Flink系列文档-(YY02)-Flink编程基础-入门示例
Posted 大摇不摆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink系列文档-(YY02)-Flink编程基础-入门示例相关的知识,希望对你有一定的参考价值。
1 环境准备-创建项目引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>
如需使用scala API,则替换上面的: flink-java 为 flink-scala_2.12 flink-streaming-java_2.12 为 flink-streaming-scala_2.12
2 flink的DataStream抽象
- DataStream代表一个数据流,它可以是无界的,也可以是有界的;
- DataStream类似于spark的rdd,它是不可变的(immutable);
- 无法对一个datastream进行自由的添加或删除或修改元素;
- 只能通过算子对datastream中的数据进行转换,将一个datastream转成另一个datastream;
- datastream可以通过source算子加载、映射外部数据而来;或者从已存在的datastream转换而来
3 flink编程模板
YY-无论简单与复杂,flink程序都由如下几个部分组成
- 获取一个编程、执行入口环境env
- 通过数据源组件,加载、创建datastream
- 对datastream调用各种处理算子表达计算逻辑
- 通过sink算子指定计算结果的输出方式
- 在env上触发程序提交运行
4 WordCount代码示例
YY01--批处理示例
package cn.doitedu.base01;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
/**
* @Date: 22.11.07
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description: 批处理 统计文件中单词出现的次数
*/
public class Base01_BatchWordCount
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8081);
// 流式处理数据的环境对象
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
// 获取批处理的环境对象
ExecutionEnvironment batchEnv = ExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
DataSource<String> ds = batchEnv.readTextFile("data/a.txt");
/**
* 泛型1 输入数据类型 String
* 泛型2 返回数据类型 Tuple2<String, Integer>
*/
ds.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>()
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
String[] words = value.split("\\\\s+");
for (String word : words)
out.collect(Tuple2.of(word, 1));
)
.groupBy(0)
.sum(1)
.print();
使用Lamda表达式编写成 ,凡是单方法的接口都可以使用Lamda表达式书写, 但是数据Java中的要指定返回的数据类型 !
FlatMapOperator<String, Tuple2<String, Integer>> ds2 = ds.flatMap((String line, Collector<Tuple2<String, Integer>> collector) ->
String[] words = line.split("\\\\s+");
for (String word : words)
collector.collect(Tuple2.of(word, 1));
)
.returns(Types.TUPLE(Types.STRING, Types.INT));// 指定数据类型
// 方法有返回值 ,指定返回值的类型
// .returns(new TypeHint<Tuple2<String, Integer>>() ) // 类型提示
// 这种是最通用的方法
// .returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() )) // 类型信息
ds2.groupBy(tp -> tp.f0).sum(1).print();YY02-流处理示例
<测试时,需要用nc -lk 9999(linux)或者 nc -L -p 9999(windows)在本机开启一个9999的sockect服务>
/**
* @Date: 22.11.07
* @Author: Hang.Nian.YY
* @qq: 598196583
* @Tips: 学大数据 ,到多易教育
* @Description:
*/
public class Base03_StreamWordCount
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
// 设置本地的运行环境 . 且带webUI
conf.setInteger("rest.port" , 8081);
// 获取流式处理数据的对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
// 设置并行度 为1 默认并行度是本地机器的cpu的核数
env.setParallelism(1) ;
SingleOutputStreamOperator<String> source = env.socketTextStream("doitedu01", 8899)
;// .setParallelism(1).slotSharingGroup("g1");// 同一个槽位共享组
// 使用算子对数据进行各种转换操作
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = source.flatMap(
// 传入转换算子函数对象
new FlatMapFunction<String, Tuple2<String, Integer>>()
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
// 处理每行数据 , 切割出单词
String[] words = value.split("\\\\s+");
for (String word : words)
// 将单词组装成 元组 收集记录数据 并转发返回
out.collect(Tuple2.of(word, 1));
);
// 将数据按照单词分组
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, String>()
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception
return value.f0;
);
keyed.sum("f1").print();
env.execute() ;
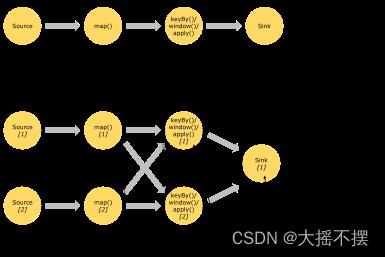
5 flink程序的并行概念
- flink程序中,每一个算子都可以成为一个独立任务(task);
- flink程序中,视上下游算子间数据分发规则、并行度、共享槽位设置,可组成算子链成为一个task
- 每个任务在运行时都可拥有多个并行的运行实例(subTask);
- 且每个算子任务的并行度都可以在代码中显式设置;
以上是关于Flink系列文档-(YY02)-Flink编程基础-入门示例的主要内容,如果未能解决你的问题,请参考以下文章