Python高级应用程序设计
Posted 拾荒者04
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
名称:爬取视频网站中的电影排名信息
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取各个视频网站中的电影排名以及评分
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案主要依靠request库对目标页面进行信息的爬取采集,再用BeautifulSoup对数据进行清洗,最后将结果打印出来。技术难点主要包括对数据的清洗以及对打印结果的排版。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
以爱奇艺电影频道为例,
2.Htmls页面解析
(1)通过在浏览器中用鼠标右键点击查看“查看元素”选项或者按“F12”打开网页源代码。
(2)用requests.get(url)命令向服务器提交请求,然后将响应的网页信息交由BeautifulSoup解析,提取出HTML结构和源代码,最后用soup.prettify()方法输出源码。

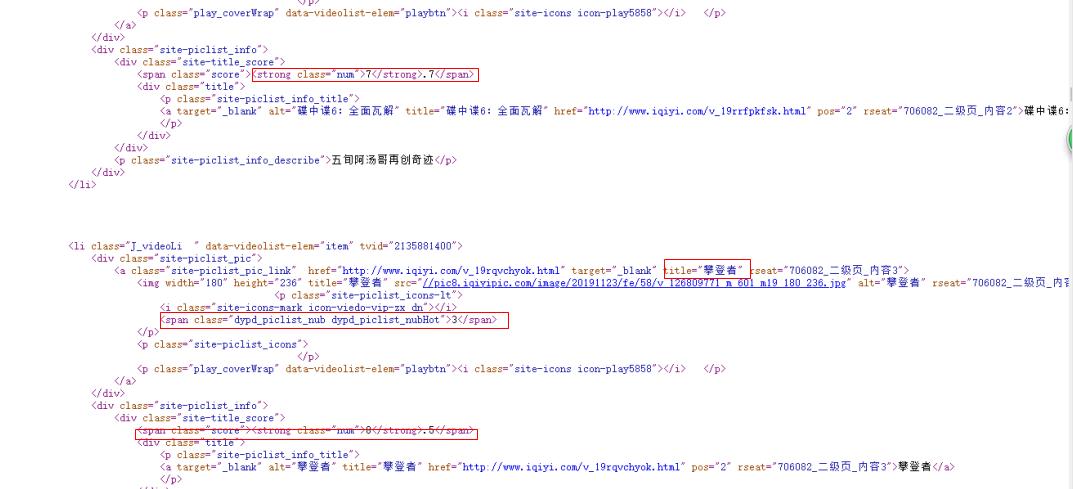
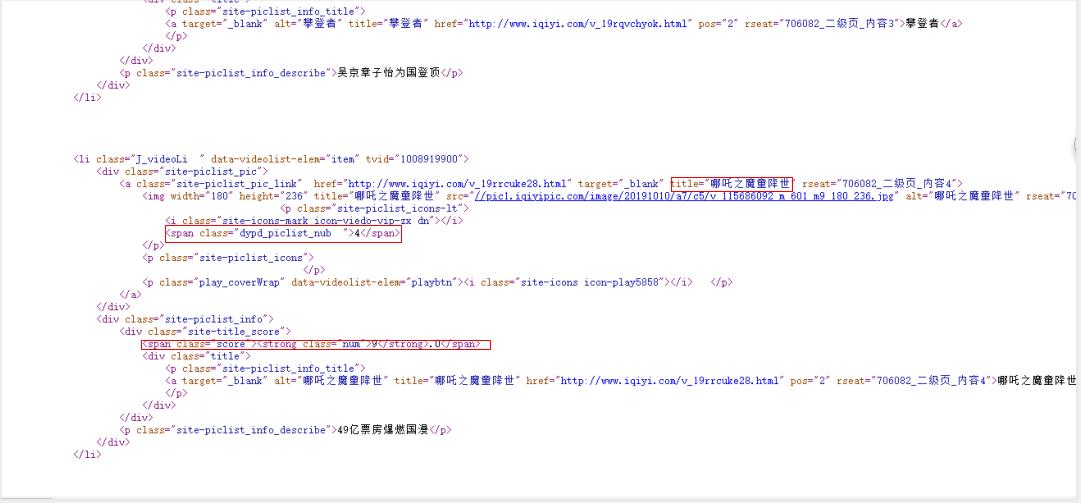
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法find_all()
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
程序代码:
(必要时画出节点树结构)
查找方法find_all()
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
程序代码:
import requests from bs4 import BeautifulSoup #数据存储 import pandas as pd #导入requests库 从bs4库中调用BeautifulSoup #爬取爱奇艺电影频道目标的HTML页面 def getHTMLText(url): try: #用requests抓取网页信息,请求超时时间为60秒 r = requests.get(url,timeout=60) #如果状态码不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding = r.apparent_encoding return r.text except: return "爬取失败" #解析电影名称并电影名称组成数组返回 def getMovie(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的p标签,从中获取到电影的名称 for p in soup.find_all("p","site-piclist_info_title"): ulist.append(p.a.string) return ulist # 获取电影评分 def getPage1(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的div标签,从中获取到电影的评分 for div in soup.find_all("div","site-title_score"): ulist.append(div.span.strong.string) return ulist def getPage2(ulist,html): soup = BeautifulSoup(html,"html.parser") u = [] for div in soup.find_all("div","site-title_score"): ulist.append(list(div.span)) return ulist #打印电影信息函数 def printUnivList(ulist1,ulist2,ulist3,num): print("{:^50}".format("电影名称及评分")) for i in range(num): print("{:^45}\\t\\t{}{}".format(ulist1[i],ulist2[i],ulist3[i])) # 写入excel文件中 def savedata(html, filename,m,p1,p3): movies = [] for i in range(len(p1)): try: # print(p1[i]+p3[i]) score = p1[i]+p3[i] movies.append([getMovie(m, html)[i], score]) except: "" # print(movis) pf = pd.DataFrame(movies, columns=["movie_name", "score"]) writer = pd.ExcelWriter(filename) pf.to_excel(writer, sheet_name="movies") writer.save() def main(): # 保存路径 filename = "movie-boxoffice.xlsx" # 爬取页面url地址 Url = "https://www.iqiyi.com/dianying_new/i_list_paihangbang.html" #创建一个数组m用来存放爬取到的电影名称 m = [] #创建2个数组分别存储电影评分的个位部分的数值以及小数点后的数值 p1 = [] p2 = [] #创建一个数组P3将p1和p2的数据进行合并处理 p3 = [] #获取到HTML页面信息 html = getHTMLText(Url) #获取到电影名称 m = getMovie(m, html) #获取到电影评分 p1 = getPage1(p1, html) p2 = getPage2(p2, html) #将p1和p2的信息合并存储到p3 for i in range(len(p2)): p3.append(p2[i][1]) #打印所有爬取到的电影信息 printUnivList(m, p1, p3, len(m)) # 数据持久化到excel savedata(html, filename,m,p1,p3) main()
运行结果:
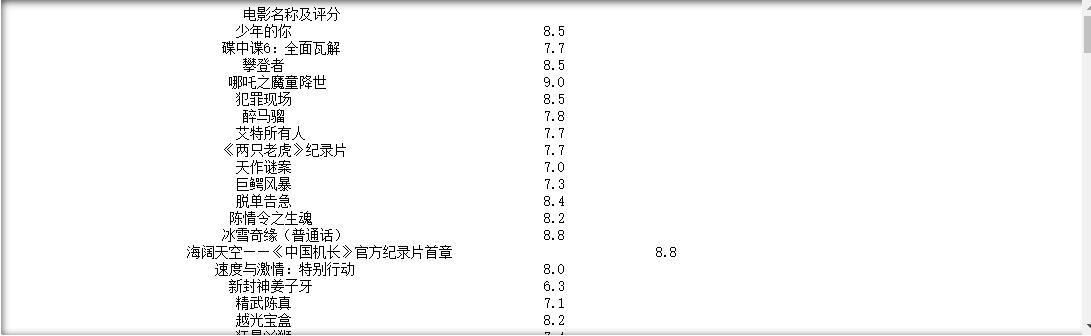
使用request库进行爬取数据
#爬取爱奇艺电影频道目标的HTML页面 def getHTMLText(url): try: #用requests抓取网页信息,请求超时时间为60秒 r = requests.get(url,timeout=60) #如果状态码不是200,则引发异常 r.raise_for_status() #配置编码 r.encoding = r.apparent_encoding return r.text except: return "爬取失败"
2.对数据进行清洗和处理
用BeautifulSoup 库进行数据清洗
#解析电影名称并电影名称组成数组返回 def getMovie(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的p标签,从中获取到电影的名称 for p in soup.find_all("p","site-piclist_info_title"): ulist.append(p.a.string) return ulist # 获取电影评分 def getPage1(ulist,html): soup = BeautifulSoup(html,"html.parser") #用find_all方法从HTML页面中所有的div标签,从中获取到电影的评分 for div in soup.find_all("div","site-title_score"): ulist.append(div.span.strong.string) return ulist def getPage2(ulist,html): soup = BeautifulSoup(html,"html.parser") u = [] for div in soup.find_all("div","site-title_score"): ulist.append(list(div.span)) return ulist #打印电影信息函数 def printUnivList(ulist1,ulist2,ulist3,num): print("{:^50}".format("电影名称及评分")) for i in range(num): print("{:^45}\\t\\t{}{}".format(ulist1[i],ulist2[i],ulist3[i])) # 写入excel文件中 def savedata(html, filename,m,p1,p3): movies = [] for i in range(len(p1)): try: # print(p1[i]+p3[i]) score = p1[i]+p3[i] movies.append([getMovie(m, html)[i], score]) except: "" # print(movis) pf = pd.DataFrame(movies, columns=["movie_name", "score"]) writer = pd.ExcelWriter(filename) pf.to_excel(writer, sheet_name="movies") writer.save() def main(): # 保存路径 filename = "movie-boxoffice.xlsx" # 爬取页面url地址 Url = "https://www.iqiyi.com/dianying_new/i_list_paihangbang.html" #创建一个数组m用来存放爬取到的电影名称 m = [] #创建2个数组分别存储电影评分的个位部分的数值以及小数点后的数值 p1 = [] p2 = [] #创建一个数组P3将p1和p2的数据进行合并处理 p3 = [] #获取到HTML页面信息 html = getHTMLText(Url) #获取到电影名称 m = getMovie(m, html) #获取到电影评分 p1 = getPage1(p1, html) p2 = getPage2(p2, html) #将p1和p2的信息合并存储到p3 for i in range(len(p2)): p3.append(p2[i][1]) #打印所有爬取到的电影信息 printUnivList(m, p1, p3, len(m)) # 数据持久化到excel savedata(html, filename,m,p1,p3) main()
3.文本分析(可选):jieba分词、wordcloud可视化
#encoding=utf-8 from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba file_object = open(r\'C:\\Users\\lenovo\\Desktop\\琐屑\\a\') #不要把open放在try中,以防止打开失败,那么就不用关闭了 try: file_context = file_object.read() #file_context是一个string,读取完后,就失去了对test.txt的文件引用 finally: file_object.close() #print(file_context) seg_list = jieba.cut_for_search(file_context)# 搜索引擎模式 #print(list(seg_list)) #print(" ".join(seg_list)) # 设置词云 wc = WordCloud( # 设置背景颜色 background_color="black", # 设置最大显示的词云数 max_words=2000, # 这种字体都在电脑字体中,一般路径 font_path=\'C:\\Windows\\Fonts\\simfang.ttf\', height=1200, width=1600, # 设置字体最大值 max_font_size=100, # 设置有多少种随机生成状态,即有多少种配色方案 random_state=30, ) myword = wc.generate(" ".join(seg_list)) # 生成词云 # 展示词云图 plt.imshow(myword) plt.axis("off") plt.show() wc.to_file(\'C://Users//123//Desktop//p.png\') # 把词云保存下
结果图:

4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
散点图:
import matplotlib.pyplot as plt plt.rcParams[\'font.sans-serif\']=[\'SimHei\'] #用来正常显示中文标签 plt.rcParams[\'axes.unicode_minus\']=False #用来正常显示负号 # 设置圆点大小 size = 100 getMovie = [\'少年的你\',\'碟中谍6:全面瓦解\',\'攀登者\',\'哪吒之魔童降世\',\'犯罪现场\',\'醉马骝\',\'艾特所有人\',\'《两只老虎》纪录片\',\'天作谜案\',\'巨鳄风暴\'] p3 = [\'8.5\',\'7.7\',\'8.5\',\'9.0\',\'8.5\',\'7.8\',\'7.7\',\'7.7\',\'7.0\',\'7.3\'] # 绘制散点图, alpha=0.5表示透明度 plt.scatter(getMovie,p3, color="r", alpha=0.5, marker=\'o\') plt.xlabel("getMovie") plt.ylabel("p3") plt.title("电影排名及评分的散点图") plt.grid() # 添加网格 plt.show()

结论:由散点图分析可得电影的排名及评分之间不存在相关性。
饼图:
import matplotlib.pyplot as plt
Type = [\'9分及以上\', \'8分以上9分以下\', \'7分以上8分以下\', \'6分以上7分以下\'] Data = [1, 8, 8, 1] #cols = [\'r\',\'g\',\'y\',\'coral\'] #绘制饼图 plt.pie(Data ,labels=Type, autopct=\'%1.1f%%\') #设置显示图像为圆形 plt.axis(\'equal\') plt.title(\'各评分所占的比重\') plt.show()
运行结果:

plt.bar([\'6分以上7分以下\',\'7分以上8分以下\',\'8分以上9分以下\',\'9分及以上\'], [1, 8, 8, 1], label="各评分所占比重") plt.legend() plt.show()
运行结果: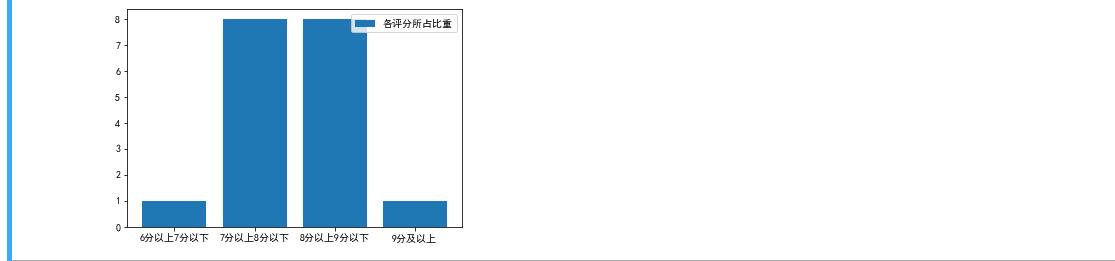
5.数据持久化
# 写入excel文件中 def savedata(html, filename,m,p1,p3): movies = [] for i in range(len(p1)): try: # print(p1[i]+p3[i]) score = p1[i]+p3[i] movies.append([getMovie(m, html)[i], score]) except: "" # print(movis) pf = pd.DataFrame(movies, columns=["movie_name", "score"]) writer = pd.ExcelWriter(filename) pf.to_excel(writer, sheet_name="movies") writer.save()
运行结果:
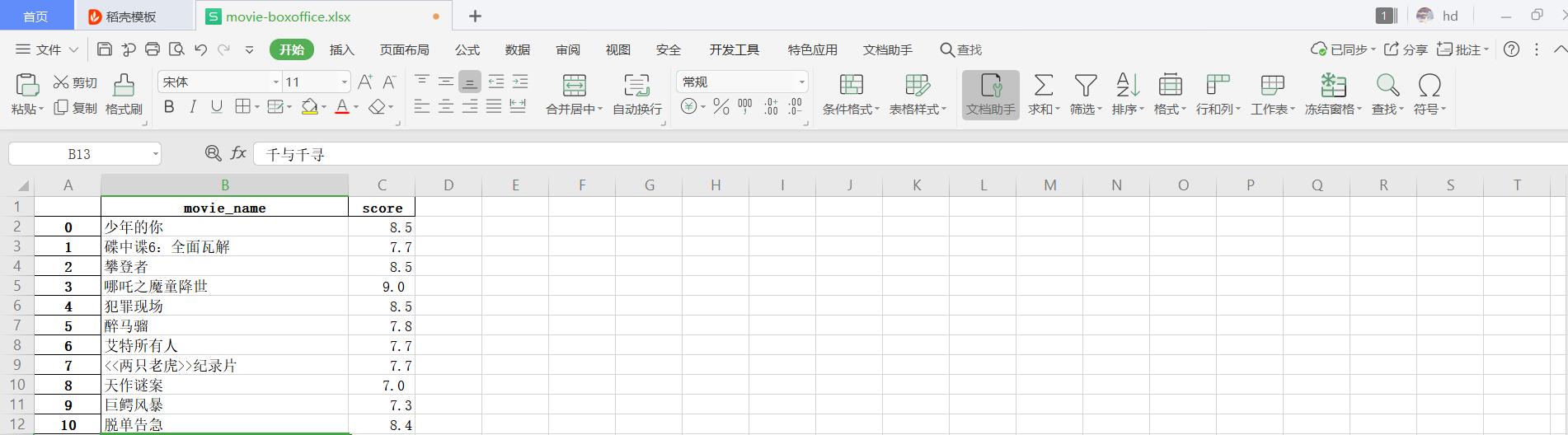
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对主题数据的分析与可视化,可以得到电影的排名信息以及各自的评分
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次任务,基本实现把想要的数据爬取下来,以及对其进行数据清洗及分析。
这次实验同样存在不足之处,爬取下来的数据排版问题没有得到好的解决,所以仍需继续努力学习,不断提升自己的能力,完善自我,解决遇到的所有问题。
以上是关于Python高级应用程序设计的主要内容,如果未能解决你的问题,请参考以下文章