Elasticsearch:Hadoop 大数据集成 (Hadoop => Elasticsearch)
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Hadoop 大数据集成 (Hadoop => Elasticsearch)相关的知识,希望对你有一定的参考价值。
在本文章中,我们将学习如何使用 Elasticsearch Hadoop 处理大量数据。 对于我们的练习,我们将使用一个简单的 Apache access 日志来表示我们的 “大数据”。 我们将学习如何编写 MapReduce 作业以使用 Hadoop 摄取文件并将其索引到 Elasticsearch 中。在我们今天的练习中,我们将使用如下的架构来搭建我们的系统:

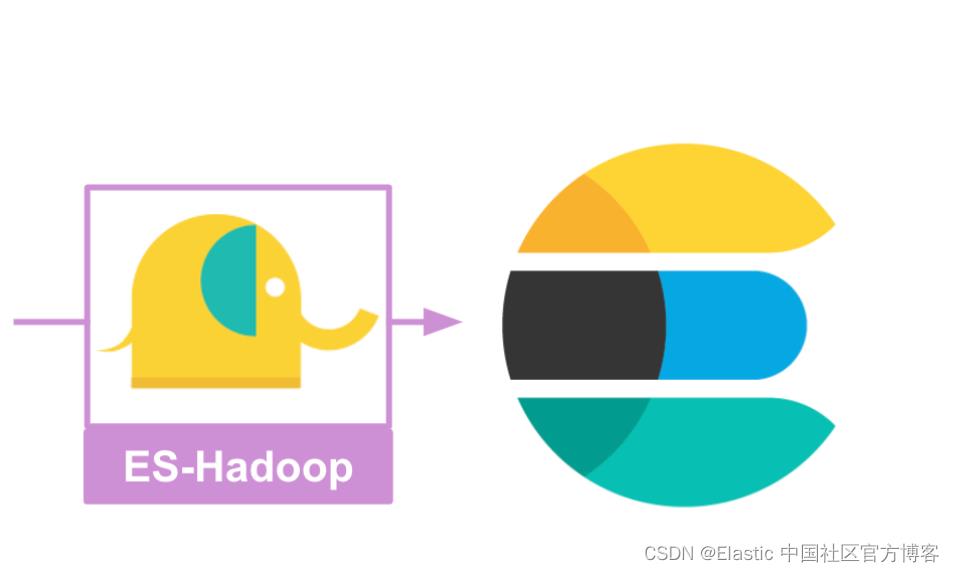
如上所示,我们在左边的 macOS 中安装 Elasticsearch 及 Kibana,而在 Ubuntu OS 中安装 Hadoop。我们将以最新的 Elastic Stack 8.4.2 来进行展示。
Hadoop 是什么?
当我们需要收集、处理/转换和/或存储数千 GB、数千 TB 甚至更多的数据时,Hadoop 可能是完成这项工作的合适工具。它是从头开始构建的,考虑到这样的想法:
- 一次使用多台计算机(形成一个集群),以便它可以并行处理数据,从而更快地完成工作。我们可以这样想。如果一台服务器需要处理 100 TB 的数据,它可能会在 500 小时内完成。但是如果我们有 100 台服务器,每台只能取一部分数据,例如 server1 可以取第一个 TB,server2 可以取第二个 TB,以此类推。现在他们每个人都只有 1 TB 的数据要处理,而且他们都可以同时处理自己的数据部分。这样,工作可以在 5 小时内完成,而不是 500 小时。当然,这是理论上的和想象的,因为在实践中我们不会减少 100 倍所需的时间,但我们可以非常接近如果条件理想。
- 在需要时可以很容易地调整计算能力。有更多的数据要处理,而问题要复杂得多?将更多计算机添加到集群。从某种意义上说,这就像在超级计算机上增加了更多的 CPU 内核。
- 数据不断增长,因此 Hadoop 也必须能够轻松灵活地扩展其存储容量,以满足需求。我们添加到集群的每台计算机都会扩展 Hadoop 分布式文件系统 (HDFS) 的可用总存储空间。
- 与其他软件不同,它不仅会在硬件故障发生时尝试从硬件故障中恢复。设计理念实际上假设某些硬件肯定会失败。当有数千台计算机并行工作时,可以保证某处某处会不时出现故障。因此,默认情况下,Hadoop 创建数据块的副本并将它们分布在单独的硬件上,因此当偶尔的服务器起火或硬盘或 SSD 死机时,不会丢失任何内容。
总而言之,Hadoop 非常擅长摄取和处理大量信息。它将数据分布在集群中可用的多个节点上,并使用 MapReduce 编程模型在多台机器上同时处理数据(并行处理)。
但这听起来可能有点类似于 Elasticsearch 数据摄取工具所做的事情。尽管它们是为处理相当不同的场景而设计的,但它们有时可能会有些重叠。那么我们为什么以及何时使用其中一个而不是另一个呢?
Hadoop vs Logstash/Elasticsearch
首先,我们不应该考虑哪个比哪个更好。 每个人都擅长为其创造的工作。 每个都有优点和缺点。
为了尝试给你绘制一个图片并让你了解我们何时使用其中一个,让我们考虑以下场景:
- 当我们需要从数十亿个网站中提取数据时,就像谷歌这样的搜索引擎所做的那样,我们会发现像 Elasticsearch 及 Hadoop 这样的工具非常有用和高效。
- 当我们需要以这样一种方式存储数据并对其进行索引以便以后可以快速有效地搜索时,我们会发现像 Elasticsearch 这样的东西非常有用。
- 最后,当我们想要收集实时数据时,例如来自互联网上许多交易所的美元/欧元价格,我们会发现像 Logstash 这样的工具非常适合这项工作。

MapReduce 是如何工作的?
如前所述,虽然像 Logstash 甚至 Spark 这样的工具更易于使用,但它们也将我们限制在它们使用的方法中。也就是说,我们只能微调他们允许我们调整的设置,我们不能改变他们的编程逻辑在幕后的工作方式。这通常不是问题,只要我们能做我们想做的事。
然而,使用 Hadoop,我们可以在低得多的级别上更好地控制事物的工作方式,从而允许更多的定制,更重要的是优化。当我们处理 PB 级数据时,优化非常重要。它可以帮助我们将工作所需的时间从几个月缩短到几周,并显着降低运营成本和所需资源。
让我们先来看看 MapReduce,它增加了我们工作的复杂性,但也允许前面提到的更高级别的控制。
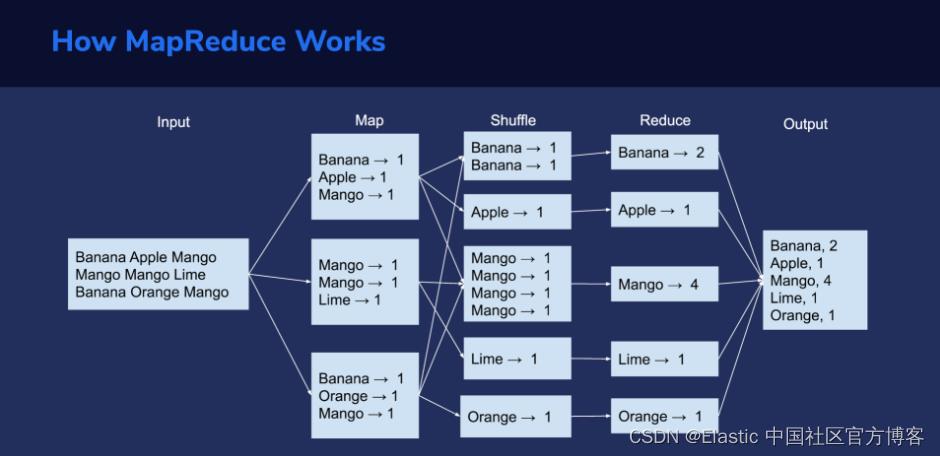
MapReduce 过程通常包括三个主要阶段:Map、Shuffle 和 Reduce。
最初,数据被分成更小的块,可以分布在不同的计算节点上。接下来,每个节点都可以对其接收到的数据块执行 map 任务。这种并行处理大大加快了进程。集群拥有的节点越多,工作完成的速度就越快。
以键/值(key/value)对的形式映射的数据现在位于不同的服务器上。所有具有相同键的值都需要组合在一起。这是 shuffle 阶段。接下来,shuffle 后的数据经过 reduce 阶段。
在上面的图片举例说明了这些阶段在三行单词的集合上的作用。
在这里,我们假设我们有一个简单的文本文件,我们需要计算每个单词出现的次数。
第一步是读取数据并将其拆分为可以有效发送到所有处理节点的块。在我们的例子中,我们假设文件被分成三行。
Map 阶段
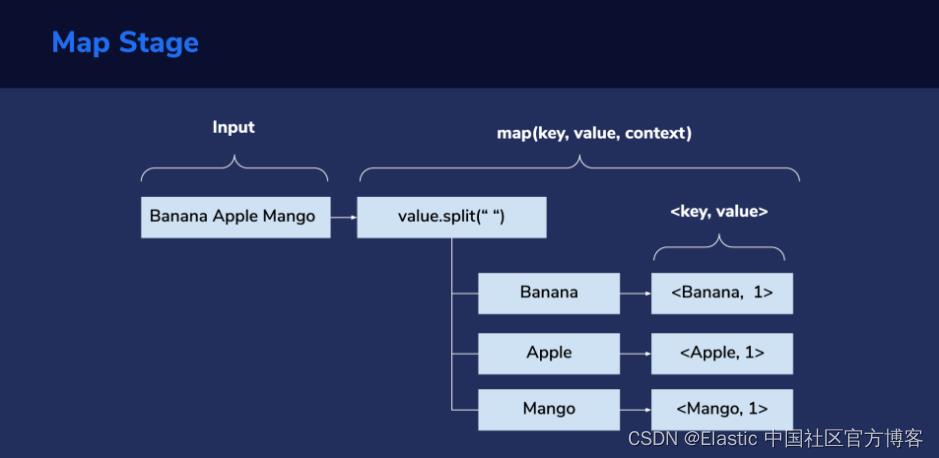
接下来是 Map 阶段。 每行文字被用作 map(key, value, context) 方法的输入。 这是我们必须编写所需的自定义逻辑的地方。 对于这个字数统计示例,“value” 参数将保存行输入(文件中的文本行)。 然后,我们将使用空格字符作为单词分隔符拆分行,然后遍历每个拆分(单词)并使用 context.write(key, value) 发出 map 输出。 在这里,我们的 key 是单词,例如 “Banana”,值是 1,表示它是单词的单次出现。 从上图中我们可以看到,第一行我们得到 <Banana, 1>, <Apple, 1>, <Mango, 1> 作为键/值(key/value)对。
Shuffle 阶段

Shuffle 阶段负责从 map 器中获取 <key, value> 对,并根据分区器(partitioner)决定每个去往哪个 reducer。
从显示每个阶段运行的图像中,我们可以看到我们最终在 reduce 阶段有五个分区。 Shuffle 是由框架在内部完成的,所以我们在这里不会有任何自定义代码。
Reduce 阶段
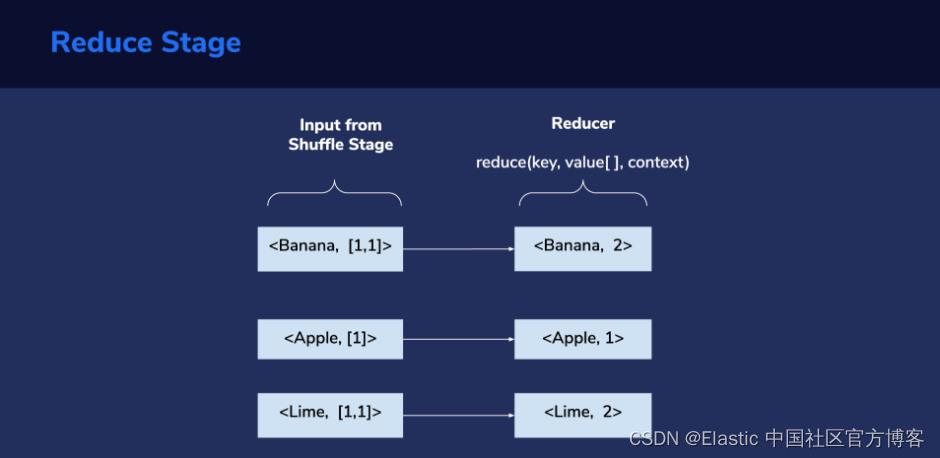
Shuffle 阶段的输出被馈送到 reduce 阶段:作为其输入,每个 reducer 接收在 shuffle 阶段形成的组之一。 这由一个键和与该键相关的值列表组成。 在这里,我们再次必须编写我们希望在此阶段执行的自定义逻辑。 在此示例中,对于每个键,我们必须计算其值列表中元素的总和。 这样,我们就得到了每个键的总计数,它最终代表了我们文本文件中每个唯一单词的计数。
Reduce 阶段的输出也遵循 <key, value> 格式。 如前所述,在此示例中,键将表示单词,值表示单词重复的次数。
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考我之前的文章来进行安装:
请注意:你需要选择 Elastic Stack 8.x 的安装指南。
Hadoop
我们需要在 Ubuntu OS 上安装 Hadoop。我们可以按照如下的步骤来进行安装。
安装 Java
我们可以安装最新版本的 Java:
sudo apt install default-jdk default-jre -y我们可以通过如下的命令来查看 Java 的版本:
java -version$ java -version
openjdk version "11.0.16" 2022-07-19
OpenJDK Runtime Environment (build 11.0.16+8-post-Ubuntu-0ubuntu122.04)
OpenJDK 64-Bit Server VM (build 11.0.16+8-post-Ubuntu-0ubuntu122.04, mixed mode)创建 Hadoop 用户及配置无需使用密码的 SSH 连接
添加一个新的用户 hadoop
sudo adduser hadoop$ sudo adduser hadoop
Adding user `hadoop' ...
Adding new group `hadoop' (1001) ...
Adding new user `hadoop' (1001) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
Sorry, passwords do not match.
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
添加 hadoop 用户到 sudo 组:
sudo usermod -aG sudo hadoop切换到 hadoop 用户:
sudo su - hadoop$ sudo su - hadoop
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.安装 OpenSSH 服务器及客户端:
sudo apt install openssh-server openssh-client -y如果你得到一个提示时,请回复:
keep the local version currently installed切换到 hadoop 用户:
sudo su - hadoop生成公钥和私钥对:
ssh-keygen -t rsa$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub
The key fingerprint is:
SHA256:tD9JRpv+c6KMlsevCMGJSLSdGPsDrqwl1yhFu51NIy8 hadoop@ubuntu2204
The key's randomart image is:
+---[RSA 3072]----+
| o |
| . * . |
| B o . . |
| + = o o o o |
| = = * S = |
|.o = B o = . |
|+.= E + o= |
|.= . .o+ooo . |
|. .o.++o+ |
+----[SHA256]-----+
在上面,我们可以把 passphrase 设置为空。将生成的公钥从 id_rsa.pub 添加到 authorized_keys:
sudo cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys$ sudo cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[sudo] password for hadoop: 更改 authorized_keys 文件的权限:
sudo chmod 640 ~/.ssh/authorized_keys验证无密码 SSH 是否正常工作:
ssh localhosthadoop@ubuntu2204:~$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ED25519 key fingerprint is SHA256:lN78YGD118UAp/ZmzrtWnrqicHaFkJbs5pIZfTH06b0.
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? y
Please type 'yes', 'no' or the fingerprint: yes
Warning: Permanently added 'localhost' (ED25519) to the list of known hosts.
Enter passphrase for key '/home/hadoop/.ssh/id_rsa':
Welcome to Ubuntu 22.04.1 LTS (GNU/Linux 5.15.0-48-generic aarch64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
0 updates can be applied immediately.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
hadoop@ubuntu2204:~$ 安装 Hadoop
首先我们使用 hadoop 用户登录:
sudo su - hadoop下载最新的稳定版 Hadoop。 要获取最新版本,请访问 Apache Hadoop 官方下载页面。
wget https://downloads.apache.org/hadoop/common/stable/hadoop-3.3.4.tar.gz解压缩下载的文件:
tar -xvzf hadoop-3.3.4.tar.gz将解压后的目录移动到 /usr/local/ 目录
sudo mv hadoop-3.3.4 /usr/local/hadoophadoop@ubuntu2204:~$ pwd
/home/hadoop
hadoop@ubuntu2204:~$ ls
hadoop-3.3.4 hadoop-3.3.4.tar.gz
hadoop@ubuntu2204:~$ sudo mv hadoop-3.3.4 /usr/local/hadoop
[sudo] password for hadoop:
创建目录来存储系统日志:
sudo mkdir /usr/local/hadoop/logs更改 hadoop 目录的所有权:
sudo chown -R hadoop:hadoop /usr/local/hadoop配置 Hadoop
我们还是在 hadoop 用户下,编辑文件 ~/.bashrc 以配置 Hadoop 环境变量:
sudo nano ~/.bashrc激活环境变量:
source ~/.bashrc配置 Java 环境变量
Hadoop 有许多组件使其能够执行其核心功能。 要配置YARN、HDFS、MapReduce 等这些组件,以及 Hadoop 相关的项目设置,需要在 hadoop-env.sh 配置文件中定义 Java 环境变量。
找到 Java 路径:
$ which javac$ which javac
/usr/bin/javac找到 OpenJDK 目录:
$ readlink -f /usr/bin/javac$ readlink -f /usr/bin/javac
/usr/lib/jvm/java-11-openjdk-arm64/bin/javac我们也可以直接使用一个命令来完成上面的两个操作:
readlink -f $(which javac)编辑 hadoop-env.sh 文件:
$ sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh将以下行添加到文件中。 然后,关闭并保存文件:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"浏览到 hadoop lib 目录:
$ cd /usr/local/hadoop/lib下载 Javax 激活文件:
$ sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar验证 Hadoop 版本:
$ hadoop version$ hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:32Z
Compiled with protoc 3.7.1
From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.4.jar至此,我们完成了 hadoop 的安装。我们不再需要针对 NameNode 等进行配置了。
创建 MapReduce 项目
在本练习中,我们将索引以 Apache 组合日志格式生成的示例访问日志文件。我们将使用 maven 构建工具将我们的 MapReduce 代码编译成 JAR 文件。
在实际场景中,你必须执行一些额外的步骤:
- 安装包含代码编辑器(如 Eclipse)的集成开发环境 (IDE),以创建项目并编写必要的代码。
- 在本地桌面上使用 maven 编译项目。
- 将已编译的项目 (JAR) 从本地桌面传输到你的 Hadoop 实例。
我们将解释如何创建这样一个项目背后的理论,但我们还将提供一个 GitHub 存储库,其中包含一个现成的简单 Java 项目。这样,你现在不必浪费时间编写代码,而可以立即开始试验并查看 MapReduce 的运行情况。此外,如果你不熟悉 Java 编程,你可以查看示例代码以更好地了解所有部分的位置以及它们的适用性。
所以,首先,让我们看一下理论,看看我们将如何构建 MapReduce 代码,以及它背后的逻辑是什么。
为了说明问题的方便,你可以下载代码 https://github.com/liu-xiao-guo/elasticsearch-hadoop。
设置 pom.xml 依赖项
要开始,我们首先必须使用我们喜欢的代码编辑器创建一个空的 Maven 项目。 Eclipse 和 IntelliJ 都有内置模板来执行此操作。 我们可以在创建 maven 项目时跳过原型选择; 我们只需要一个空的 Maven 项目。
创建项目后,我们将编辑 pom.xml 文件并使用以下属性和依赖项。 将来使用新的稳定版本的 Hadoop 和 Elasticsearch 时,可能需要更改下面指定的某些版本号。
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.liuxg</groupId>
<artifactId>elasticsearchhadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>8.4.2</version>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<manifestEntries>
<Main-Class>com.liuxg.AccessLogIndexIngestion</Main-Class>
<Build-Number>123</Build-Number>
</manifestEntries>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>在上面,我们使用了最新的 Elastic Stack 8.4.2 版本。我们可以获得 Maven 的相关信息在地址: https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch-hadoop/8.4.2

如上所示,我们也选择了相应的 hadoop 版本信息。这个在我们上面的 hadoop 的安装中可以看到版本信息。
$ hadoop version
Hadoop 3.3.4
Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb
Compiled by stevel on 2022-07-29T12:32Z
Compiled with protoc 3.7.1
From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.4.jar编写 MapReduce 作业需要 hadoop-client 库。 为了写入 Elasticsearch 索引,我们使用了官方的 elasticsearch-hadoop 库。 commons-httpclient 也是需要的,因为 elasticsearch-hadoop-使用它能够通过 HTTP 协议对 Elasticsearch 服务器进行 REST 调用。
定义 Mapper 类的逻辑
我们将定义 AccessLogMapper 并将其用作我们的 mapper 类。 在其中,我们将覆盖默认的 map() 方法并定义我们想要使用的编程逻辑。
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class AccessLogIndexIngestion
public static class AccessLogMapper extends Mapper
@Override
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException
public static void main(String[] args)
如前所述,在这个例子中我们不需要 reducer 类。
为 Hadoop 定义 Elasticsearch 索引
这是日志文件的示例:
77.0.42.68 - - [17/May/2015:23:05:48 +0000] "GET /favicon.ico HTTP/1.1" 200 3638 "-" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:27.0) Gecko/20100101 Firefox/27.0"
77.0.42.68 - - [17/May/2015:23:05:32 +0000] "GET /images/jordan-80.png HTTP/1.1" 200 6146 "http://www.semicomplete.com/projects/xdotool/" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:27.0) Gecko/20100101 Firefox/27.0"
77.0.42.68 - - [18/May/2015:00:05:08 +0000] "GET /images/web/2009/banner.png HTTP/1.1" 200 52315 "http://www.semicomplete.com/style2.css" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:27.0) Gecko/20100101 Firefox/27.0"
207.241.237.101 - - [18/May/2015:00:05:42 +0000] "GET /blog/geekery/find-that-lost-screen-session.html HTTP/1.0" 200 11214 "http://www.semicomplete.com/blog/tags/tools" "Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot)"
120.202.255.147 - - [18/May/2015:00:05:57 +0000] "GET /files/logstash/logstash-1.1.0-monolithic.jar HTTP/1.1" 304 - "-" "Mozilla/5.0 Gecko/20100115 Firefox/3.6"
207.241.237.104 - - [18/May/2015:00:05:43 +0000] "GET /geekery/find-that-lost-screen-session-2.html HTTP/1.0" 404 328 "http://www.semicomplete.com/blog/tags/tools" "Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot)"为了简化问题,我在 github 的仓库中已经包含了一个叫做 access.log 的文件。它含有上面的 6 个文档。到目前为止,我们只处理了理论,但在这里,重要的是我们执行下一个命令。
curl -k -u elastic:H8_aSaFv0G*muE-Hrmp0 -XPUT "https://10.211.55.2:9200/mylogs" -H "kbn-xsrf: reporting" -H "Content-Type: application/json" -d'
"mappings":
"properties":
"ip":
"type": "keyword"
,
"dateTime":
"type": "date",
"format": ["dd/MMM/yyyy:HH:mm:ss"]
,
"httpStatus":
"type": "keyword"
,
"url":
"type": "keyword"
,
"responseCode":
"type": "keyword"
,
"size":
"type": "integer"
'我们在运行 Elasticsearch 的机器中的 terminal 中执行上面的命令。请注意在上面,由于我们使用了 HTTPS 的安装,我们必须使用 -k 选项,或者我们添加证书信息。我们需要根据自己的配置替换上面的 elastic 超级用户的密码。我们也可以在 Kibana 中直接打入如下的命令:
PUT mylogs
"mappings":
"properties":
"ip":
"type": "keyword"
,
"dateTime":
"type": "date",
"format": ["dd/MMM/yyyy:HH:mm:ss"]
,
"httpStatus":
"type": "keyword"
,
"url":
"type": "keyword"
,
"responseCode":
"type": "keyword"
,
"size":
"type": "integer"
上面的命令将生成一个叫做 mylogs 的索引。
将 dateTime 字段定义为日期至关重要,因为它使我们能够使用 Kibana 可视化各种指标。 当然,我们还需要指定访问日志中使用的日期/时间格式“dd/MMM/yyyy:HH:mm:ss”,以便正确解析传递给 Elasticsearch 的值。
定义 map() 逻辑
由于我们的输入数据是一个文本文件,我们使用 TextInputFormat.class。 日志文件的每一行都将作为输入传递给 map() 方法。最后,我们可以定义程序的核心逻辑:在 EsOutputFormat.class 的帮助下,我们希望如何处理每一行文本并准备好将其发送到 Elasticsearch 索引。
map() 方法的 value 输入参数保存当前从日志文件中提取并准备处理的文本行。 我们可以忽略这个简单示例的关键参数。
import org.elasticsearch.hadoop.util.WritableUtils;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
import java.util.LinkedHashMap;
import java.util.Map;
@Override
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException
String logEntry = value.toString();
// Split on space
String[] parts = logEntry.split(" ");
Map<String, String> entry = new LinkedHashMap<>();
// Combined LogFormat "%h %l %u %t \\"%r\\" %>s %b \\"%Refereri\\" \\"%User-agenti\\"" combined
entry.put("ip", parts[0]);
// Cleanup dateTime String
entry.put("dateTime", parts[3].replace("[", ""));
// Cleanup extra quote from HTTP Status
entry.put("httpStatus", parts[5].replace("\\"", ""));
entry.put("url", parts[6]);
entry.put("responseCode", parts[8]);
// Set size to 0 if not present
entry.put("size", parts[9].replace("-", "0"));
context.write(NullWritable.get(), WritableUtils.toWritable(entry));
我们使用空格字符作为分隔符将行拆分为单独的部分。 由于我们知道日志文件中的第一列表示一个 IP 地址,因此我们知道 parts[0] 保存了这样一个地址,因此我们可以准备将该部分作为 IP 字段发送到 Elasticsearch。 同样,我们可以从日志中发送其余的列,但其中一些需要事先进行特殊处理。 例如,当我们使用空格字符作为分隔符拆分输入字符串时,时间字段被拆分为两个条目,因为它包含秒数和时区之间的空格(在我们的日志中为 +0000)。 出于这个原因,我们需要重新组装时间戳并将第 3 部分和第 4 部分连接起来。
EsOutputFormat.class 忽略 Mapper 类输出的 “key”,因此在 context.write() 我们将键设置为 NullWriteable.get()
MapReduce 作业配置
我们需要告诉我们的程序它可以在哪里到达 Elasticsearch 以及要写入哪个索引。 我们使用 conf.set(“es.nodes”, “localhost:9200”); 和 conf.set(“es.resource”, “mylogs”);。由于在 Elastic Stack 8.x 中,HTTPS 是标准的配置,我们需要对访问 Elasticsearch 做一下特殊的配置。具体可以访问文档 Configuration | Elasticsearch for Apache Hadoop [8.4] | Elastic。
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
Configuration conf = new Configuration();
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
conf.setBoolean("es.net.ssl.cert.allow.self.signed", true);
conf.setBoolean("es.net.ssl", true);
conf.setStrings("es.net.ssl.protocol", "TLS");
conf.setStrings("es.net.ssl.truststore.location", "file:///home/hadoop/hadoop/truststore.p12");
conf.setStrings("es.net.ssl.truststore.pass", "password");
conf.setStrings("es.net.http.auth.user", "elastic");
conf.setStrings("es.net.http.auth.pass", "H8_aSaFv0G*muE-Hrmp0");
conf.set("es.nodes", "https://10.211.55.2:9200");
conf.set("es.resource", "mylogs");
Job job = Job.getInstance(conf);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(EsOutputFormat.class);
job.setMapperClass(AccessLogMapper.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(args[0]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
我们需要根据自己的配置修改上面的 elastic 超级用户的密码。在上面的配置中,我们使用了一个叫做 trusstore.p12 的 truststore 证书,而它的密码是 password。如果你不知道如何得到这个证书,你可以阅读我之前的文章 “Elasticsearch:在 Java 客户端中使用 truststore 来创建 HTTPS 连接”。我们首先进行到 Elasticsearch 的安装目录的如下子目录:
$ pwd
/Users/liuxg/test/elasticsearch-8.4.2/config/certs
$ ls
http.p12 http_ca.crt transport.p12
$ keytool -import -file http_ca.crt -keystore truststore.p12 -storepass password -noprompt -storetype pkcs12
Certificate was added to keystore
$ ls
http.p12 http_ca.crt transport.p12 truststore.p12上面的命令将生成一个叫做 truststore.p12 的证书。我们把这个证书拷贝到 Ubuntu OS 机器的一个目录中,比如 /home/hadoop/hadoop。
在正常情况下,Hadoop 中的推测执行有时可以优化作业。 但是,在这种情况下,由于输出被发送到 Elasticsearch,它可能会意外地导致重复条目或其他问题。 这就是为什么建议在这种情况下禁用推测执行。 你可以在此处阅读有关此内容的更多信息:Runtime options | Elasticsearch for Apache Hadoop [8.4] | Elastic
这些行禁用该功能:
conf.setBoolean(“mapred.map.tasks.speculative.execution”, false);
conf.setBoolean(“mapred.reduce.tasks.speculative.execution”, false);由于在这种情况下 MapReduce 作业本质上将读取文本文件,因此我们使用 TextInputFormat 类作为输入:job.setInputFormatClass(TextInputFormat.class); 而且,由于我们要写入 Elasticsearch 索引,因此我们使用 EsOutputFormat 类作为输出:job.setOutputFormatClass(EsOutputFormat.class); 接下来,我们将要使用的 Mapper 类设置为我们在本练习中创建的类:job.setMapperClass(AccessLogMapper.class);最后,由于我们不需要 reducer,我们将 reduce 任务的数量设置为零:job.setNumReduceTasks(0)。
构建 JAR 文件
一旦所有代码都到位,我们必须构建一个可执行的 JAR。 我们在项目的根目录下打入如下的命令:
$ mvn clean install
我们会看到很多输出和文件被拉入,当这个过程完成时,我们应该看到 “BUILD SUCCESS” 消息。
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 16.227 s
[INFO] Finished at: 2022-10-08T14:35:00+08:00
[INFO] ------------------------------------------------------------------------我们可以在当前的目录下面的 target 子目录下看到一个 jar 文件:
$ ls ./target/*.jar
./target/elasticsearchhadoop-1.0-SNAPSHOT.jar
./target/original-elasticsearchhadoop-1.0-SNAPSHOT.jar我们把上面的 elasticsearchhadoop-1.0-SNAPSHOT.jar 拷贝到 Ubuntu OS 的一个目录中,比如 /home/hadoop/hadoop。
运行 MapReduce 作业
在上面,我们把 access.log,truststore.p12 文件 及 elasticsearchhadoop-1.0-SNAPSHOT.jar 拷贝到 Ubuntu OS 机器上,并保存于一个目录 /home/hadoop/hadoop 中:
hadoop@ubuntu2204:~/hadoop$ pwd
/home/hadoop/hadoop
hadoop@ubuntu2204:~/hadoop$ ls
access.log elasticsearchhadoop-1.0-SNAPSHOT.jar truststore.p12我们接下来使用如下的命令来运行这个作业:
hadoop jar elasticsearchhadoop-1.0-SNAPSHOT.jar access.log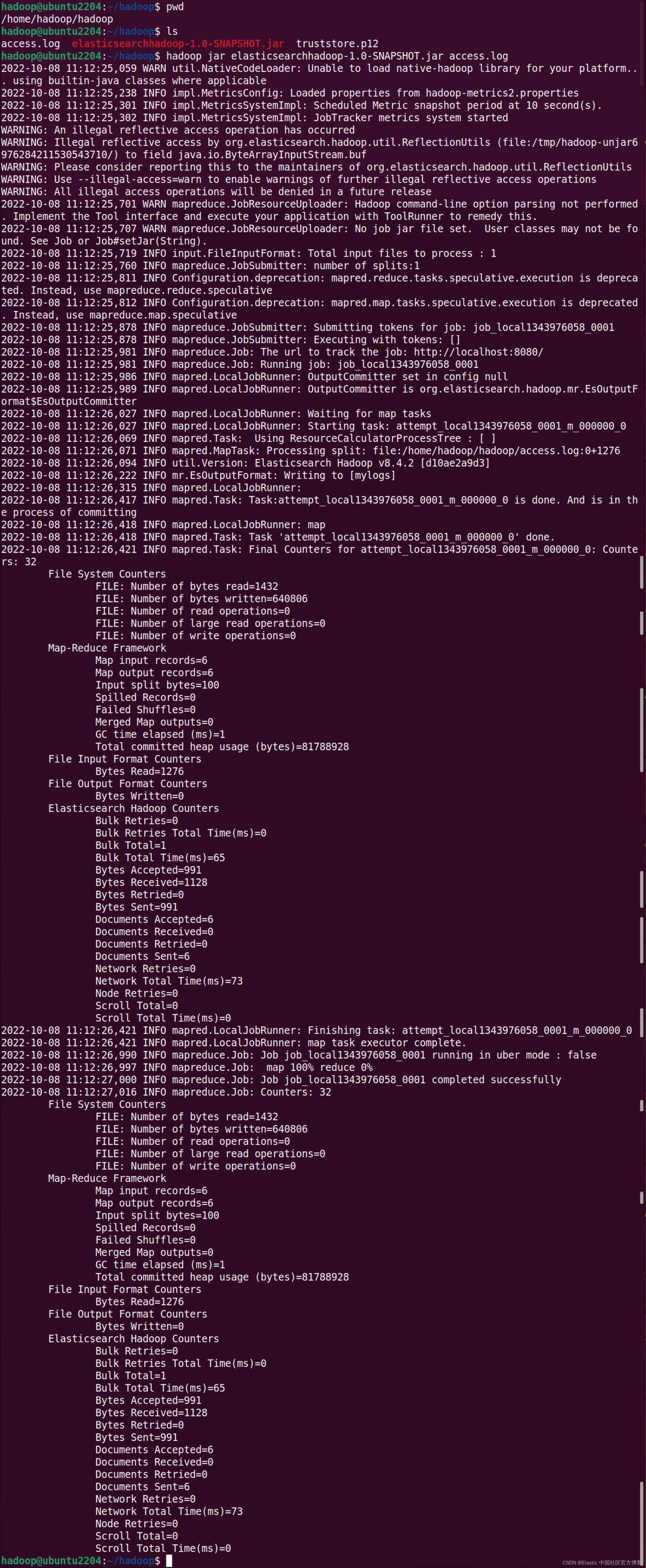
我们应该密切关注 Map-Reduce 框架部分。 在这种情况下,我们可以看到一切都按计划进行:我们有 6 条输入记录和 6 条输出记录。
我们可以在 Kibana 中执行如下的命令来进行查看:
GET mylogs/_count上面的命令返回结果:
"count": 6,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
它表明,我们有 6 个文档被摄入进来了。我们可以使用如下的命令来搜索:
GET mylogs/_search?filter_path=**.hits
"hits":
"hits": [
"_index": "mylogs",
"_id": "AgVLt4MBlWqpuHbH3mqB",
"_score": 1,
"_source":
"size": "3638",
"dateTime": "17/May/2015:23:05:48",
"ip": "77.0.42.68",
"httpStatus": "GET",
"responseCode": "200",
"url": "/favicon.ico"
,
"_index": "mylogs",
"_id": "AwVLt4MBlWqpuHbH3mqB",
"_score": 1,
"_source":
"size": "6146",
"dateTime": "17/May/2015:23:05:32",
"ip": "77.0.42.68",
"httpStatus": "GET",
"responseCode": "200",
"url": "/images/jordan-80.png"
,
"_index": "mylogs",
"_id": "BAVLt4MBlWqpuHbH3mqB",
"_score": 1,
"_source":
"size": "52315",
"dateTime": "18/May/2015:00:05:08",
"ip": "77.0.42.68",
"httpStatus": "GET",
"responseCode": "200",
"url": "/images/web/2009/banner.png"
,
"_index": "mylogs",
"_id": "BQVLt4MBlWqpuHbH3mqB",
"_score": 1,
"_source":
"size": "11214",
"dateTime": "18/May/2015:00:05:42",
"ip": "207.241.237.101",
"httpStatus": "GET",
"responseCode": "200",
"url": "/blog/geekery/find-that-lost-screen-session.html"
,
"_index": "mylogs",
"_id": "BgVLt4MBlWqpuHbH3mqB",
"_score": 1,
"_source":
"size": "0",
"dateTime": "18/May/2015:00:05:57",
"ip": "120.202.255.147",
"httpStatus": "GET",
"responseCode": "304",
"url": "/files/logstash/logstash-1.1.0-monolithic.jar"
,
"_index": "mylogs",
"_id": "BwVLt4MBlWqpuHbH3mqB",
"_score": 1,
"_source":
"size": "328",
"dateTime": "18/May/2015:00:05:43",
"ip": "207.241.237.104",
"httpStatus": "GET",
"responseCode": "404",
"url": "/geekery/find-that-lost-screen-session-2.html"
]
我们可以清楚地看到数据已经被成功地摄入到 Elasticsearch 中了。
我们接下来可以使用 Kibana 来做如何进行可视化的需求了。在这里就不再详述了。
参考:
【1】 Configuration | Elasticsearch for Apache Hadoop [8.4] | Elastic
【2】apache-pig Tutorial => Loading data from ElasticSearch
【3】https://www.vultr.com/docs/install-and-configure-apache-hadoop-on-ubuntu-20-04/
【5】Elasticsearch Hadoop Tutorial with Hands-on Examples - Coralogix
以上是关于Elasticsearch:Hadoop 大数据集成 (Hadoop => Elasticsearch)的主要内容,如果未能解决你的问题,请参考以下文章