionEnvironment替换成_
import org.apache.flink.streaming.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度为2,默认为本地core核数
env.setParallelism(2)
//读取数据 source
//通过侦听hadoop101的1234端口采集数据
val inputStream = env.socketTextStream("hadoop101", 1234)
//转换数据 transformation
//将接收到的内容按空格拆分后展平
val result = inputStream.flatMap(_.split(" "))
.map((_, 1))
//根据单词分组聚合
.keyBy(_._1)
.sum(1)
//结果输出
result.print()
//执行程序
env.execute()
}
}
3.2上传至虚拟机执行代码
package cn.kgc.datasteam
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
object WordCountRunOnVM {
def main(args: Array[String]): Unit = {
//创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//通过参数的方式传入host主机名和port端口号
val tool = ParameterTool.fromArgs(args)
val host = tool.get("host")
val port = tool.getInt("port")
//读取数据源
val inputStream = env.socketTextStream(host, port)
//转换数据
val result = inputStream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(_._1)
.sum(1)
//结果输出
result.print()
//执行程序
env.execute()
}
}操作步骤
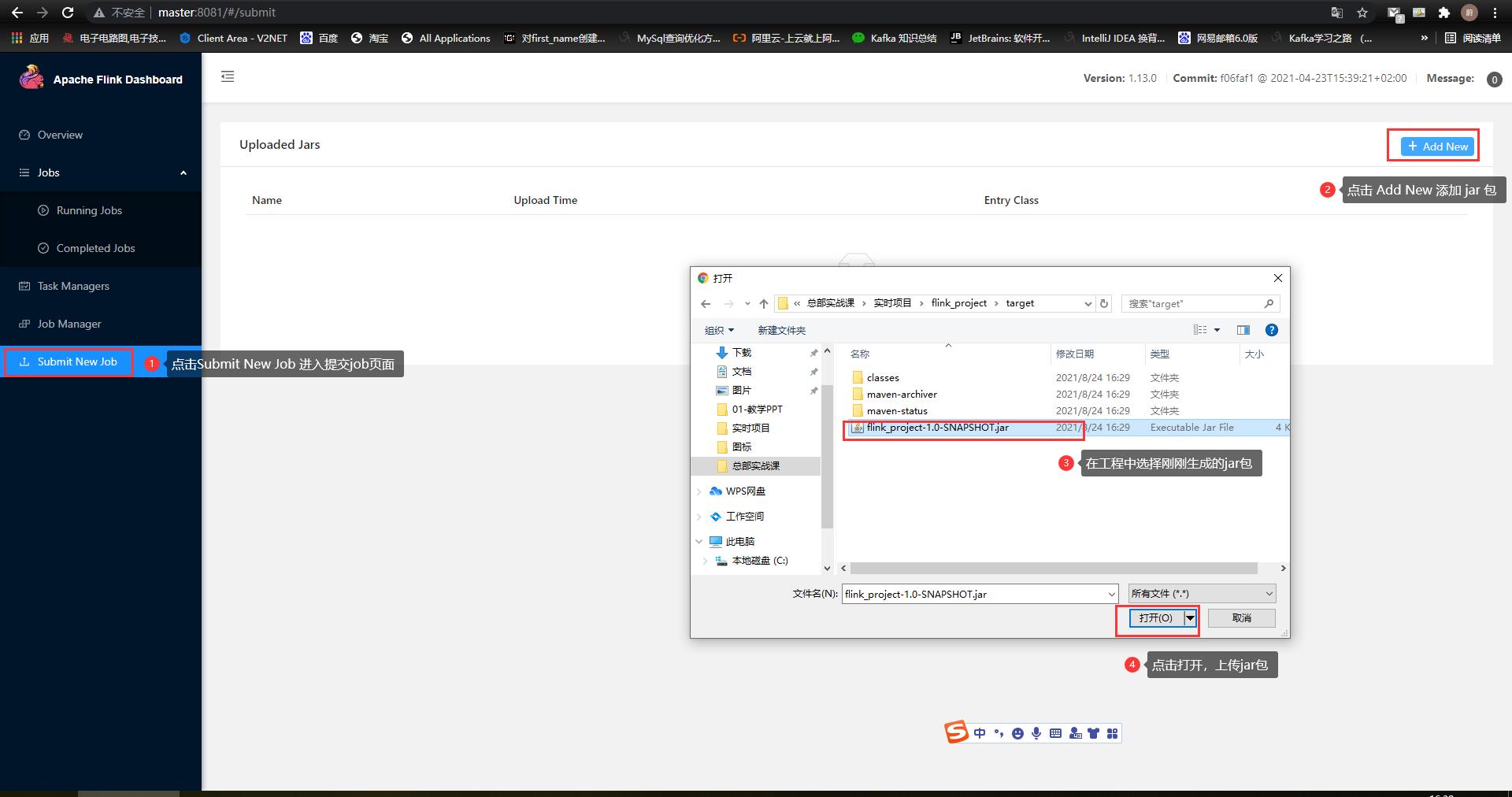
1. 生成 jar 包

2. 在虚拟机中启动start-cluser.sh服务
start-cluster.sh3. 开启1234端口侦听
nc -lk 12344. 登录master:8081页面,上传 jar 包


 四、DataSet 离线wordcount
四、DataSet 离线wordcount
package cn.kgc.dataset
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//DataSet批处理创建环境的方式 : ExecutionEnvironment.gerExecutionEnvironment
val env = ExecutionEnvironment.getExecutionEnvironment
//获取数据源
val input = env.readTextFile("C:/Users/Administrator/Desktop/flink_project/src/main/resources/wc.txt",
"UTF-8")
//转换数据
val result = input.flatMap(_.split(" "))
.map((_, 1))
//根据单词分组聚合
.groupBy(0)
.sum(1)
//结果输出
result.print()
}
}
以上是关于大数据——Flink 入门程序(wordcount)的主要内容,如果未能解决你的问题,请参考以下文章