Python高级应用程序设计任务
Posted 人暖我不知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取好123旅游攻略
2.主题式网络爬虫爬取的内容与数据特征分析
景点、价格、位置、累计售票、顾客满意度、顾客点评、售票预定时间
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:通过链接获取网页页面,再通过正则获取所需数据。
技术难点:该网站没有反爬
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
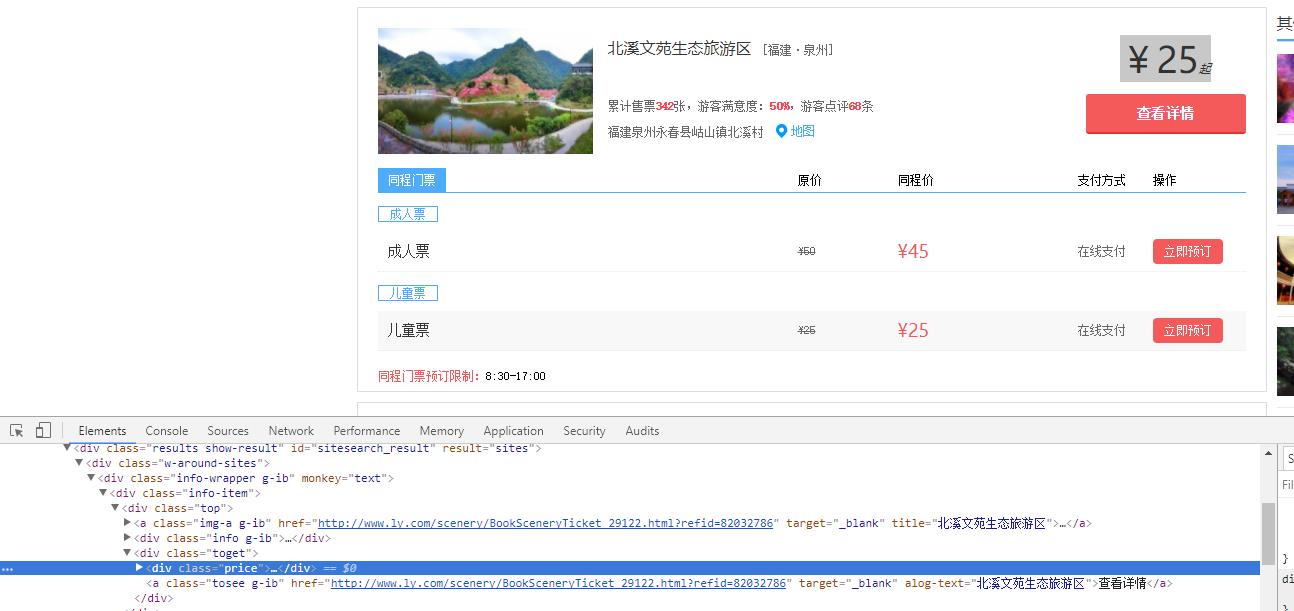
2.Htmls页面解析

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
import requests import re import pandas as pd def get_html(url): \'\'\' 定义一个获取网页的函数 \'\'\' try: hed = { \'User-Agent\': \'Mozilla/5.0\', } r = requests.get(url,headers = hed) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return \'爬取失败\' url = \'https://go.hao123.com/ticket\' html = get_html(url) # 获取url链接 city_url = r\'data-option="city" data-val=".*?">(.*?)</a>\' city_list = re.findall(city_url,html) new_city = [] for i in city_list: new_city.append(\'https://go.hao123.com/ticket?search=\' + i) # 使用pandas储存数据 pd.set_option(\'display.unicode.ambiguous_as_wide\', True) pd.set_option(\'display.unicode.east_asian_width\', True) column = [\'景点\',\'价格\',\'位置\',\'累计售票\',\'游客满意度(%)\',\'游客点评(条)\',\'门票预订时间\'] s1 = pd.DataFrame(columns=column) # 逐个页面获取数据 x = 0 for new_url in new_city: html = get_html(new_url) # 获取景点名 req1 = r\'<a class="title g-ib g-tover" href=".*?" target="_blank">(.*?)<span class="small">\' data1 = re.findall(req1,html) # <div class="des g-tover">累计售票<em>342</em>张,游客满意度:<em>50%</em>,游客点评<em>68</em>条</div> req2 = r\'<div class="des g-tover">累计售票<em>(.*?)</em>张,游客满意度:<em>(.*?)</em>,游客点评<em>(.*?)</em>条</div>\' data2 = re.findall(req2,html) # 获取景点地点 req_pla = r\'<div class="address" title=\\\'.*?\\\'>(.*?)<a href="\' data_pla = re.findall(req_pla,html) # 获取票价 req_pri = r\'<div class="price">¥(.*?)<i class="smaller">起</i></div>\' data_pri = re.findall(req_pri,html) # 获取售票时间 re_time = r\'<div class="site-footer g-tover" title=".*?[\\r\\n]?.*?"><em class="limit">(.*?)</em>(.*?)[\\r\\n]?(.*?)</div>\' data_time = re.findall(re_time,html) for i in range(len(data1)): s1 = s1.append({\'景点\':data1[i],\'价格\':data_pri[i],\'位置\':data_pla[i],\'累计售票\':data2[i][0],\'游客满意度(%)\':data2[i][1],\'游客点评(条)\':data2[i][2],\'门票预订时间\':data_time[i]}, ignore_index=True) print(\'保存{}成功\'.format(city_list[x])) x += 1 # 在本地,将数据保存成xls格式 s1.to_excel(\'旅游网1.xls\') if x == len(city_list): break
2.对数据进行清洗和处理
import requests import pandas as pd import matplotlib.pyplot as plt # 可视化时能显示中文 plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # pandas不能对齐,要设置pandas的参数 pd.set_option(\'display.unicode.ambiguous_as_wide\', True) pd.set_option(\'display.unicode.east_asian_width\', True) # 显示所有的行和列,并设置value的显示长度为100 pd.set_option(\'display.max_columns\', 100) pd.set_option(\'display.max_rows\', 100) pd.set_option(\'max_colwidth\',100) # 使pandas打印出来不会换行 pd.set_option(\'display.width\',500) # 读取excel中的内容,并保存到df中 # Tourism website tw = pd.read_excel(\'旅游网1.xls\') tw.name = \'旅游网\' # 查看数据前五行 print(tw.head())

# 删除无用的列 tw = tw.drop(\'Unnamed: 0\',axis=1)
#查找是否有重复值 print(tw.duplicated())
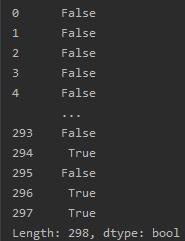
# 把重复值删除,并在进行查看删除后的结果 tw = tw.drop_duplicates() print(tw.duplicated())
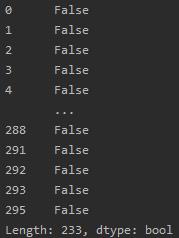

# 查看价格是否有空值或缺失值 print(tw[\'价格\'].isnull().value_counts())

3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
# 通过选取含有特殊值的列来删除带有异常值的行 tw = tw[~tw[\'景点\'].isin([\'{{$value.title}}\'])]
# 查看位置的信息 print(tw[\'位置\'].value_counts())

# 查看游客满意度信息 print(tw[\'游客满意度(%)\'].value_counts())

# 查看点评最多的前15个景点 print(tw.sort_values(\'游客点评(条)\',ascending=False).head(15)[\'景点\'])
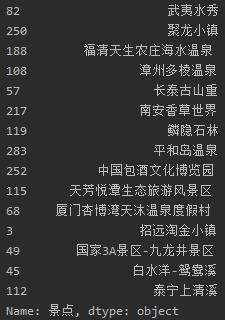
# 查看价格前15的景点 print(tw.sort_values(\'价格\',ascending=False).head(15)[\'景点\'])
# 搜索所有景点名称 xyf = [] for i in tw[\'景点\']: xyf.append(i) xyf_series = pd.Series(xyf).drop_duplicates() # 打印前10个 print(xyf_series.head(10))

# 满意度和价格的分布情况 # plt.scatter(tw[\'游客满意度(%)\'],tw[\'价格\']) # plt.show()

# 游客满意度和价格的柱状图 a = tw[\'游客满意度(%)\'] b = tw[\'价格\'] plt.bar(a,b) plt.xlabel(\'游客满意度(%)\') plt.ylabel(\'价格\') plt.show()

(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化
# 数据持久化 # s1.to_excel(\'旅游网1.xls\')
6.附完整程序代码
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)景区的价格基本不影响大家的满意度
(2)大多数景区价格都在三位数
(3)满意度55%的占过半数
2.对本次程序设计任务完成的情况做一个简单的小结。
刚开始对爬虫没有多上心,认为可以随便完成。但是等到实际上手操作时才发现自己天真了。并且自己当初选的网站有着反爬处理,自己尽管通过努力,任然没有攻破难题,最终无奈更改爬的网站,这是一个非常大的打击,因为自己的无知,同时对知识掌握的不够,向现实屈服。
但是通过本次作业自己还是学到很多新知识,自己得到了一定的进步,更加期待未来。
以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章