MapReducer程序调试技巧(搭建伪分布式集群)
Posted dongmeima_coder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReducer程序调试技巧(搭建伪分布式集群)相关的知识,希望对你有一定的参考价值。
写过程序分布式代码的人都知道,分布式的程序是比较难以调试的,但是也不是不可以调试,对于Hadoop分布式集群来说,在其上面运行的是mapreduce程序,因此,有时候写好了mapreduce程序之后,执行结果发现跟自己想要的结果不一样,但是有没有报错,此时就很难发现问题,查找问题的方法之一就是对程序进行调试,跟踪代码的执行,找出问题的所在。那么对于Hadoop的Mapreduce是如何进行调试的呢?
毫无疑问当然是借助eclipse这个强大的工具。具体方式如下:
说明:由于公司服务器上部署的是Cloudera CDH5.4.4,在网上找了很多资料,没有发现CDH5.4.4相关的eclipse插件,这可难倒我了。网上搜索很多人有跟我一样的困境。但是在Apache Hadoop版本下就是不存在这样的问题,对于这个问题,我暂时的解决方案是在本地搭建一个伪分布式的Apache Hadoop的集群。这个伪分布式集群就是用来给我的调试程序使用。当我们当程序调试好了,再直接导入到CDH版本的工程中即可。
1、搭建Apache Hadoop的伪分布式集群,这个问题请参考如下:
http://www.cnblogs.com/ljy2013/articles/4295341.html
2、在Apache Hadoop的版本中如何编译插件?这个问题请参考如下:
http://www.cnblogs.com/ljy2013/articles/4417933.html
3、通过步骤2,我们已经可以创建Mapreduce程序了,下面实战一下。
(1)打开eclipse集成开发环境的工具
(2)安装步骤2方式,添加hadoop的安装目录。并添加Mapreduce的tools。
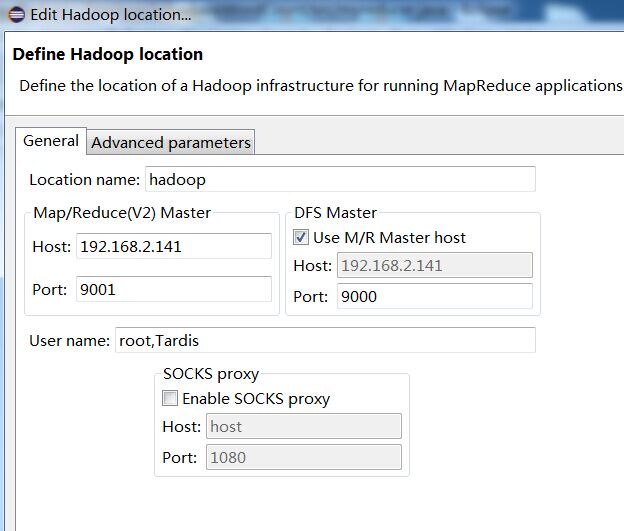
(3)编辑MapReduce tools,输入本地部署的伪分布式的集群的主机名和端口。如下图所示:
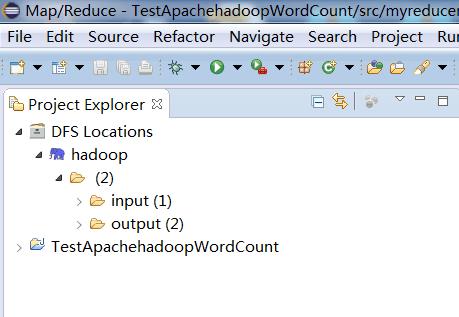
(4)此时eclipse中会出现DFS Location这样一个标识,这个表示的是Hdfs,他能加载你伪分布式集群上的hdfs的所有目录,你在这个上面操作就相当于在hdfs上面操作,前提是你拥有相应的权限。如下图所示:(你可以在这个上面很方便的删除测试文件)
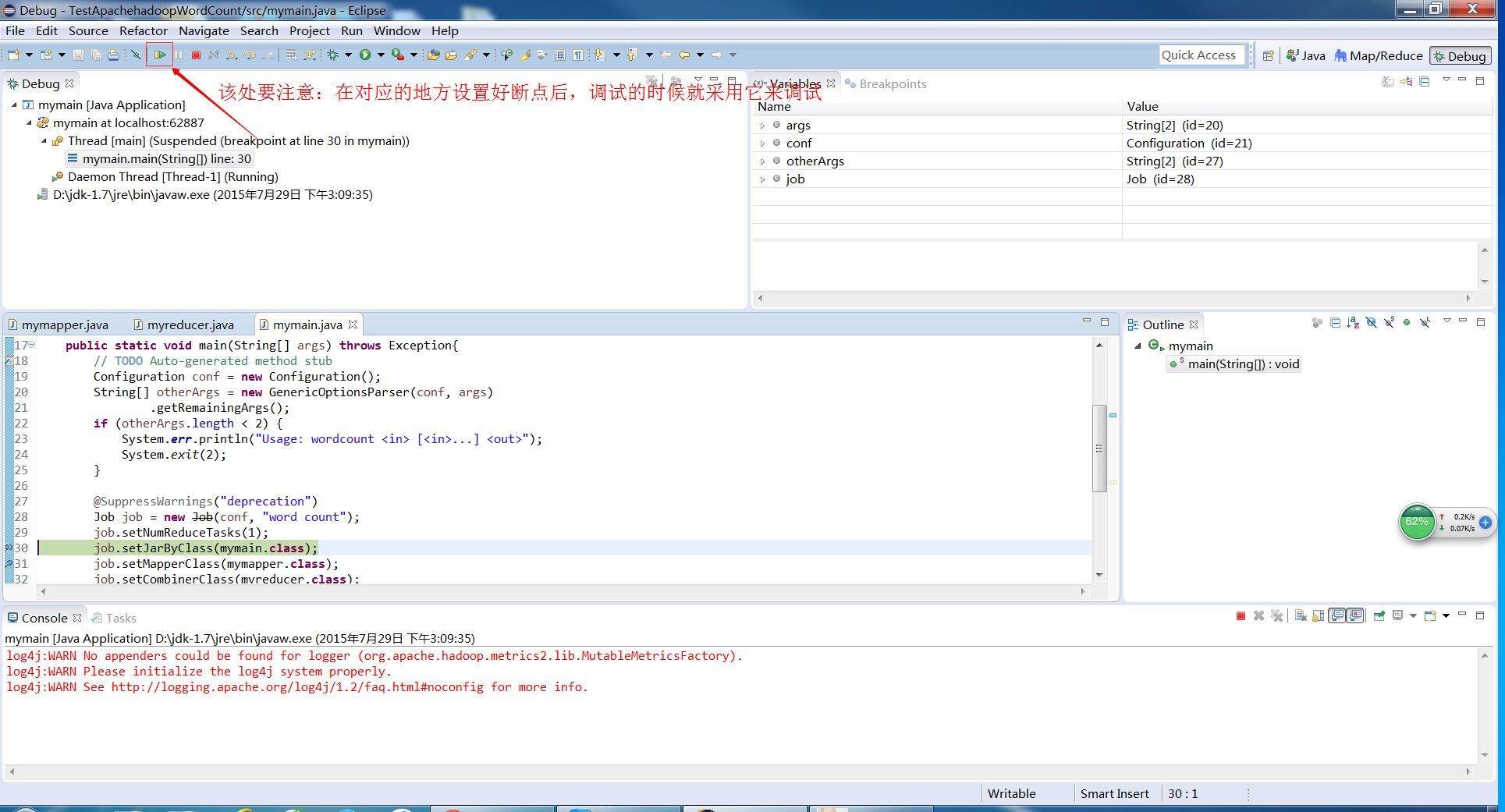
(5)编写Map/Reduce程序。在这里我们就用WordCount这个例子来调试一下。
编写好了WordCount后,单击调试,进入调试界面。如下图所示:
(6)当你一直采用上面的方式调试后,中间会让你选择添加源文件的目录,你添加一下就好了,然后姐可以进入我们的Map类中。如下图所示:
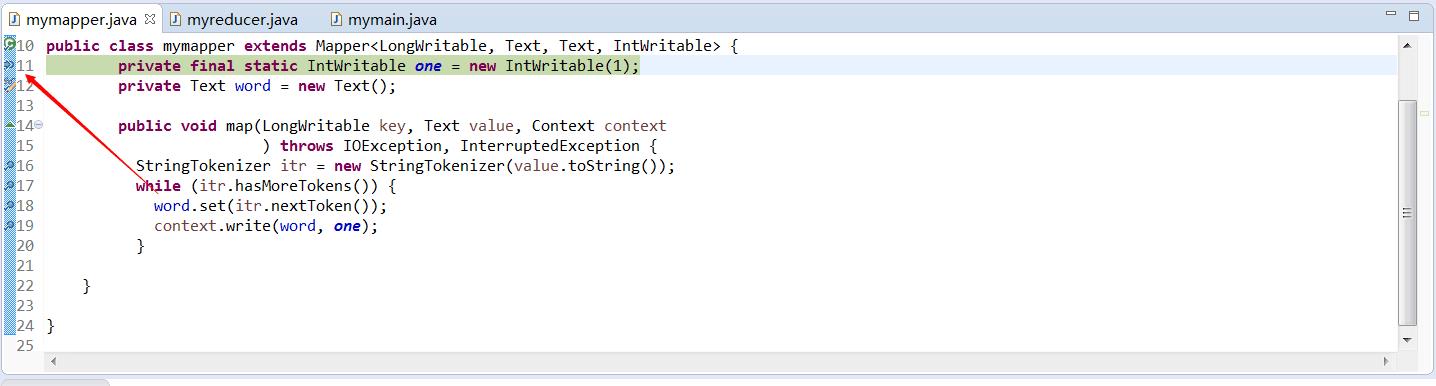
此时,你就可以观察和跟踪在map类中的map方法的执行是否正确。找出问题的根源。
(7)同样,当你在map中执行完后,接着就会进入reduce类中,这中间会敬礼一个shuffle过程。这个过程是理解MapReduce的关键所在,请参考:
http://www.cnblogs.com/ljy2013/articles/4435657.html
当你进入reduce类后,你可以看到如下图所示:
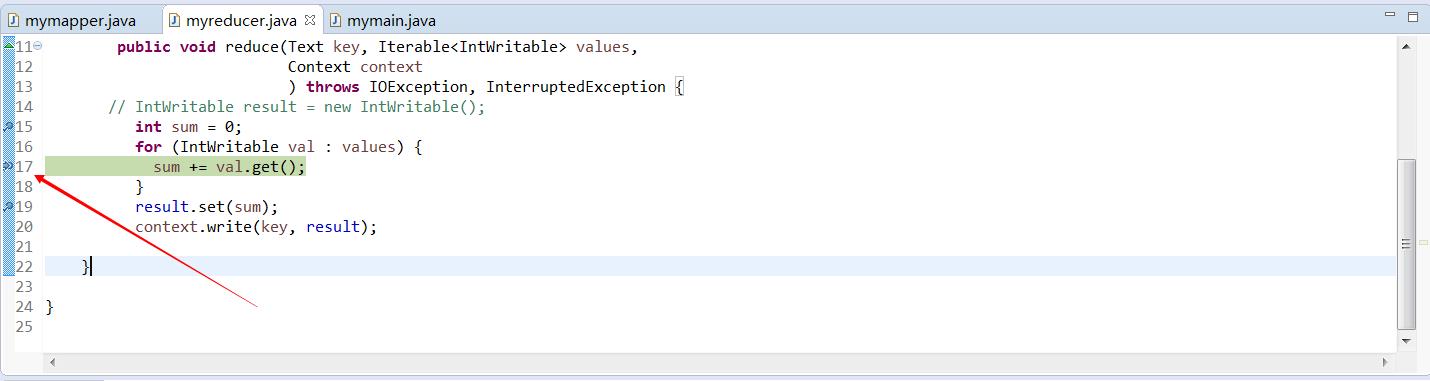
此时,你可以跟踪你的代码是否是按照你的算法思路进行。查找问题的根源。
以上是关于MapReducer程序调试技巧(搭建伪分布式集群)的主要内容,如果未能解决你的问题,请参考以下文章