《大数据》MapReduce练习
Posted Steve_Abelieve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《大数据》MapReduce练习相关的知识,希望对你有一定的参考价值。
思考问题
1.统计出IP的文件,哪个ip出现的次数最多,一行一个ip。如果文件很大,超过内存。
2.给定a、b两个文件,各存放50亿个url,每个url各占64B,内存限制是4GB,请找出a、b两个文件共同的url?
3.现在有一个非常庞大的URL库(100E),然后现在还有一个URL,(迅速)判断这个URL是否在这个URL库中?
MapReduce
MapReduce是一个处理海量数据计算的框架
MapReduce框架解决了什么问题
1.内部的任务调度
2.高可用,HA
3.节点间的通信问题
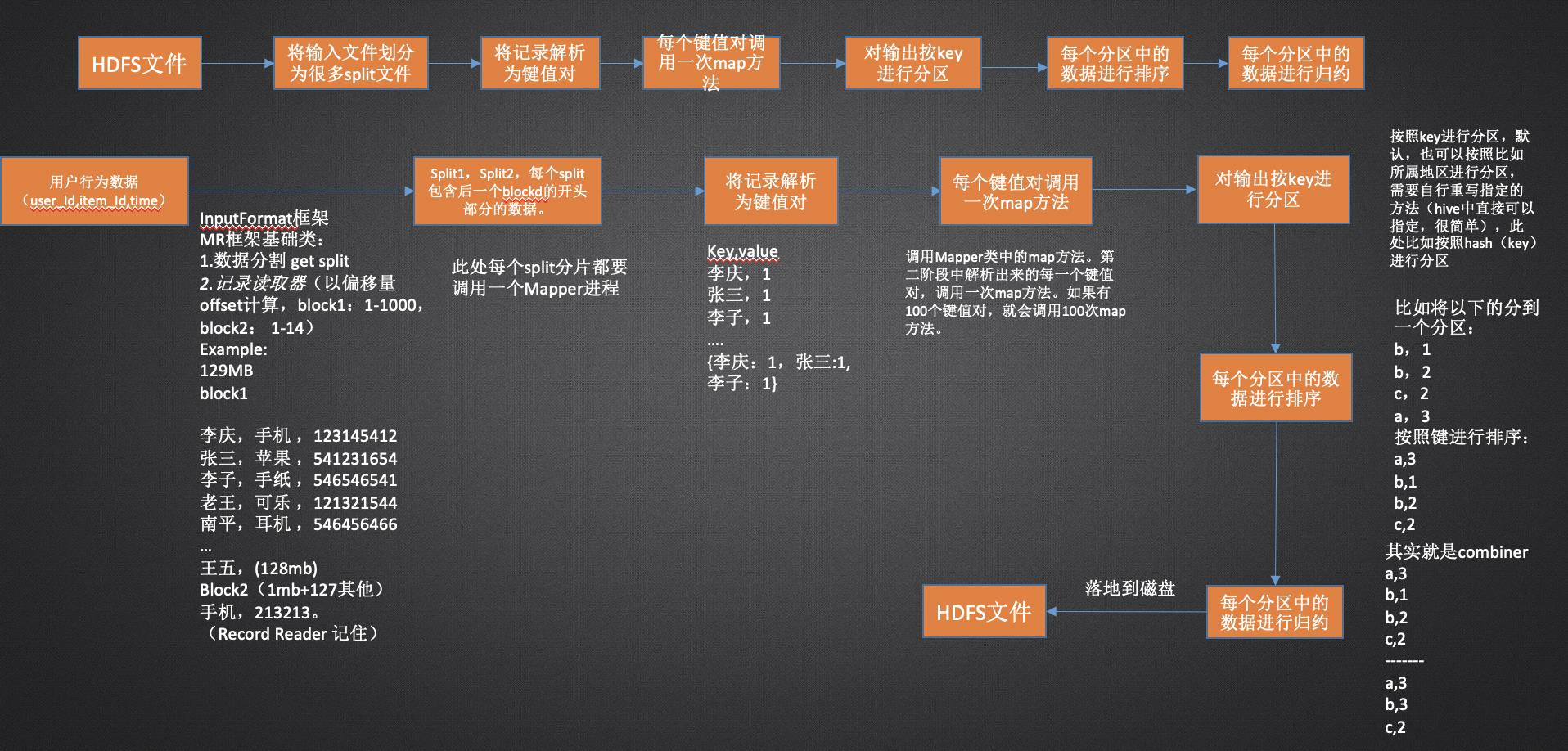
MapReduce原理
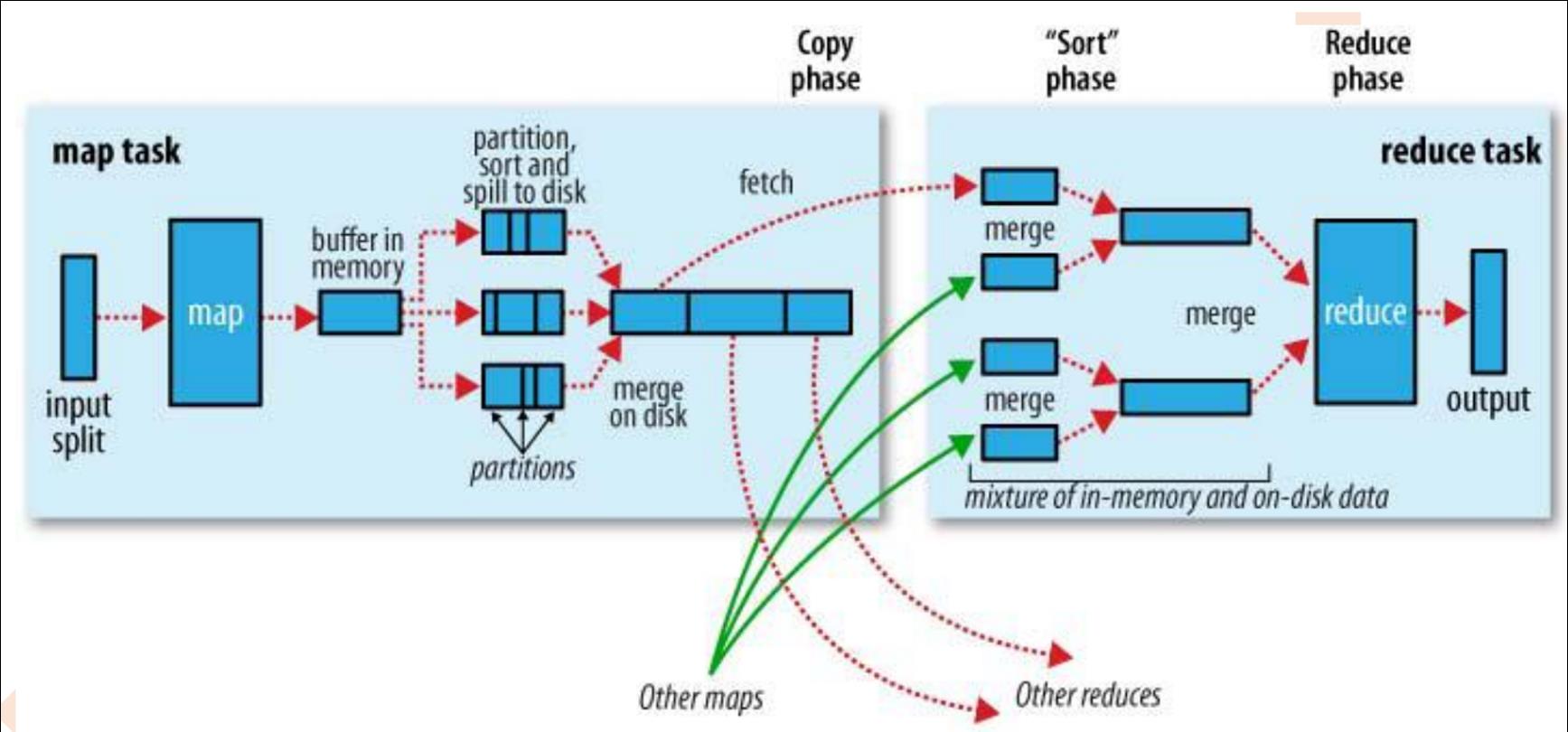
过程说明:
Mapper 任务过程详解
Reducer 任务过程详解

Commbinner 过程
Hadoop允许用户针对map 任务的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。特别值得注意的一点,一个combiner只是处理一个结点中的的输出,而不能享受像reduce一样的输入(经过了shuffle阶段的数据)
不适合的场景:
平均值计算
Shuffle过程

Hadoop Streaming
MR整个采取的JAVA实现的,提供java接口。
Streaming使得跨语言也可以进行MR的编写。
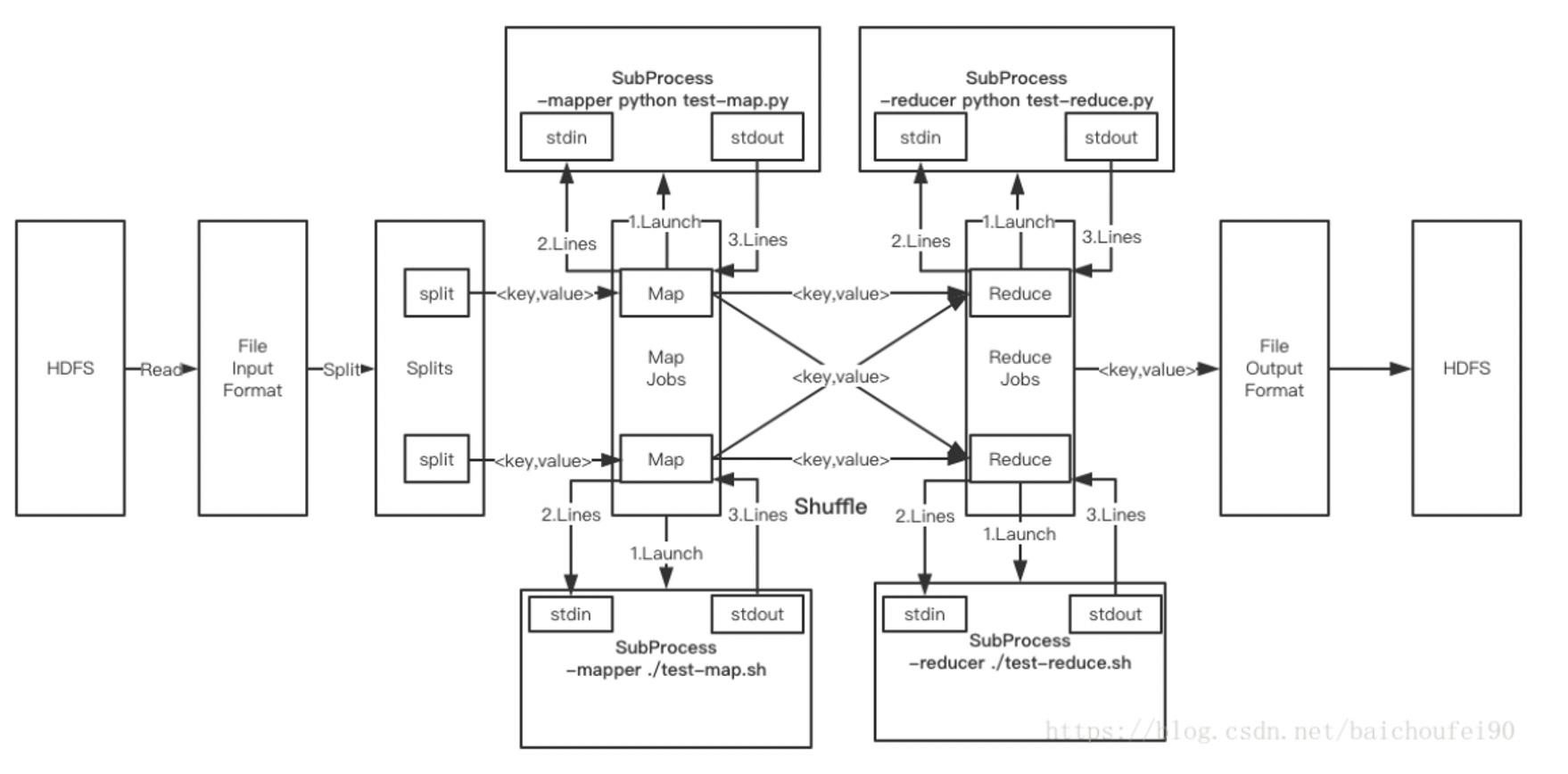
MapReduce 实战
reduce过程的百分比与对应的处理如下:
- 0~33%是shuffle的过程,数据从mapper已到了reducer
- 33~67%是sort的过程,这个过程只会在mapper完成后才会执行
- 67~100%才是reducer程序执行的过程。如果reduce卡在了67%,那么说明reducer一个也没有执行。可能是输入数据太大,超过了限制,也可能是reducer有死循环的bug。
常用命令

查看节点信息:
http://192.168.77.10:50070
以上是关于《大数据》MapReduce练习的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:Hadoop 大数据集成 (Hadoop => Elasticsearch)
Elasticsearch:Hadoop 大数据集成 (Hadoop => Elasticsearch)