Python高级应用程序设计
Posted 冯千慧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
基于requests库抓取实习僧网站进行岗位分析
2.爬虫架构设计

受爬虫中反爬策略影响,为了能够顺利抓取不影响本机ip的情况下选择使用代理的方式进行数据的抓取。于是我将爬虫的抓取部分分为4个部分,通过这4个部分来进行数据的抓取。
3.主题式网络爬虫爬取的内容与数据特征分析
抓取不同城市的岗位要求信息进行分析。
我们目的是对北上广深杭5个城市进行岗位需求统计,来反应近些年内哪个城市发展最为迅速(发展快对于各个岗位的需求量都会增大)。
4主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)利用requests方法请求网页。
(2)利用BeautifuSoup进行网页解析,同时利用其语法获取需要的数据信息。
(3)利用循环实现翻页获取数据。
技术难点:
(1)网站的反爬策略
(2)代理访问本身的IP地址的不稳定性
(3)对数据的解析
遇到难题:
一开始我们是以Boss直聘网站进行的抓取的,但是后来发现Boss直聘网站在今年10月份更新了反爬策略。我们在抓取二级页面时,一直都是在一个等待界面。我百度了一下,又说是因为重定向的问题
会导致这样。我查阅了一些论坛,说重定向有三种,一种是在服务器中做重定向。这种方式的重定向是会返回301或302的状态码以及一个跳转连接,但是我们的返回代码是200。因此不是这个原因导致的。
第二种meta refresh,即网页中的<meta>标签声明了网页重定向的链接,这种重定向由浏览器完成。但是我在meta标签下并没有看到local这个属性,通常会有一个url在标签当中,但是我并没有找到。第三种
是js重定向,但是我们并没有学习过js,于是我多方求助,让别人帮我看了几千行的js代码,终于发现了问题所在。在js代码当中有一个z_token字段,该字段是一个随机生成的字符串,相当长。将该字段放入
cookie中便可以访问该页面。我没有找到方式获取这个字段,同时该字段有效时长仅为2分钟这就断绝了像使用headers的方法来访问。我咨询了学习前后端开发的同学,了解到因为这个字段为所及生成的,即
使使用同样的函数去生成因为不是同一次调用返回的结果也不会相同。这个问题卡住了我们很久。后续了解到selenium库可以模拟浏览器进行访问,这样就可以让浏览器自动的获取到那个字段进行访问。这样
带来的问题是抓取速度得进行限制同时我也不清楚其使用代理的方式。在查找相关资料的过程中,我发现了通过Selenium库进行模拟是,有一个字段是会提示自动化脚本的,一旦网站截取到了这个字段就依然
会被屏蔽 ,且不能通过简单覆盖消除。因为时间的问题,并不允许后续问题出现的太多,所以我们后面更换了爬取网站。不确定因素太多容易导致超出我们的预期。
在换目标网站前,我们完成了抓取方案的设计,对网页的二级页面分析完毕。由于二级页面访问问题卡了3周左右,导致项目进程缓慢,后续工作无法展开。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
二级页面:
|
1
|
<a title="上门家教对" class="title ellipsis font" href="https://www.shixiseng.com/intern/inn_5rv7tenkrczo" target="_blank" data-v-6dc0c1eb="">上门家教对</a> |
二级页面中的目标岗位详细信息都放在这样的一个a标签中,我们可以通过BeautifulSoup类的find_all方法获取到所有的这个一个a标签。对这样的一个返回参数进行迭代,迭代时对象是tag,通过使用tag[‘key’]的方式获取到其href中的三级页面标签。
三级页面:

三级页面中有多个div标签,岗位信息都在其中。我们通过BeautifulSoup方法获取每一块的标签内容,然后强转类型,通过get_text方法获取其中的字符。
这种方法就无需关注div内部的标签是否一直,获取对应的字符就可了。
三、网络爬虫程序设计(60分)
1.编程环境
我负责部分用到的是python 3.7 、pycharm、jupyter
2、同学负责部分抓取到的网页(爬取网页完整代码在后面呈现)
3、以下是我负责的部分
数据的解析
from bs4 import BeautifulSoup import requests import csv import pandas as pd import bs4 import xlwt import os # def decrypt_text(text): # 数字解密处理函数 # for key, value in mapping.items(): # text = text.replace(key, value) # return text job = [] job_position = [] money = [] education = [] time = [] sx_time = [] com_position = [] job_detail = [] company_name = [] company_desc = [] company_tags = [] company_detail = [] def chuli(path): # 下面是对页面进行解析的代码 # html = open(path, \'r\', encoding=\'utf-8\') # html = decrypt_text(html) # 对html页面进去解密 soup = BeautifulSoup(open(path, \'r\', encoding=\'utf-8\'), \'html.parser\') job = soup.find(class_=\'new_job_name\').get_text() # 获取职位名称 job_detail = soup.find(class_=\'job_detail\').get_text().replace(\'\\n\', \'\') # 获取职位描述 # \\n去掉换行, com_position = soup.find(class_=\'com_position\').get_text() # 获取工作地点 job_position = soup.find(class_=\'job_position\').get_text() # 城市 company_name = soup.find(class_=\'com-name\').get_text() # 获取公司名称 company_desc = soup.find(class_=\'com-desc\').get_text() # 获取公司介绍 company_tags = soup.find(class_=\'com-tags\').get_text().replace(\'\\n\', \' \') # 获取公司福利 company_detail = soup.find(class_=\'com-detail\').get_text().replace(\'\\n\', \' \') # 获取公司性质 # \\n用空格代替换行 money = soup.find(class_=\'job_money cutom_font\').get_text() # 获取薪资 education = soup.find(class_=\'job_academic\').get_text() # 获取学历要求 time = soup.find(class_=\'job_week cutom_font\').get_text() # 获取工作时长 sx_time = soup.find(class_=\'job_time cutom_font\').get_text() # 获取实习时间 shuju = [job, job_position, money, education, time, sx_time, com_position, job_detail, company_name, company_desc, company_tags, company_detail] return (shuju) def write_text(i, shuju, sheet): for j in range(len(shuju)): sheet.write(i, j, shuju[j]) # 将数据写入excel表 def main(): shuju = [] k = 1 # 控制第几个2级页面 n = 1 # 控制第几个3级页面 p = 1 # 控制excel中的当前行 # 以下是将数据存到excel中 workbook = xlwt.Workbook() # 定义workbook sheet = workbook.add_sheet(\'数据分析\', cell_overwrite_ok=True) # 添加sheet # 写表头 head = [\'职位名称\', \'城市\', \'薪资\', \'学历要求\', \'工作时长\', \'实习时间\', \'工作地点\', \'职位描述\', \'公司名称\', \'公司介绍\', \'公司福利\', \'公司性质\'] # 表头 write_text(0, head, sheet) while (1): n = 1 while (1): path = \'C:/Users/fqh/PycharmProjects/pachong/html3/第{}页-{}.html\'.format(k, n) # 依次读取html页面 try: open(path, \'r\', encoding=\'utf-8\') # 差错处理,当文件不存在时break except FileNotFoundError: break else: # 正常的输入数据 write_text(p, chuli(path), sheet) workbook.save(\'数据分析.xls\') p += 1 n += 1 if (n == 20): break k += 1 if (k > 250): break if __name__ == \'__main__\': # 数据解密映射 # mapping = {\'\': \'0\', \'\': \'1\', \'\': \'2\', \'\': \'3\', \'\': \'4\', # \'\': \'5\', \'\': \'6\', \'\': \'7\', \'\': \'8\', \'\': \'9\'} main()
结果

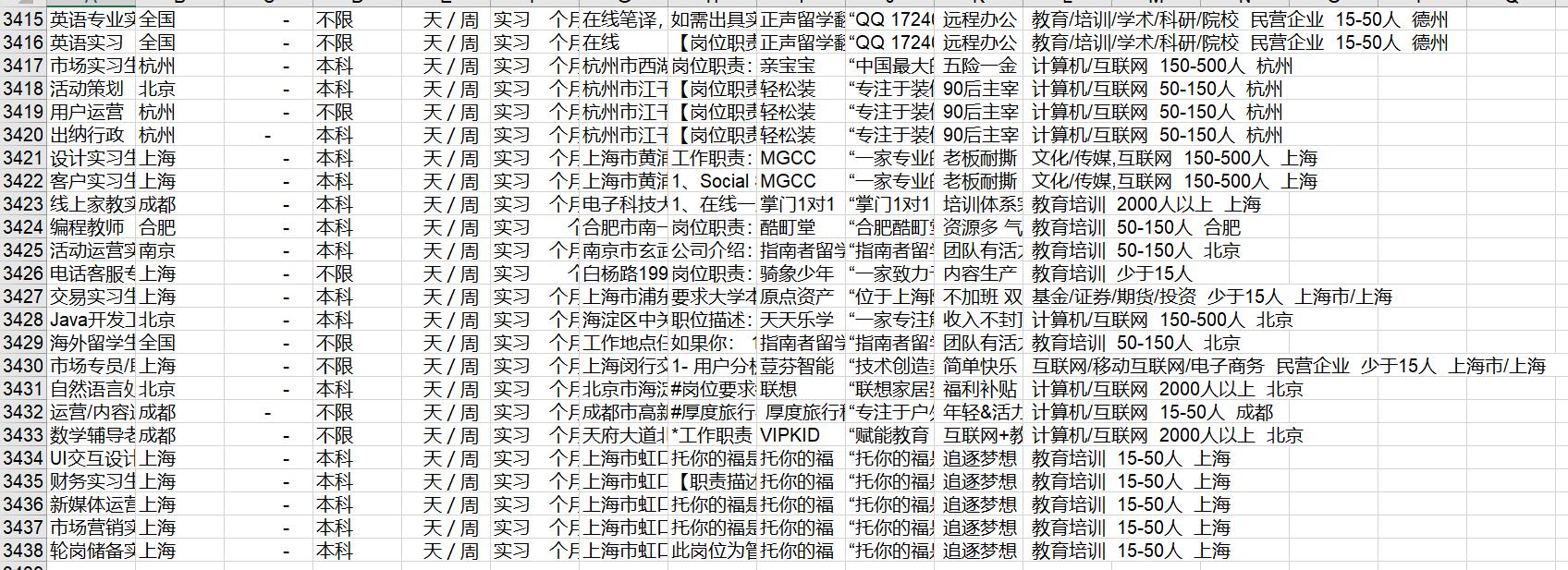
问题:因为实习僧网站有反扒策略,数据被加密,所有在文件中数据没有被显示
数据清洗
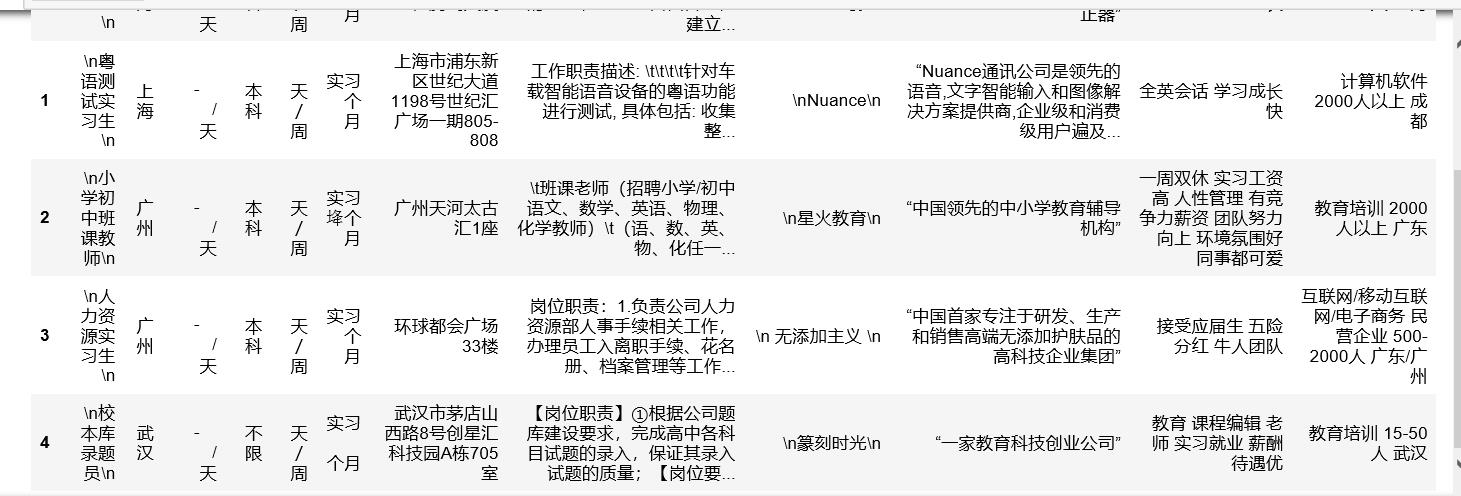
#导入excel表 import pandas as pd text=pd.DataFrame(pd.read_excel(\'数据分析.xls\')) text.head()
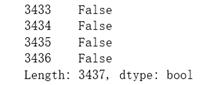
#查看重复值 text.duplicated()

#删除重复值 text=text.drop_duplicates()

#查看表的统计信息 text.describe()

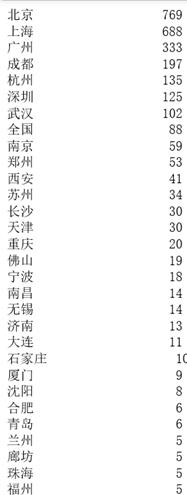
#查看每个城市的岗位数量 text[\'城市\'].value_counts()
数据可视化
#建立北上广深一线城市岗位需求的柱状图 df=pd.DataFrame([[\'北京\',\'上海\',\'广州\',\'深圳\',\'杭州\'],[771,690,335,126,136]]) df import matplotlib.pyplot as plt import numpy as np import seaborn as sns from pylab import mpl mpl.rcParams[\'font.sans-serif\'] = [\'SimHei\'] plt.figure() plt.bar([\'北京\',\'上海\',\'广州\',\'深圳\',\'杭州\'],[771,690,335,126,136]) plt.title(\'北上广深一线城市岗位需求量\') plt.savefig(\'北上广深一线城市岗位需求量图.jpg\') plt.show()

#建立软件行业在各地区的分布饼状图 city=text[\'城市\'][text[\'职位名称\'].str.contains(\'软件\')].value_counts() label=city.keys() city_list = [] count = 0 n = 1 distance = [] for i in city: city_list.append(i) #print(\'列表长度\', len(city_list)) count += 1 if count > 5: n += 0.1 distance.append(n) else: distance.append(0) plt.pie(city_list, labels=label, labeldistance=1.2, autopct=\'%2.1f%%\', pctdistance=0.6, shadow=True, explode=distance) plt.axis(\'equal\') # 使饼图为正圆形 plt.legend(loc=\'upper left\', bbox_to_anchor=(-0.1, 1)) plt.title(\'软件行业在各地区的分布\') plt.savefig(\'软件行业在各地区的分布图.jpg\') plt.show()

数据持久化

4、完整代码呈现
爬取部分(分为三个文件)
主函数
from Boss import * from Message import Message import requests if __name__ == "__main__": Boss1 = Boss() #message=Message(\'html3\') #headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362\'} #解析数据时停用 Boss1.run(250) #message.run()
IPPool
import requests import json from requests.exceptions import * #导入requests的异常库 class IPPool: i = 0 #表示当前选中地址池中的哪一个地址 def __init__(self,url,max): self.url=url #地址池要访问的地址 self.max=max #地址池的最大值 self.ipurl="http://webapi.http.zhimacangku.com/getip?num={}&type=2&pro=&city=0&yys=0&port=11&time=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=2®ions=".format(max)#获取json格式的地址资源 def set_IP(self): r=requests.get(self.ipurl) data=r.json() #对放回的json包进行解析 self.ip=data[\'data\'] self.max=5 print(self.ip) def get_IP(self): Error_flag=0 time = 10 if(len(self.ip)==0): self.set_IP() #对超出范围的值归零,使地址池变成一个循环的表 if(self.i>=self.max-1): self.i=0 #若当前地址响应时间小于1s则使用该地址否则删除该地址 while(time>9): #若地址池为空,则重新申请一次地址 if(len(self.ip)==0): self.set_IP() self.i=0 continue if(self.i>=self.max): self.set_IP() self.i=0 continue data = self.ip[self.i] print(data[\'ip\']+\':\'+str(data[\'port\'])) Ip=str(\'https://\'+data[\'ip\']+\':\'+str(data[\'port\'])) if(Ip==""): self.set_IP() self.i=0 continue proxies = {\'https\':Ip} print(proxies) #利用该地址尝试访问url try:r=requests.get(self.url,proxies=proxies) except (ProxyError,SSLError):#对遇到的代理异常做处理 del self.ip[self.i] self.max-=1 self.i+=1 if(self.i>=self.max-1): self.i=0 while(1):#直到没有异常 try:r=requests.get(self.url,proxies=proxies) except (ProxyError,SSLError): try:del self.ip[self.i] except IndexError: Error_flag=1 self.set_IP() break; else: self.max-=1 self.i+=1 if(self.i>=self.max-1): self.i=0 else :break else : if(self.i>=self.max-1): self.i=0 #得到响应的时间,单位s time=r.elapsed.total_seconds() #超时的删除 if(time>9): if(self.i<=self.max): del self.ip[self.i] self.max-=1 self.i+=1 #if(self.n>15):#防止地址失效最快的解决方案 # self.set_IP() # Error_flag==1 # self.n=0 #self.n+=1 if Error_flag==1: Error_flag=0 continue return proxies
Boos
1 import re 2 import requests 3 import json 4 from selenium import webdriver 5 from IPPool import * 6 from City import * 7 from bs4 import BeautifulSoup 8 from requests.exceptions import * 9 10 #针对实习僧的爬取类 11 class Boss: 12 num=0 13 #设置user-agent 14 headers = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362\',} 15 url="https://www.shixiseng.com/" 16 #初始化,设置url及筛选条件 17 def __init__(self): 18 #对地址池进行初始化 19 self.ippool=IPPool(self.url,5) 20 self.ippool.set_IP() 21 #设置登陆账号 22 def login(admin,passwd): 23 self.admin=admin 24 self.passwd=passwd 25 #请求页面方法,返回一个response 26 def Get_1(self,href): 27 Error_flag=1 28 while(Error_flag): 29 Error_flag=0 30 proxies = self.ippool.get_IP() 31 try:response = requests.get(href,headers=self.headers,proxies=proxies) 32 except (ProxyError,SSLError): 33 Error_flag=1 34 else: 35 #response = brower.get(self.url) 36 print(response.status_code) 37 return response.content.decode() 38 #保存html字串 39 def save_html(self,html_str,file_path): 40 with open(file_path,"w",encoding="utf-8")as f: 41 f.write(html_str) 42 self.num+=1 43 44 #对标签进行截取函数 45 def get_tap(self,tag,key,name,soup1): 46 for j in soup1.find_all(tag,class_=name): 47 if(j[key]==name): 48 message = BeautifulSoup(str(j)) 49 return message 50 #运行爬虫 51 def run(self,MAX): 52 k=250 53 n=1 54 message={} 55 buf=\'\' 56 response = self.Get_1("https://www.shixiseng.com/interns?page=1&keyword=&type=intern&area=&months=&days=°ree=%E6%9C%AC%E7%A7%91&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%85%A8%E5%9B%BD&internExtend=")#获取到了页面的HTML代码 57 if(k>MAX): 58 return 0 59 file_path2 = \'data\\{}.html\'.format(k)#存放二级页面 60 with open(file_path2,"w",encoding = \'utf-8\' ) as f: 61 f.write(response) 62 soup = BeautifulSoup(open(file_path2,\'r\',encoding=\'utf-8\')) 63 print(soup.get_text) 64 message1=BeautifulSoup(str(soup.find_all("div",id="__layout"))) 65 message2=BeautifulSoup(str(message1.find_all("div",class_="interns"))) 66 message3=BeautifulSoup(str(message2.find_all("div",class_="result-list clearfix"))) 67 message4=BeautifulSoup(str(message3.find_all("div",class_="primary-content f-l"))) 68 message5=BeautifulSoup(str(message4.find_all("div",style="display:;"))) 69 message=message5.find_all("a",class_="title ellipsis font") 70 for j in message: 71 print(j[\'href\']) 72 file_path3 = \'html3\\第{}页-{}.html\'.format(k,n) 73 buf=j[\'href\'] 74 r=self.Get_1(buf) 75 self.save_html(r,file_path3) 76 n+=1 77 while(k<MAX): 78 k+=1 79 n=1 80 message={} 81 buf=\'\' 82 tag_url="https://www.shixiseng.com/interns?page={}&keyword=&type=intern&area=&months=&days=°ree=%E6%9C%AC%E7%A7%91&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E5%85%A8%E5%9B%BD&internExtend=".format(k) 83 response = self.Get_1(tag_url)#获取到了页面的HTML代码 84 if(k>=MAX): 85 return 0 86 file_path2 = \'data\\{}.html\'.format(k)#存放二级页面 87 with open(file_path2,"w",encoding = \'utf-8\' ) as f: 88 f.write(response) 89 soup = BeautifulSoup(open(file_path2,\'r\',encoding=\'utf-8\')) 90 message1=BeautifulSoup(str(soup.find_all("div",id="__layout"))) 91 message2=BeautifulSoup(str(message1.find_all("div",class_="interns"))) 92 message3=BeautifulSoup(str(message2.find_all("div",class_="result-list clearfix"))) 93 message4=BeautifulSoup(str(message3.find_all("div",class_="primary-content f-l"))) 94 message5=BeautifulSoup(str(message4.find_all("div",style="display:;"))) 95 message=message5.find_all("a",class_="title ellipsis font") 96 for j in message: 97 file_path3 = \'html3\\第{}页-{}.html\'.format(k,n) 98 buf=j[\'href\'] 99 r=self.Get_1(buf) 100 self.save_html(r,file_path3) 101 n+=1
数据解析
from bs4 import BeautifulSoup import requests import csv import pandas as pd import bs4 import xlwt import os # def decrypt_text(text): # 数字解密处理函数 # for key, value in mapping.items(): # text = text.replace(key, value) # return text job = [] job_position = [] money = [] education = [] time = [] sx_time = [] com_position = [] job_detail = [] company_name = [] company_desc = [] company_tags = [] company_detail = [] def chuli(path): # 下面是对页面进行解析的代码 # html = open(path, \'r\', encoding=\'utf-8\') # html = decrypt_text(html) # 对html页面进去解密 soup = BeautifulSoup(open(path, \'r\', encoding=\'utf-8\'), \'html.parser\') job = soup.find(class_=\'new_job_namePython高级应用程序设计