8 数据结构与算法
Posted sungc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了8 数据结构与算法相关的知识,希望对你有一定的参考价值。
8.1 链表
8.1.1 如何实现单链表的增删操作

8.1.2 如何从链表中删除重复的数据
- 如何从链表中删除重复数据,最容易想到的方法就是遍历链表,把遍历到的值存储到一个Hashtable中,在遍历过程中,若当前访问的值在Hashtable中已经存在,则说明这个数据是重复的,因此就可以删除。
- 主要思路为对链表进行双重循环遍历,外循环正常遍历链表,假设外循环当前遍历的结点为cur,内循环从cur开始遍历,若碰到与cur所指向结点值相同,则删除这个重复结点。
8.1.3 如何找出单链表中的倒数第K个元素
- 两个指针 先行指针比后行指针先行k-1个元素
8.14 如何实现链表的反转
- 具体的反转过程,例如,i, m, n是3个相邻的结点,假设经过若千步操作,已经把结点i之前的指针调整完毕,这些结点的next指针都指向前面-一个结点。现在遍历到结点m,当然,需要调整结点的next指针,让它指向结点i,但需要注意的是,一旦调整了指针的指向,链表就断开了,因为已经没有指针指向结点n,没有办法再遍历到结点n了,所以为了避免链表断开,需要在调整m的next之前要把n保存下来。接下来试着找到反转后链表的头结点,不难分析出反转后链表的头结点是原始链表的尾结点,即next;为空指针的结点。
- 下面给出非递归方法实现链表的反转的实现代码。
-

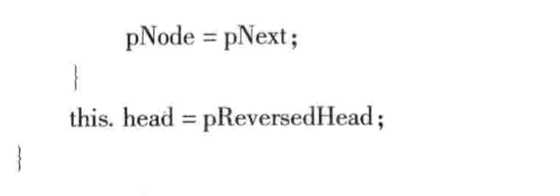
8.1.5 如何从尾到头输出单链表
- 从头到尾输出单链表比较简单,通过借鉴的想法,要想解决本问题,很自然地想把链表中链接结点的指针反转过来,改变链表的方向,然后就可以从尾到头输出了,但该方法需要额外的操作,是否还有更好的方法呢?答案是有。
- 接下来的想法是从头到尾遍历链表,每经过-一个结点,把该结点放到一个栈中。当遍历完整个链表后,再从栈顶开始输出结点的值,此时输出的结点的顺序已经反转过来了。该方法虽然没有只需要遍历一遍链表,但是需要维护--个额外的栈空间,实现起来会比较麻烦。
- 是否还能有更高效的方法?既然想到了栈来实现这个函数,而递归本质上就是一一个栈结构,于是很自然地又想到了递归来实现。要实现反过来输出链表,每访问到一个结点,先递归输出它后面的结点,再输出该结点自身,这样链表的输出结果就反过来了。
- 具体实现代码如下:
-
-
public Node SearchMid( Node head){
- Node p = this.head;
- Node q = this.head;
- while(p != null && p.next != null && p.next.next != null) {
- p = p.next.next;
- q=q.next;
- }
- return q;
- }
-
8.1.7 如何检测一个链表是否有环
- 定义两个指针fast与slow,其中,fast 是快指针,slow 是慢指针,二者的初始值都指向链表头,slow 每次前进一步,fast 每次前进两步,两个指针同时向前移动,快指针每移动一次都要跟慢指针比较,直到当快指针等于慢指针为止,就证明这个链表是带环的单向链表,否则,证明这个链表是不带环的循环链表( fast先行到达尾部为NULL,则为无环链表)。
- 具体实现代码如下:
-
-
public boolean IsLoop( Node head) {
- Node fast = head;
- Node slow = head;
- if( fast == null) {
- return false;
- }
- while(fast != null && fast.next != null) {
- fast = fast.next.next;
- slow = slow.next;
- if( fast == slow) {
- return true;
- }
- return !( fast == null || fast.next == null) ;
- }
-
- 上述方法只能用来判断链表是否有环,那么如何找到环的人口点呢?如果单链表有环,按照上述思路,当走得快的指针fast与走得慢的指针slow相遇时,slow指针肯定没有遍历完链表,而fast指针已经在环内循环了n圈(n>=1)。假设slow 指针走了s步,则fast指针走了2s步(fast 步数还等于s加上在环上多转的n圈),设环长为r,则满足如下关系表达式:
-
- 2s=s + nr
- s=nr
- 设整个链表长L,人口环与相遇点距离为x,起点到环人口点的距离为a,则满足如下关系表达式:
-
- a+x= nr
- a+x=(n-1)r+r=(n-1)r+L-a
- a=(n-1)r+(L-a-x)
- (L-a-x)为相遇点到环人口点的距离,从链表头到环人口点等于(n- 1)循环内环 + 相遇点到环入口点,于是在链表头与相遇点分别设一个指针,每次各走一步,两个指针必定相遇,且相遇第一点为环入口点。
- 具体实现代码如下:
-
-
public Node FindLoopPort( Node head){
- Node slow = head , fast = head ;
- while( fast != null && fast.next != null){
- slow = slow.next;
- fast = fast.next.next;
- if( slow == fast) break ;
- }
- if( fast == null || fast. next == null) return null;
- slow = head;
- while( slow != fast) {
- slow = slow.next;
- fast = fast.next;
- }
- return slow;
- }
-
8.1.8 如何在不知道头指针的情况下删除指定节点
- 可以分为两种情况来讨论:
-
- ①若待删除的结点为链表尾结点,则无法删除,因为删除后无法使其前驱结点的next指针置为空;
- ②若待删除的结点不是尾结点,则可以通过交换这个结点与其后继结点的值,然后删除后继结点。
- 具体实现代码如下:
-
-
public boolean deleteNode( Node n) {
- if( n == null || n.next == null)
- return false;
- int tmp = n.data;
- n.data = n.next.data;
- n.next.data = tmp;
- n.next = n.next.next;
- return true;
- }
-
8.1.9 如何判断两个链表是否相交
- 如果两个链表相交,那么它们一定有着相同的尾结点,因此实现思路为:分别遍历两个链表,记录它们的尾结点,如果它们的尾结点相同,那么这两个链表相交,否则不相交。
- 具体实现代码
-
-
public boolean isIntersect( Node h1, Node h2){
- if(h1 ==null || h2 == null)
- return false;
- Node taill = h1 ;
- //找到链表h1的最后一个结点
- while( taill.next ! = null)
- taill = taill. next;
- Node tail2 = h2 ;
- //找到链表h2的最后一个结点
- while( tail2.next ! = null){
- tail2 = tail2.next ;
- }
- return taill == tail2;
- }
-
- 由于这个算法只需要分别遍历一-次两个链表,因此算法的时间复杂度为O(len1 + len2),其中len1和len2分别代表两个链表的长度。
- 引申:
-
- 如果两个链表相交,如何找到它们相交的第一个结点?
- 首先分别计算两个链表head1、head2 的长度len1和len2 ( 假设len1 > len2),接着先对链表head1遍历(lenl - len2)个结点到结点p,此时结点p与head2到它们相交的结点的距离相同,此时同时遍历两个链表,直到遇到相同的结点为止,这个结点就是它们相交的结点。需要注意的是,在查找相交的第一一个结点前,需要先判断两个链表是否相交,只有在相交的情况下才有必要去找它们的交点,否则根本就没有必要了。
- 程序代码如下:
-
-
public static Node getFirstMeetNode( Node h1, Node h2) {
- if(h1 == null || h2 == null )
- return null ;
- Node tail1 = h1;
- int len1 =1;
- //找到链表h1的最后-一个结点
- while( taill.next != null){
- taill = taill.next;
- lenl++;
- Node tail2 = h2;
- int len2=1;
- //找到链表h2的最后一个结点
- while( tail2.next != null){
- tail2 = tail2. next ;
- len2 ++ ;
- }
- //两链表不相交
- if(taill ! = tail2) {
- return null;
- }
- Node t1 =h1 ;
- Node 12 = h2;
- //找出较长的链表,先遍历
- if(len1 > len2) {
- int d=lenl一len2 ;
- while(d! =0) {
- tl = t1.next;
- d-- ;
- }
- }
- else{
- int d= len2 - lenl;
- while(d! =0){
- t2 = t2.next;
- d--;
- }
- }
- while(t1! =t2) {
- t1 =t1. next;
- t2 = t2. next;
- return tl ;
- }
- }
-
- 同理,由于这个算法也只需要分别遍历一-次两个链表,因此算法的时间复杂度为O(len1 +len2),其中len1和len2分别代表两个链表的长度。当然,在具体实现时可以使用前面已经实现的方法来判断两个链表是否相交,也可以利用前面已经实现的方法来分别计算两个链表的长度。但这种方法也存在着-一个缺点:需要对每个链表遍历两遍。第- ~遍用来判断链表是否相交,第二遍计算链表的长度,因此效率会比上例中的实现方式低。其优点是代码简洁,可用性强。
8.2 栈与队列
Stack(栈)和 Queue(队列)
8.2.1 栈与队列有哪些区别
- 栈
-
- LIFO(Last In First Out,后进先出)
- 队列
-
- FIFO(First In Frist Out,先进先出)

8.2.2 如何实现栈
- 可以采用数组与链表这两种方法来实现栈。
- 下面给出用数组实现栈的代码:
-

- 下面给出采用链表实现栈的代码:
-
-
- 需要注意的是,上述的实现不是线程安全的。若要实现线程安全的栈,则需要对人栈和出栈等操作进行同步(synchronized)。

8.2.3 如何用0(1)的时间复杂度求栈中最小元素
- 由于栈具有后进先出的特点,因此push和pop只需要对栈顶元素进行操作。如果使用上述的实现方式,只能访问到栈顶的元素,而无法得到栈中最小的元素。当然,可以用另外一个变量来记录栈底的位置,通过遍历栈中的所有元素找出最小值,但是这种方法的时间复杂度为O(n),那么如何才能用0(1)的时间复杂度求出栈中最小的元素呢?在算法设计中,经常会采用空间来换取时间的方式来提高时间复杂度,也就是说,采用额外的存储空间来降低操作的时间复杂度。具体来讲就是在实现时使用两个栈结构,一个栈用来存储数据,另一个栈用来存储栈的最小元素。其实现思路如下:如果当前人栈的元素比原来栈中的最小值还小,则把这个值压人保存最小元素的栈中;在出栈时,如果当前出栈的元素恰好为当前栈中的最小值,保存最小值的栈顶元素也出栈,使得当前最小值变为其入栈之前的那个最小值。为了简单起见,可以在栈中保存Interger类型,采用前面用链表方式实现的栈,
- 实现代码如下:

8.2.4如何实现队列
- 与栈类似,队列也可以采用数组和链表两种方式来实现。
- 下面给出采用链表方式实现队列的代码:


- 下面介绍数组实现队列的方式,为了实现多线程安全,增加了对队列操作的同步,实现代码如下:


8.2.5 如何用两个栈模拟队列操作
- 假设使用栈A与栈B模拟队列Q,A为插人栈,B为弹出栈,以实现队列Q。再假设A和B都为空,可以认为栈A提供入队列的功能,栈B提供出队列的功能。要人队列,入栈A即可,而出队列则需要分两种情况考虑
-
- 1)若栈B不为空,则直接弹出栈B的数据。
- 2)若栈B为空,则依次弹出栈A的数据,放人栈B中,再弹出栈B的数据。
- 以上情况可以利用前面介绍的栈来实现,也可以采用Java类库提供的Stack来实现,下面代码是采用Java内置的Stack来实现的:

- 引申:如何使用两个队列实现栈?
-
- 假设使用队列q1与队列q2模拟栈S, q1为人队列,q2为出队列。
- 实现思路:
-
- 可以认为队列q1提供压栈的功能,队列q2提供弹栈的功能。要压栈,人队列q1即可,而当弹栈时,出队列则需要分两种情况考虑:
-
- 1)若队列q1中只有一一个元素,则让q1中的元素出队列并输出即可。
- 2)若队列q1中不只一个元素,则队列q1中的所有元素出队列,入队列q2,最后一个元素不人队列B,输出该元素,然后将队列q2所有元素人队列q1。
8.3 排序
排序问题一直是计算机技术研究的重要问题,排序算法的好坏直接影响程序的执行速度和辅助存储空间的占有量,所以,各大IT企业在笔试面试中也经常出现有关排序的题目,本节将详细分析常见的各种排序算法,并从时间复杂度、空间复杂度、适用情况等多个方面对它们进行综合比较。
8.3.1如何进选择排序
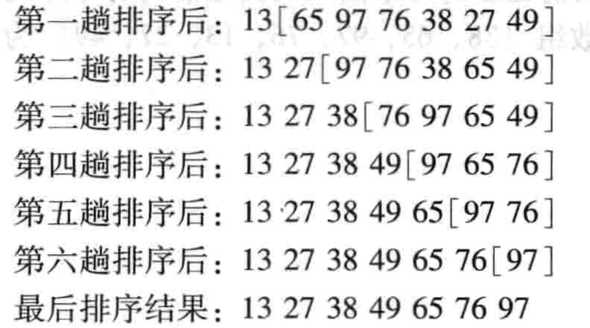
- 选择排序是-一种简单直观的排序算法,其基本原理如下:对于给定的一组记录,经过第一轮比较后得到最小的记录,然后将该记录与第一个记录的位置进行交换;接着对不包括第一个记录以外的其他记录进行第二轮比较,得到最小的记录并与第-二个记录进行位置交换;重复该过程,直到进行比较的记录只有一个时为止。以数组{ 38,65,97, 76,13, 27,49 }为例,
- 选择排序的具体步骤如下:
8.3.2如何进行插人排序
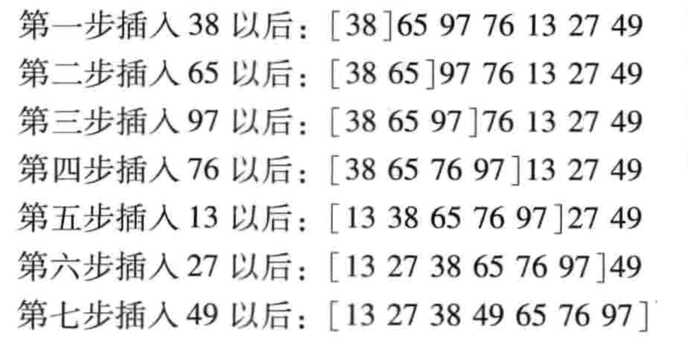
- 对于给定的一组记录,初始时假设第一个记录自成一个有序序列,其余记录为无序序列。接着从第二个记录开始,按照记录的大小依次将当前处理的记录插人到其之前的有序序列中,直至最后一个记录插人到有序序列中为止。仍以数组{ 38,65,97 , 76,13, 27, 49 }为例,
- 直接插入排序的具体步骤如下。
8.3.4如何进归并排序
- 归并排序是利用递归与分治技术将数据序列划分成为越来越小的半子表,再对半子表排序,最后再用递归方法将排好序的半子表合并成为越来越大的有序序列。归并排序中,“归”代表的是递归的意思,即递归的将数组折半的分离为单个数组,例如数组: [2,6,1,0],会先折半,分为[2,6]和[1,0]两个子数组, 然后再折半将数组分离,分为[2]、[6]和[1]、[0]。“并”就是将分开的数据按照从小到大或者从大到小的顺序在放到-一个数组中。如上面的[2]、[6]合并到一个数组中是[2,6],[1]、[0]合并到一个数组中是[0,1],然后再将[2,6]和[0,1]合并到一个数组中即为[0,1,2,6]。
- 归并排序算法的原理如下:对于给定的一-组记录(假设共有n个记录),首先将每两个相邻的长度为1的子序列进行归并,得到n/2 (向上取整)个长度为2或1的有序子序列,再将其两两归并,反复执行此过程,直到得到一个有序序列。
- 所以,归并排序的关键就是两步:第一步,划分半子表;第二步,合并半子表。以数组{49 ,38 ,65 ,97 ,76,13 ,27}为例,归并排序的具体步骤如下:
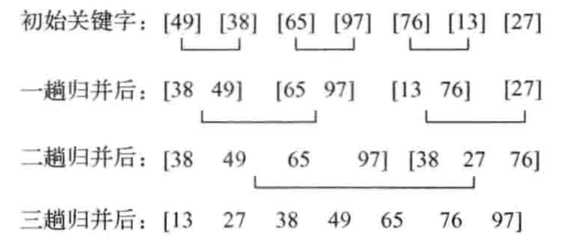
- 二路归并排序的过程需要进行logn趟。每一趟归并排序的操作,就是将两个有序子序列进行归并,而每一-对有序子序列归并时,记录的比较次数均小于等于记录的移动次数,记录移动的次数均等于文件中记录的个数n,即每一趟归并的时间复杂度为O(n)。因此,二路归并排序的时间复杂度为0( nlogn)。
8.3.5 如何进行快速排序
- 快速排序,顾名思义,是一种速度快,效率高的排序算法。
-
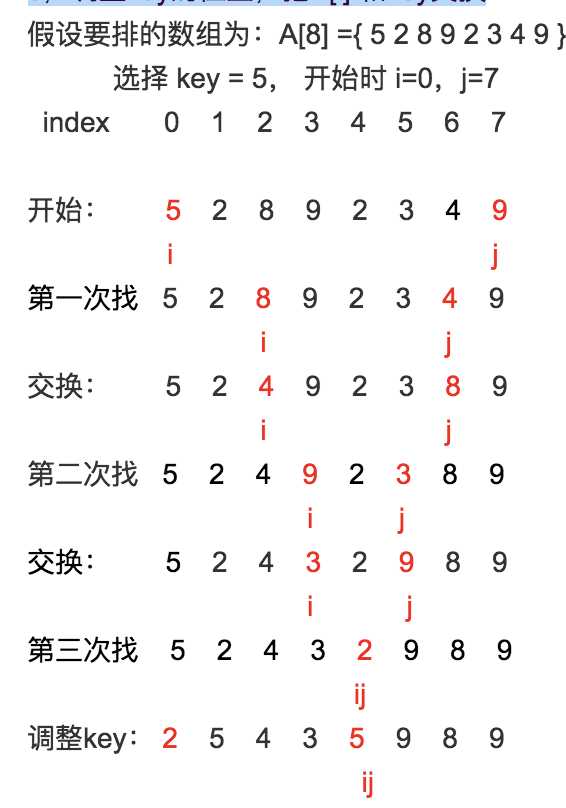
快排原理:在要排的数(比如数组A)中选择一个中心值key(比如A[0]),通过一趟排序将数组A分成两部分,其中以key为中心,key右边都比key大,key左边的都key小,然后对这两部分分别重复这个过程,直到整个有序。
整个快排的过程就简化为了一趟排序的过程,然后递归调用就行了。
一趟排序的方法:
-
1,定义i=0,j=A.lenght-1,i为第一个数的下标,j为最后一个数下标
-
2,从数组的最后一个数Aj从右往左找,找到第一小于key的数,记为Aj;
-
3,从数组的第一个数Ai 从左往右找,找到第一个大于key的数,记为Ai;
-
4,交换Ai 和Aj
-
5,重复这个过程,直到 i=j
-
6,调整key的位置,把A[i] 和key交换
- java代码
-
-
public class testMain {
- public static void sort(int array[], int low, int high) {
- int i, j;
- int index;
- if (low >= high)
- return;
- i = low;
- j = high;
- index = array[i];
- //index = array[(low+high)/2];
- //array[(low+high)/2] = array[i];
- while (i < j) {
- while (i < j && array[j] >= index) {
- j--;
- }
- if (i < j) {
- array[i++] = array[j];
- }
- while (i < j && array[i] < index) {
- i++;
- }
- if (i < j) {
- array[j--] = array[i];
- }
- array[i] = index;
- sort(array, low, i - 1);
- sort(array, i + 1, high);
- }
- }
- public static void quickSort(int array[]) {
- sort(array, 0, array.length - 1);
- }
- public static void main(String[] args) {
- int i = 0;
- int a[] = { 5, 4, 9, 8, 7, 6, 0, 1, 3, 2 };
- quickSort(a);
- for (i = 0; i < a.length; i++) {
- System.out.println(a[i]);
- }
- }
- }
-
8.3.6 如何进行希尔排序
希尔排序也被称为“ 缩小增量排序”,其基本原理如下:先将待排序的数组元素分成多个子序列,使得每个子序列的元素个数相对较少,然后对各个子序列分别进行直接插人排序,待整个待排序序列“ 基本有序后”,最后再对所有元素进行一次直接插入排序。
8.3.7 如何进行堆排序
堆是一种特殊的树形数据结构,其每个结点都有一一个值,通常提到的堆都是指一棵完全二叉树,根结点的值小于(或大于)两个子结点的值,同时,根结点的两个子树也分别是一个堆。
堆排序是一树形选择排序,在排序过程中,将R[1...n]看作一颗完全二叉树的顺序存储结构,利用完全二叉树中父结点和子结点之间的内在关系来选择最小的元素。
8.3.8 各种排序算法有什么差异
- 不稳定:
-
- 选择排序(selection sort)— O(n2)
- 快速排序(quicksort)— O(nlogn) 平均时间, O(n2) 最坏情况; 对于大的、乱序串列一般认为是最快的已知排序
- 堆排序 (heapsort)— O(nlogn)
- 希尔排序 (shell sort)— O(nlogn)
- 基数排序(radix sort)— O(n·k); 需要 O(n) 额外存储空间 (K为特征个数)
- 稳定:
-
- 插入排序(insertion sort)— O(n2)
- 冒泡排序(bubble sort) — O(n2)
- 归并排序 (merge sort)— O(n log n); 需要 O(n) 额外存储空间
- 二叉树排序(Binary tree sort) — O(nlogn); 需要 O(n) 额外存储空间
- 计数排序 (counting sort) — O(n+k); 需要 O(n+k) 额外存储空间,k为序列中Max-Min+1
- 桶排序 (bucket sort)— O(n); 需要 O(k) 额外存储空间
8.4 位运算
8.4.1 如何用位操作实现乘法运算
- 把数字向左移动n位相当于把改数乘以2的n次方。
8.4.2 如何判断一个数是否为2的n次方

- 上述算法的时间复杂度为0( logn)。 那么是否存在效率更高的算法呢?通过对2^0,2^1,2^2,.,2^n 进行分析,发现这些数字的二进制形式分别为: 1,10,100,….从二进制的表示可以看出,如果-一个数是2 的n次方,那么这个数对应的二进制表示中只有一位是1,其余位都为0。因此,判断-一个数是否为2的n次方可以转换为这个数对应的二进制表示中是否只有一位为1。如果一个数的二进制表示只有一位是1,例如num =00010000,那么num-1的二进制表示为num-1=00001111,由于num与num-1二进制表示中每一位都不相同,因此num&( num- 1)的运算结果为0,可以利用这种方法来判断一一个数是否为2的n次方。
-
- 具体实现代码如下:

8.4.3 如何求二进制数中1的个数
- 问题描述:给定-一个整数,输出这个整数二进制表示中1的个数,例如,给定整数7,其二进制表示为111,因此输出结果为3。该问题可以采用位操作来完成。具体思路如下:首先,判断这个数的最后- -位是否为1,如果为1,则计数器加1,然后,通过右移丢弃掉最后一位。循环执行该操作直到这个数等于0为止。在判断二进制表示的最后一一位是否为1时,可以采用与运算来达到这个目的。
-
- 具体实现代码如下:

- 给定一个数n,每进行一次n&(n-1)计算,起结果中都会少了一位1,而且是最后一位。利用这个特性编写如下代码。
-

8.5 数组
8.5.1 如何寻找数组中的最小值和最大值
- 1. 问题分解法。 将问题分解,找最大、找最小。
- 2. 取单元素法。一次找最大最小,及取出一个值比较是否是最大,是否是最小。
- 3. 取双元素法。 每次取两个元素,大的与max比较,小的与min比较。
- 4. 数组元素位移法。 将数组中相邻的两个数大的放左边小的放右边。对大值扫描一次取最大值。对小值扫描一次取最小值。
- 5. 分治法。 将数组分为两组,分别取最大值、最小值。则两组值中取最大值、最小值。
8.5.2 如何找到数组中第二大的数
- 1. 可先排序然后找到第二大的数。(一般为快速排序算法)
- 2. 设置两值,max 、sec_max
-

8.5.3 如何求最大子数组之和
- 问题描述: -一个有n个元素的数组,这n个元素可以是正数也可以是负数,数组中连续的一个或多个元素可以组成一个连续的子数组,一一个数组可能有多个这种连续的子组,求子数组和的最大值,例如:对于数组{1, -2, 4, 8, -4, 7, -1, -5}而言,其最大和的子数组为{4, 8,-4, 7},最大值为15。
- 方法一:暴力法
- 最简单也是最容易想到的方法就是找出所有子数组,然后求出子数组的和,在所有子数组的和中取最大值。


- 方法二:重复利用已经计算的子数组和。
- 例如Sum[i,j] = Sum[i,j-1] +arr[j],采用这种方法可以省去计算Sum[i,j-1]的时间,因此可以提高程序的效率。示例如下:

- 方法三:动态规划方法
- 可以采用动态规划的方法来降低算法的时间复杂度,实现思路如下。首先可以根据数组的最后一个元素arr[n-1]与最大字数组的关系分为以下3种情况:
-
- 1)最大子数组的包含arr[n-1],即以arr[n-1]结尾。
- 2) arr[n-1] 单独构成最大子数组。
- 3)最大子数组不包含arr[n-1],那么求arr[1,*,n-1]的最大子数组可以转换为求arr[1,.*,n-2]的最大子数组。
- 通过上述分析可以得出如下结论:假设已经计算出( arr[0],",arr[i-1])最大的一段数,组和为All[i-1],同时也计算出(arr[0],.. ,arr[i-1])中包含arr[i-1]的最大的一-段数组和为End[i-1], 则可以得出如下关系: All[i-1] = max{arr[i-1], End[i-1],All[i-2]}。
- 利用这个公式和动态规划的思想可以得到如下代码:
-
- 方法四:优化的动态规划方法
- 方法三中每次只用到End[i-1]与All[i-1],而不是整个数组中的值,因此可以定义两个变量来保存End[i-1]与All[i-1]的值,并且可以反复利用,这样就可以在保证时间复杂度为O( n)的同时降低空间复杂度。示例如下:



- 在知道子数组的最大和之后,如何才能确定最大子数组的位置呢?为了得到最大子数组的位置,首先介绍另外一+种计算最大子数组和的方法。在方法三中,通过对公式End[i]= max(End[i-1] +arr[i],arr[i])的分析可以看出,当End[i-1]<0时,End[i门] = array[i],其中,End[i]表示包含array[i] 的子数组和,如果某-一个值使得End[i-1] <0,那么就从arr[ i门]重新开始。示例如下:

8.5.4 如何找出数组中重复元素最多的数
- 问题描述:对于数组{1,1,2,2,4,4,4,4,5,5,6,6,6}, 元素1出现的次数为2次,元素2出现的次数为2次,元素4出现的次数为4次,元素5出现的次数为2次,元素6出现的次数为3次,找出数组中出现重复次数最多的数。
- 上述问题中,程序的输出应该为元素4。可以采取如下两种方法来计算数组中重复次数最多的数。
- 方法一:空间换时间。可以定义一个数组int count[ MAX],并将其数组元素都初始化为0,然后执行for(int i=0;i<100;i ++ )count[A[i]] ++操作,在count数组中找最大的数,即为重复次数最多的数。这是一种典型的空间换时间的算法。一般情况下,除非内存空间足够大,一般不采用这种方法。
- 方法二:使用Map映射表。通过引入Map映射表( Map提供- -对一的数据处理能力,其中第-一个为关键字,每个关键字只能在Map中出现-一次,第二个称为该关键字的值)来记录每一个元素出现的次数,然后判断次数大小,进而找出重复次数最多的元素。示例如下:

8.5.5 如何求数组中两两相加等于20的组合种数
- 问题描述:给定一一个数组{1,7,17,2,6,3,14},这个数组中满足条件的有两对组合 17 + 3 = 20和6 + 14 =20。
- 方法一:“蛮力”法
- 最容易想到的方法就是采用两重循环遍历数组来判断两个数的和是否为20。
- 实现代码如下:

- 由于采用了双重循环,因此这个算法的时间复杂度为O(n^2)。
- 方法二:排序法
- 先对数组元素进行排序,可以选用堆排序或快速排序,此时算法的时间复杂度为0( nlogn),然后对排序后的数组分别从前到后和从后到前遍历,假设从前往后遍历的下标为begin,从后往前遍历的下标为end,那么当满足arr[ begin] + arr[ end] <20时,如果存在两个数的和为20,那么这两个数一-定在[ begin +1,end]之间;当满足ar[ begin] + arr[ end] > 20时,如果存在两个数的和为20,那么这两个数一定在[ begin ,end +1]之间。这个过程的时间复杂度为0(n),因此整个算法的时间复杂度为0( nlogn)。
- 实现代码如下:

8.5.6 如何把个数组循环右移k位
- 假设要把数组序列12345678 右移2位变为78123456,比较移位前后数组序列的形式,不难看出,其中有两段序列的顺序是不变的,即78和123456,可以把这两段看作两个整体,右移k位就是把数组的两部分交换一下。鉴于此,可以设计这样一种算法,步骤如下,(以数组序列12345678为例) :
-
- 1)逆序数组子序列123456, 数组序列的形式变为65432178。
- 2)逆序数组子序列78,数组序列的形式变为65432187。
- 3)全部逆序,数组序列的形式变为78123456。
- 程序代码如下:

8.5.7 如何找出数组中第k个最小的数
- 问题描述:给定一个无序的数组,从一个数组中找出第k个最小的数,例如,对于给定数组序列{1,5,2,6,8,0,6},其中第4小的数为5。
- 方法一:排序法
- 最容易想到的方法就是对数组进行排序,排序后的数组中第k-1个位置上的数字即为数组的第k个最小的数(原因是数组下标从0开始计数),这种方法最好的时间复杂度为O( nlogn)。
- 方法二:“剪枝”法
- 采用快速排序的思想来实现。主要思路如下:选一个数tmp=a[n-1]作为枢纽,把比它小的数都放在它的左边,比它大的数都放在它的右边,然后判断tmp的位置,如果它的位置为k-1,那么它就是第k个最小的数;如果它的位置小于k-1,那么说明第k个小的元素一定在数组的右半部分,采用递归的方法在数组的右半部分继续查找;否则第k个小的元素在数组的左半部分,采用递归的方法在左半部分数组中继续查找。
- 示例如下:


- 表面上看起来这种方法还是在对数组进行排序,但是它比排序法的效率高,主要原因是当在数组右半部分递归查找时,完全不需要关注左半部分数组的顺序,因此省略了对左半部分数组的排序。因此,这种方法可以被看作一种“剪枝”方法,不断缩小问题的规模,直到找到第k个小的元素。
8.5.8 如何找出数组中只出现一次的数字
- 问题描述:一个整型数组里除了一个数字之外,其他数字都出现了两次。找出这个只出现1次的数字。要求时间复杂度是0(n),空间复杂度是0(1)。如果本题对时间复杂度没有要求,最容易想到的方法就是先对这个整型数组排序,然后从第一个数字开始遍历,比较相邻的两个数,从而找出这个只出现1次的数字,这种方法的时间复杂度最快为0( nlogn)。
- 由于时间复杂度与空间复杂度的限制,该方法不可取,因此需要一种更高效的方式。题目强调只有一个数字出现1次,其他数字出现了两次,首先想到的是异或运算,根据异或运算的定义可知,任何一个数字异或它自己都等于0,所以,如果从头到尾依次异或数组中的每一个数字,那些出现两次的数字全部在异或中会被抵消掉,最终的结果刚好是这个只出现1次的数字。示例如下:

- 引申:如果题目改为数组A中,一个整型数组里除了-一个数字之外,其他数字都出现了3次,那么如何找出这个数?上述异或运算的方法只适用于其他数字出现的次数为偶数的情况,如果其他数字出现的次数为奇数,,上述介绍的方法则不再适用。如果数组中的所有数都出现n次,那么这个数组中的所有数对应的二进制数中,各个位,上的1出现的个数均可以被n整除。以n=3为例,假如数组中有如下元素:{1,1,1,2,2,2}, 它们对应的二进制表示为01,01,01,10,10,10。显然,这个数组中的所有数字对应的二进制数中第0位有3个1,第1位有3个1。对于本题而言,假设出现一次的这个数为a,那么去掉a后其他所有数字对应的二进制数的每个位置出现1的个数为3的倍数。因此可以对数组中的所有数字对应的二进制数中各个位置上1的个数对3取余数,就可以得到出现1次的这个数的二进制表示,从而可以找出这个数。示例如下:

8.5.9 如何找出数组中唯的重复元素
- 问题描述:数组a[N],1 ~N-1这N-1个数存放在a[N]中,其中某个数重复1次。写一个函数,找出被重复的数字。要求每个数组元素只能访问1次,并且不用辅助存储空间。由于题目要求每个数组元素只能访问1次,且不用辅助存储空间,因此可以从原理上人手,采用数学求和法,因为只有一个数字重复1次,而又是连续的,根据累加和原理,对数组的所有项求和,然后减去1 ~ N-1的和,即为所求的重复数。
- 示例如下:

- 如果题目没有要求每个数组元素只能访问1次,且不允许使用辅助存储空间,还可以用异或法和位图法来求解。
- 1. 异或法
- 根据异或法的计算方式,每两个相异的数执行异或运算之后,结果为1;每两个相同的数执行异或运算之后,结果为0,所以,数组a[N]中的N个数异或结果与1 ~ N-1异或的结果再做异或运算,得到的值即为所求。设重复数为A,其余N-2个数异或结果为B,N个数异或结果为A^A^B,1 ~ N-1异或结果为A^B,由于异或满足交换律和结合律,且X^X=0, 0^X=X,则有(A^B)^(A^A^B) =A^B^B=A。
- 示例如下:

- 2. 空间换时间法
- 申请长度为N-1的整型数组flag并初始化为0,然后从头开始遍历数组a,取每个数组元素a[i]的值,将其对应的数组flag 中的元素赋值为1,如果已经置过1,那么该数就是重复的数。
- 示例如下:


- 此题可以进行-一个变形:取值为[1,n-1] 含n个元素的整数数组,至少存在一个重复数,即可能存在多个重复数,O(n)时间内找出其中任意一个重复数,例如,array[] ={1,2,2,4,5,4},则2和4均是重复元素。
-
- 方案一:位图法。使用大小为n的位图,记录每个元素是否已经出现过,一-旦遇到一个已经出现过的元素,则直接将之输出。该方法的时间复杂度是O(n),空间复杂度为0(n)。
- 方案二:数组排序法。先对数组进行计数排序,然后顺序扫描整个数组,一旦遇到一个已出现的元素,则直接将之输出。该方法的时间复杂度为O(n),空间复杂度为O(n)。
8.5.10 如何用递归方法求个整数数组的最大元素
- 对于本题而言,最容易实现的方法为对数组进行遍历,定义一个变量max为数组的第一个元素,然后从第二个元素开始遍历,在遍历过程中,每个元素都与max的值进行比较,若该元素的值比max的值大,则把该元素的值赋给max。当遍历完数组后,最大值也就求出来了。 而使用递归方法求解的主要 思路为:递归的求解“数组第一 一个元素”与“数组中其他元素组成的子数组的最大值”的最大值。
- 示例如下:

8.5.11 如何求数对之差的最大值
- 问题描述:数组中的一个数字减去它右边子数组中的一一个数字可以得到一一个差值,求所有可能的差值中的最大值,例如,数组{1,4,17,3,2,9}中,最大的差值为17-2=15。
- 方法一:“蛮力”法。“蛮力”法也是最容易想到的方法,
- 其原理如下:
- 首先,遍历数组,找到所有可能的差值;其次,从所有差值中找出最大值。具体实现方法为:针对数组a中的每个元素a[i](0<i<n-1),求所有a[i] -a[j](i<j<n)的值中的最大值。
- 示例如下:

- 方法二:二分法;
- 方法三:动态规划;
8.5.12 如何求绝对值最小的数
- 二分法
8.5.14 如何制定数字在数组中第一次出现的位置
- 二分查找法
- 暴力法
8.5.15 如何对数组的两个子有序段进行合并
- 实现思路:首先,遍历数组中”下标为0~ mid-1的元素,将遍历到的元素的值与a[ mid ]进行比较,当遍历到a[i](0<=i<= mid-1)时,如果满足a[ mid] <a[门], 那么交换a[i门]与a[mid]的值。接着找到交换后的a[mid]在a[mid,num-1]中的具体位置(在a[mid,num-1]中进行插入排序),实现方法为:遍历a[ mid~ num-2],如果a[ mid+1] < a[ mid],那么交换a[ mid]与a[mid +1]的位置。
8.5.16 如何计算两个有序整型数组的交集
- 二路归并。
- 顺序遍历法。
- 散列法。
8.5.17 如何判断一个数组中数值是否连续相邻
8.5.18如何求解数组中反序对的个数
- 问题描述:给定一个数组a,如果a[i] >a[j](i<j),那么a[i]与a[j]被称为一个反序,例如,给定数组{1,5,3,2,6}, 共有(5,3)、(5,2)和(3,2)三个反序对。
- 方法一:“蛮力”法。最容易想到的方法是对数组中的每一一个数字,遍历它后面的所有数字,如果后面的数字比它小,那么就找到一个逆序对,实现代码如下:
- 方法二:分治归并法。可以参考归并排序的方法,在归并排序的基础上额外使用- -. 个计数器来记录逆序对的个数。’下 面以数组序列{5,8,3,6} 为例,说明计数的方法。
8.6 字符串
8.6.1 如何实现字符串的反转
- 这道题的解决方法比较简单,只需要进行两次字符反转的操作即可,第一次对整个字符串中的字符进行反转,反转结果为:“uoy era woh",通过这一- 次的反转已经实现了单词顺序的反转,只不过每个单词中字符的顺序反了,接下来只需要对每个单词进行字符反转即可得到想要的结果:“you are how"。
8.6.2 如何判断两个字符串是否由相同的字符组成
- 问题描述:由相同的字符组成是指组成两个字符串的字母以及各个字母的个数是一样 的,只是排列顺序不同而已,例如,“ aaabbe”与“abcbaaa”就由相同的字符组成的。下面讲述判断给定的两个字符串是否由相同的字符组成的方法。
- 方法一:排序法。最容易想到的方法就是对两个字符串中的字符进行排序,比较两个排序后的字符串是否相等。若相等,则表明它们是由相同的字符组成的,否则,则表明它们是由不同的字符组成的。
- 方法二:空间换时间。在算法设计中,经常会采用空间换时间的方法以降低时间复杂度,即通过增加额外的存储空间来达到优化算法的效果。就本题而言,假设字符串中只使用ASCII字符,由于ASCII字符共有266个( 对应的编码为0 ~ 255),在实现时可以通过申请大小为266的数组来记录各个字符出现的个数,并初始化为0,然后遍历第-一个字符串,将字符串中字符对应的ASCII码值作为数组”下标,把对应数组的元素加1,然后遍历第二个字符串,把数组中对应的元素值-1。如果最后数组中各个元素的值都为0,说明这两个字符串是由相同的字符组成的;否则,说明这两个字符串是由不同的字符组成的。
8.6.3 如何删除字符串中重复的字符
- 问题描述:删除字符串中重复的字符,例如,“good"去掉重复的字符后就变为“god"。
- 方法一:“蛮力”法。最简单的方法就是把这个字符串看作-一个字符数组,对该数组使用双重循环进行遍历,如果发现有重复的字符,就把该字符置为‘�’,最后再把这个字符数组中的所有‘�’去掉,此时得到的字符串就是删除重复字符后的目标字符串。
- 方法二:空间换时间。在算法中经常会采用空间换时间的方法。对于这个问题,也可以采取这种方法。其主要思路如下:由于常见的字符只有256个,可以假设这道题字符串中不同的字符个数最多为256个,那么可以申请一个大小为256的int类型的数组来记录每个字符出现的次数,初始化都为0,把这个字符的编码作为数组的下标,在遍历字符数组时,如果这个字符出现的次数为0,那么把它置为1;如果这个字符出现的次数为1,说明这个字符在前面已经出现过了,就可以把这个字符置为 0‘,最后去掉所有‘�’,就实现了去重的目的。采用这种方法只需要对字符数组进行--次遍历即可,因此时间复杂度为O(n),但是需要额外申请256大小的空间。由于申请的数组用来记录一个字符是否出现,只需要lbit就能实现这个功能,因此作为更好的一一种方案,可以只申请大小为8的int类型的数组,由于每个int类型占32bit,因此大小为8的数组总共为256bit,用1bit来表示-一个字符是否已经出现过可以达到同样的目的。
- 方法三:正则表达式。在Java语言中,利用正则表达式也可以达到同样的目的: (? s)(. )(?=. *\\1)。
8.6.4 如何统计行字符中有多少个单词
- 单词的数目可以由空格出现的次数决定(连续的若于个空格作为出现一-次空格; 一行开头的空格不统计在内)。若测出某一个字符为非空格,而它的前面的字符是空格,则表示“新的单词开始了”,此时使单词计数器count值加1;若当前字符为非空格而其前面的字符也是非空格,则意味着仍然是原来那个单词的继续,count 值不应再累加1。前面一个字符是否空格可以从word的值看出来,若word等于0,则表示前一个字符是空格;若word等于1,意味着前一个字符为非空格。
8.6.5 如何按要求打印数组的排列情况
8.6.6 如何输出字符串的所有组合
- 暴力法
- 递归
8.7 二叉树
- 二叉树是一种非常 常见并实用的数据结构, 它结合了有序数组与链表的优点,在二叉树中查找数据与在数组中查找数据一样快,在二叉树中添加删除数据的速度也与在链表中一样高效,所以,有关二叉树的相关技术- -直是程序员面试笔试中必考的知识点。
8.7.1 二叉树的基本概念



8.7.2 如何实现:叉排序树
- 二叉排序树又称二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树:①如果左子树不空,那么左子树上所有结点的值均小于它的根结点的值;②如果右子树不空,那么右子树上所有结点的值均大于它的根结点的值;③左、右子树也分别为二叉排序树。由于二叉树具有有序的特定,因此在笔试或面试过程中经常会出现二叉排序树相关的题目。
8.7.3 如何层序遍历二叉树
- 可以使用队列来实现二叉树的层序遍历。其主要思路如下:先将根结点放入队列中,然后每次都从队列中取出一个结点打印该结点的值,若这个结点有子结点,则将它的子结点放入队列尾,直到队列为空。
8.7.5 如何求二叉树中结点的最大距离
- 问题描述:结点的距离是指这两个结点之间边的个数。写一个程序求一棵二叉树中相距最远的两个结点之间的距离。一般而言,对二叉树的操作通过递归方法实现比较容易。求最大距离的主要思想如下:首先,求左子树距根结点的最大距离,记为leftMaxDistance;其次,求右子树距根结点的最大距离,记为rightMaxDistance,那么二叉树中结点的最大距离maxDistance满足maxDistance = leftMaxDistance + rightMaxDistance。
8.8 其他
8.8.1 如何消除嵌套的括号
- 问题描述:给定-一个如下格式的字符串(1,(2,3),(4,(5,6),7)), 括号内的元素可以是数字,也可以是另一个括号,实现-一个算法以消除嵌套的括号,例如,把上面的表达式变成(1,2,3,4,5,6,7), 若表达式有误,则报错。从问题描述可以看出,这道题要求实现两个功能:一-是判断表达式是否正确;二是消除表达式中嵌套的括号。对于判定表达式是否正确这个问题,可以从如下几个方面来人手:首先,表达式中只有数字、逗号和括号这几种字符,如果有其他字符出现则是非法表达式;其次,判断括号是否匹配,若碰到“(”,则把括号的计数器值加1;如果碰到“)”,此时再判断计数器值是否大于1,若是,则把计数器减1,否则为非法表达式。当遍历完表达式后,若括号计数器值为0,则说明括号是配对出现的,否则说明括号不配对,则表达式为非法表达式。
8.8.2 如何不使用比较运算就可以求出两个数的最大值与最小值
- 通常来讲,在求两个数中的最大值或最小值时,最常用的方法就是比较大小。下面给出一种不需比较大小就可以求出两个数中的最大值与最小值的方法,该方法用到了- ~种比较巧妙的数学方法,即最大值Max(a,b) =(a+b+|a-b|)/2,最小值Min(a,b) =(a+b- |a-b| )/2。当然,这种方法存在着一个问题,即当a与b的值非常大时,会出现数据溢出的情况,解决的办法就是在计算时把a与b的值转换为长整型,从而可以避免溢出的发生。示例如下:
以上是关于8 数据结构与算法的主要内容,如果未能解决你的问题,请参考以下文章