Mapreducer任务启动
Posted zwcoding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mapreducer任务启动相关的知识,希望对你有一定的参考价值。
一、Streaming
#!/bin/bash hadoop fs -rm -r/data/apps/zhangwenchao/mapreduce/streaming/wordcount/output hadoop jar /data/tools/hadoop/hadoop-2.6.2/share/hadoop/tools/lib/hadoop-streaming-2.6.2.jar -input /data/apps/zhangwenchao/mapreduce/streaming/wordcount/input -output /data/apps/zhangwenchao/mapreduce/streaming/wordcount/output -mapper "sh -x mapper.sh" -reducer "sh -x reducer.sh" -file mapper.sh -file reducer.sh -jobconf mapred.job.name=wordcount -jobconf mapred.job.tasks=5 -jobconf mapred.reduce.tasks=3
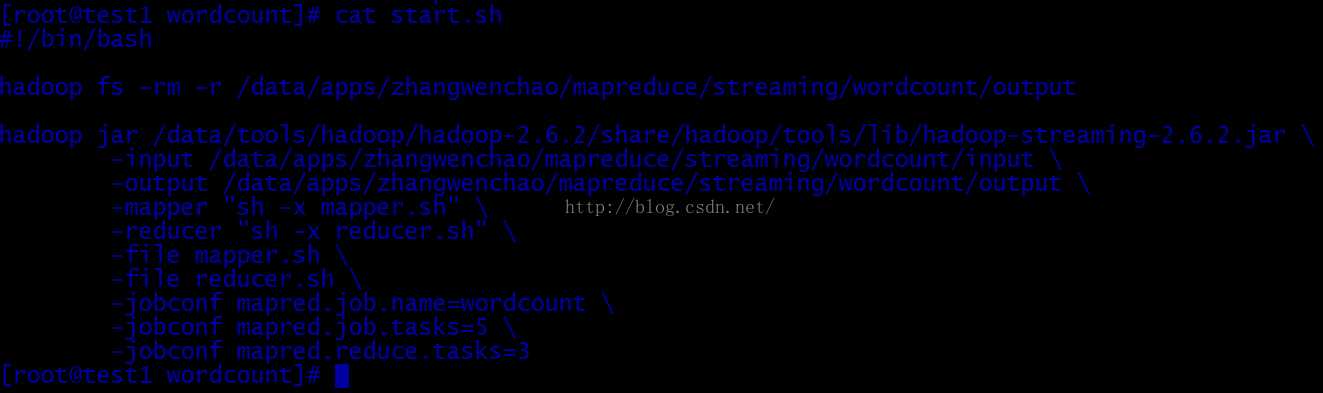
注意:输出目录不能存在,故启动任务前,删除。mapper.sh,reducer.sh文件与start.sh文件同属于当前目录下
二、Python
#!/bin/bash hadoop fs -rm -r /data/apps/zhangwenchao/mapreduce/python/wordcount/output hadoop jar /data/tools/hadoop/hadoop-2.6.2/share/hadoop/tools/lib/hadoop-streaming-2.6.2.jar -input /data/apps/zhangwenchao/mapreduce/python/wordcount/input -output /data/apps/zhangwenchao/mapreduce/python/wordcount/output -mapper "mapper.py" -reducer "reducer.py" -file mapper.py -file reducer.py -jobconf mapred.job.name=wordcount -jobconf mapred.job.tasks=5 -jobconf mapred.reduce.tasks=3
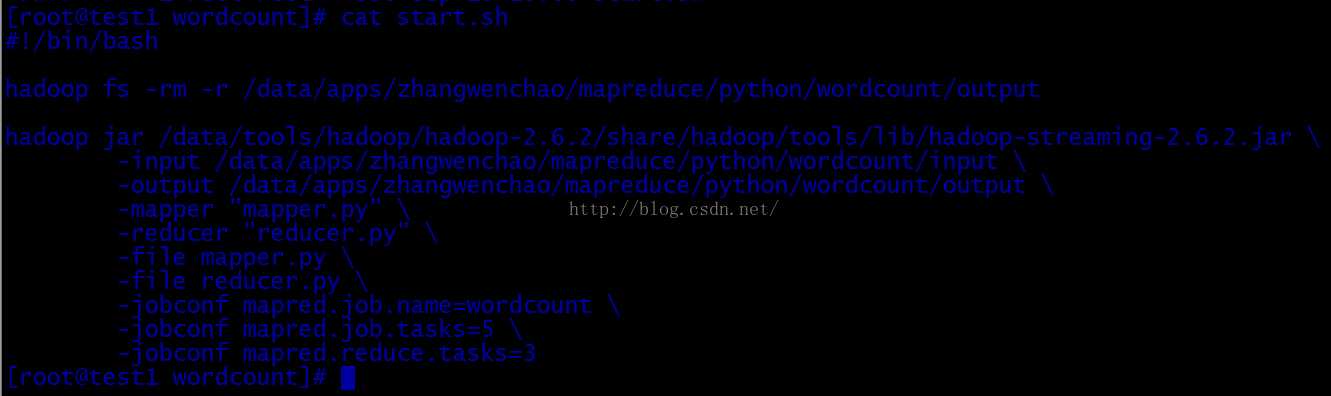
注意:输出目录不能存在,故启动任务前,删除。mapper.sh,reducer.sh文件与start.sh文件同属于当前目录下
三、Java
hadoop jar x.jar 是运行包的一种方式,完成的方式为
hadoop jar x.jar ×××.MainClassName inputPath outputPath
同时解释一下:
x.jar为包的名称,包括路径,直接写包名称,则为默认路径
×××.MainClassName为运行的类名称
inputPath为输入路径
outputPath为输出路径。
这里需要注意的是:
输入路径和输出路径,一定要对应。
我们也可以在java代码里指定输入输出路径,这里启动mapreduce任务就可以不用指定路径了
如hadoop jar wordcount.jar Main
Main函数如下:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Main { public static void main(String[] args) throws Exception { String input = "/test/zhang*/mapreduce/java/wordcount/input"; String output = "/test/zhang*/mapreduce/java/wordcount/output"; Configuration conf = new Configuration(); Job job = new Job(conf); job.setJobName("test"); job.setJarByClass(Main.class); FileInputFormat.addInputPath(job, new Path(input)); FileOutputFormat.setOutputPath(job, new Path(output)); job.setMapperClass(MyMap.class); job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setCombinerClass(MyReduce.class); job.setNumReduceTasks(3); job.waitForCompletion(true); } }
以上是关于Mapreducer任务启动的主要内容,如果未能解决你的问题,请参考以下文章
newCacheThreadPool()newFixedThreadPool()newScheduledThreadPool()newSingleThreadExecutor()自定义线程池(代码片段