(大数据)MapReduce
Posted 多元思维的开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(大数据)MapReduce相关的知识,希望对你有一定的参考价值。
MapReduce 是 Hadoop 大数据里的计算框架,也是一种编程模型。之所以称 MapReduce 是一种编程模型,是因为很多大数据计算框架都是基于 MapReduce 的思想实现的。
MapReduce 作为计算框架已经没有使用的价值了,完全可以使用像 Spark、Flink 这些计算框架来代替 MapReduce,那为什么还要讲它呢?这是因为 MapReduce 作为编程模型,其计算的思想是非常值得学习和运用的。
MapReduce 计算的过程主要分三个步骤:map、shuffle 和 reduce。
我以 “获取每个用户消费金额最大的订单” 这个需求为例来讲讲这三个步骤。
假设 HDFS 记录的订单数据是这样的:
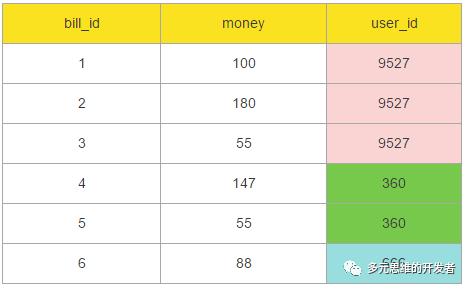
map 的计算过程:
首先从数据源读取相应数据,作为 map 的输入;然后 map 就会以 user_id 作为 key,用户的订单集合作为 value 这样的格式输出。如下图:
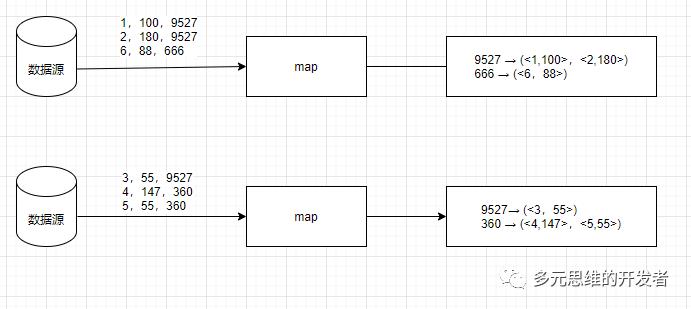
shuffle 的计算过程:
因为 map 的输出结果有可能还是会存在相同的 key,此时就将这些相同 key 对应的值进行汇聚,并重新输出。如下图:
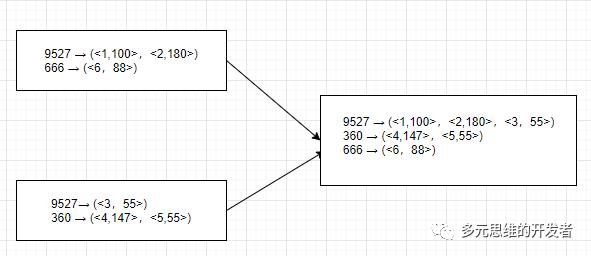
reduce 的计算过程:
shuffle 后的结果不会出现重复的 key,因此可以遍历这些结果集并从对应的 value (用户的订单集合),挑选出金额最大的订单 id。如下图:
上述三个步骤就是 MapReduce 的核心步骤,因为计算框架会自动帮我们实现 shuffle,所以我们在实现计算任务时只需要专注 map 和 reduce 这两个步骤即可。
那当我们提交了一个 MapReduce 作业后,它是怎么在 Hadoop 集群执行的呢?其过程如下:
首先 JobClient 会向 JobTracker 服务器提交 MapReduce 作业,然后 JobTracker 会根据 MapReduce 的情况向 ResourceManager 申请资源,并将 MapReduce 程序的 Jar 包上传到某个 DataNode 中。
然后,ResourceManager 分配资源并从中挑选一个 NodeManager 作为 MapReduce 程序的主节点,也就是 MRAppMaster,负责整个 MapReduce 作业的执行;其他的 NodeManager 作为 Map 任务和 Reduce 任务的执行节点。
接着,MRAppMaster 就会向从 ResourceManager 分配的 NodeManager 节点下发执行任务的命令。执行 Map 任务和 Reduce 任务,监听它们的执行情况和接收它们的执行结果。
最后,JobTracker 会 监听 MRAppMaster 的执行情况,一旦 MRAppMaster 执行完,JobTracker 就会将执行的结果返回给 JobClient。
整个执行过程如下图:
以上是关于(大数据)MapReduce的主要内容,如果未能解决你的问题,请参考以下文章