MapReducer
Posted bj-xiaodao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReducer相关的知识,希望对你有一定的参考价值。
转 :https://www.cnblogs.com/firstsheng618/p/9022879.html
MapReduce是一种分布式计算模型,是Hadoop的主要组成之一,承担大批量数据的计算功能。MapReduce分为两个阶段:Map和Reduce。
一、MapReduce的架构演变
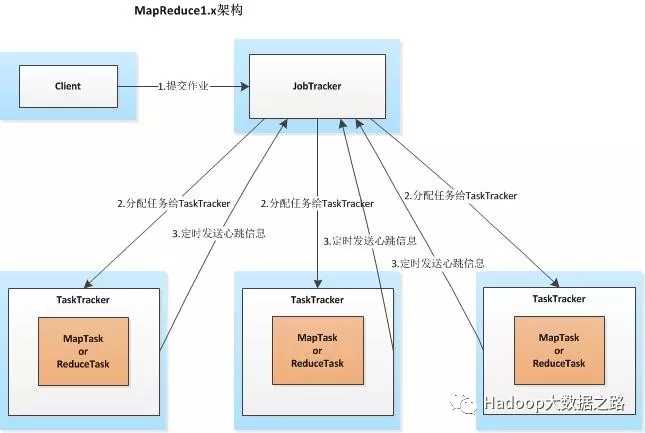
客户端向JobTracker提交一个作业,JobTracker会把这个作业拆分成多份,然后分配给TaskTracker(任务执行者)执行,TaskTracker会每隔一段时间向JobTracker发送心跳信息,如果JobTracker在一段时间内没有收到TaskTracker的心跳信息,JobTracker会认为TaskTracker挂掉,并把TaskTracker的任务分配给其它TaskTracker。该架构存在的问题:a、JobTracker节点压力过大;b、单点故障;3、只能跑MapReduce作业。
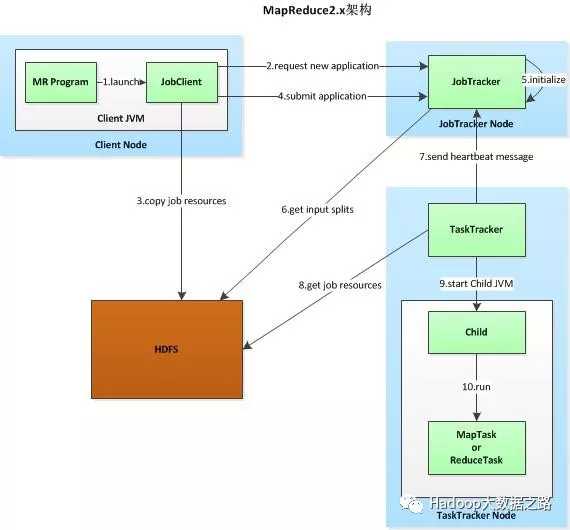
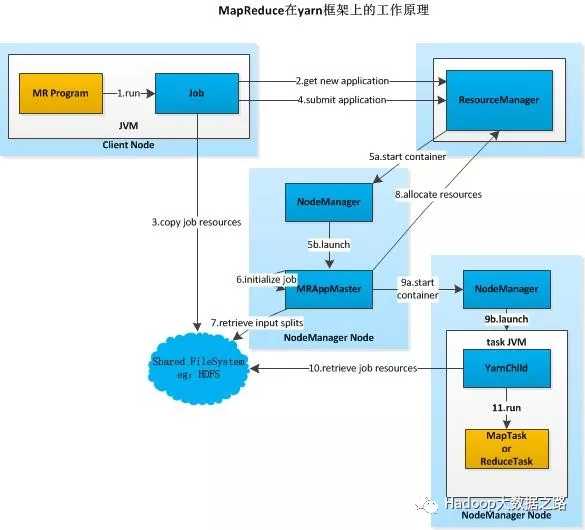
以上架构,在Hadoop版本中称为MRv2,所解决的问题:
1、更高的集群利用率,一个框架未使用的资源可由另一个框架进行使用,充分的避免资源浪费;
2、很高的扩展性;
3、yarn通过加入ApplicationMaster可变部分,可以编写不同的APPMst;
4、监控job的tasks运行情况下放到ApplicationMaster中;
二、MapReduce执行过程
1、客户端提交作业
2、JobClient与JobTracker通信,JobTracker返回一个JobID
3、JobClient复制作业资源文件
将运行作业所需要的资源赋值到HDFS上,包括MR程序打包的JAR文件、配置文件和输入划分信息。这些文件都存在JobTracker专门为该作业创建的文件夹中,文件夹名称为该作业的JobID。
4、提交任务
5、JobTracker初始化任务,创建作业对象
JobTracker接收到作业后,将其放在一个作业队列,等待作业调度器进行调度。
6、对HDFS上的资源文件进行分片,每个分片对应一个MapTask
当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行
7、TaskTracker会向JobTracker返回一个心跳信息,根据心跳信息分配任务
TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着任务进度等信息
8、TaskTracker从HDFS上获取作业资源文件
对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
9、登录到子JVM
10、TaskTracker启动一个child进程来执行具体任务
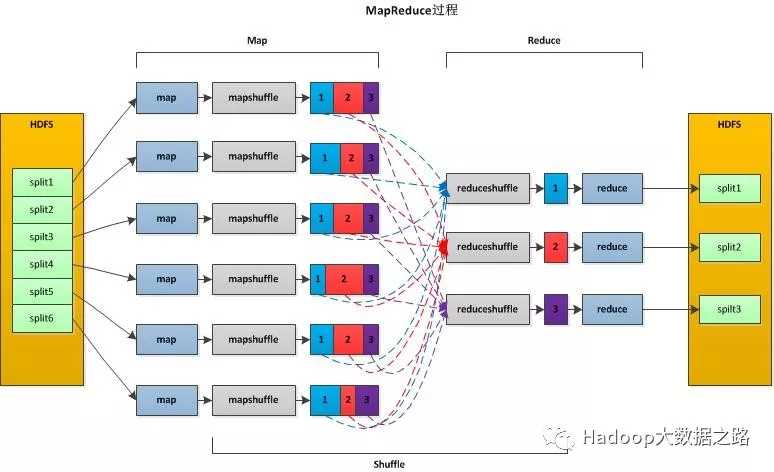
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combine操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combine操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳,所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置即可。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),当数据量超过该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作。排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
三、MR的Shuffle过程
MapReduce计算模型主要由三个阶段构成:Map、Shuffle、Reduce。Map是映射,负责数据的过滤分类,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果;为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,这个过程就是Shuffle。Shuffle过程包含Map Shuffle和Reduce Shuffle。
1)Map Shuffle
在Map端的shuffle过程就是对Map的结果进行分区、排序、分割,然后将属于同一个分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。分区有序的含义是Map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排序(默认),大致流程如下:

2)Reduce Shuffle
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(这些通知在心跳机制中进行)。所以,对于指定作业来说,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
以上是关于MapReducer的主要内容,如果未能解决你的问题,请参考以下文章