Python高级应用程序设计任务
Posted LZLOO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用程序设计任务相关的知识,希望对你有一定的参考价值。
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取QQ音乐歌手歌曲信息。
2.主题式网络爬虫爬取的内容与数据特征分析
爬取QQ音乐歌手具体歌曲名称。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
requests库对目标页面进行爬取,从QQ音乐页面提取url,目标数据是json数据类型,使用xlwt将数据存入.xls文件,pandas读取文件数据。用BeautifulSoup对数据进行采集,最后打印结果。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&remoteplace=txt.yqq.album&t=8&p={num}&n=5&w={singer}&format=json
在{}内填入页码和歌手名获取专辑列表
https://y.qq.com/n/yqq/album/{}.html
在{}内填入专辑mid,获取歌曲列表
2.Htmls页面解析
2.Htmls页面解析
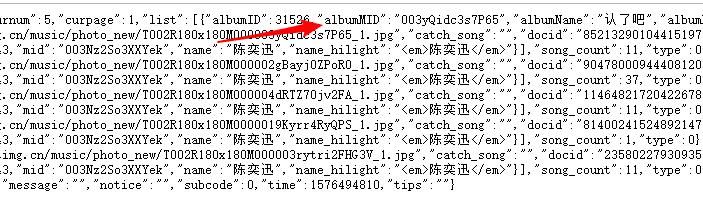

3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
for span in soup.find_all("span", attrs="songlist__songname_txt"):
for song in albumlist:
albumMid = song[\'albumMID\']
all_albummid.append(albumMid)
return all_albummid
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
所有源代码如下所示:
import requests from bs4 import BeautifulSoup import json import xlwt import pandas as pd #爬取页面函数 def catchhtml(url): kv = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36\'} #异常判断 try: data = requests.get(url, headers=kv, timeout=10) #查看状态码,判断爬取状态 data.raise_for_status() data.encoding = data.apparent_encoding #返回页面 return data.text except: return "爬取失败" #获取专辑 def getalbum(times, singer): all_albummid = [] for num in range(1, times): #获取信息的目标url url = f\'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&remoteplace=txt.yqq.album&t=8&p={num}&n=5&w={singer}&format=json\' html = catchhtml(url) # 解析json数据 js = json.loads(html) # 定位albumMID albumlist = js[\'data\'][\'album\'][\'list\'] for song in albumlist: albumMid = song[\'albumMID\'] all_albummid.append(albumMid) return all_albummid #获取专辑内的歌曲名 def getsong(albumlist): songs = [] for i in albumlist: html = catchhtml(f\'https://y.qq.com/n/yqq/album/{i}.html\') #bs4格式化html页面 soup = BeautifulSoup(html, "html.parser") #遍历span标签内a标签的字符串 for span in soup.find_all("span", attrs="songlist__songname_txt"): #将字符串放进列表 songs.append(str(span.a.string).strip()) return songs #将数据存入文件 def write_file(data, saveurl): # 创建Workbook,相当于创建Excel book = xlwt.Workbook(encoding=\'utf-8\') # 创建sheet,Sheet1为表的名字,cell_overwrite_ok为是否覆盖单元格 sheet1 = book.add_sheet(u\'Sheet1\', cell_overwrite_ok=True) #将首行的首列设为\'歌曲名\' sheet1.write(0, 0, \'歌曲名\') r = 1 #r为row(行) for temp in data: sheet1.write(r, 0, temp) r += 1 #保存文件到给定的save_url book.save(saveurl) print(f\'写入文件成功,地址为{saveurl}\') #读取文件 def read_file(singer): try: data = pd.read_excel(f\'D:/{singer}\\\'s_songs.xls\', names=[\'song_name\']) print(\'读取文件成功\') #返回文件内的数据 return data except: "文件不存在或文件名错误" #主函数 def main(): #临界值20个专辑 times = 20 #输入歌手名称 singer = \'陈奕迅\' #专辑mid列表 albumlist = getalbum(times, singer) #歌曲列表 songlist = getsong(albumlist) #存储excel文件的位置 saveurl = f\'D:\\\\{singer}\\\'s_songs.xls\' #写入文件 write_file(songs, saveurl) #读取文件 read_file(singer) if __name__ == \'__main__\': main()
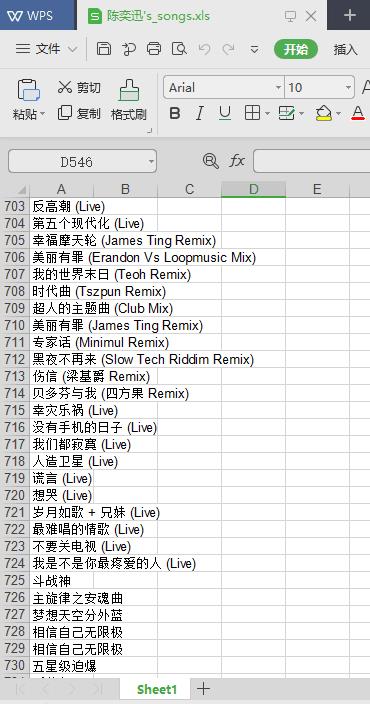
运行结果(截图)如下:


该Excel文件里面有陈奕迅的所有专辑名称和歌曲名称,列为一个名单,共700多行。部分截图如下:


1.数据爬取与采集
相关代码如下(对QQ音乐url中的相关数据进行采集):
#爬取页面函数 def catchhtml(url): kv = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36\'} #异常判断 try: data = requests.get(url, headers=kv, timeout=10) #查看状态码,判断爬取状态 data.raise_for_status() data.encoding = data.apparent_encoding #返回页面 return data.text except: return "爬取失败"
2.对数据进行清洗和处理
相关代码如下(获取想要的信息,即陈奕迅专辑名和详细的歌曲名):
#获取专辑 def getalbum(times, singer): all_albummid = [] for num in range(1, times): #获取信息的目标url url = f\'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&remoteplace=txt.yqq.album&t=8&p={num}&n=5&w={singer}&format=json\' html = catchhtml(url) # 解析json数据 js = json.loads(html) # 定位到albumMID albumlist = js[\'data\'][\'album\'][\'list\'] for song in albumlist: albumMid = song[\'albumMID\'] all_albummid.append(albumMid) return all_albummid #获取专辑内的歌曲名 def getsong(albumlist): songs = [] for i in albumlist: html = catchhtml(f\'https://y.qq.com/n/yqq/album/{i}.html\') #bs4格式化html页面 soup = BeautifulSoup(html, "html.parser") #遍历span标签内a标签的字符串 for span in soup.find_all("span", attrs="songlist__songname_txt"): #将字符串放进列表 songs.append(str(span.a.string).strip()) return songs
3.文本分析(可选):jieba分词、wordcloud可视化
无。
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
由于是在爬取歌手陈奕迅的专辑名称和歌曲名称,都是具体的数据,只能用文字来表示数据,因此不需要使用可视化!
#读取文件
def read_file(singer):
try:
data = pd.read_excel(f\'D:/{singer}\\\'s_songs.xls\', names=[\'song_name\'])
print(\'读取文件成功\')
#返回文件内的数据
return data
except:
"文件不存在或文件名错误"
5.数据持久化
数据持久化即为数据存储,相关代码如下:
#将数据存入文件 def write_file(data, saveurl): # 创建Workbook,相当于创建Excel book = xlwt.Workbook(encoding=\'utf-8\') # 创建sheet,Sheet1为表的名字,cell_overwrite_ok为是否覆盖单元格 sheet1 = book.add_sheet(u\'Sheet1\', cell_overwrite_ok=True) #将首行的首列设为song_name sheet1.write(0, 0, \'歌曲名\') r = 1 #r为row(行) for temp in data: sheet1.write(r, 0, temp) r += 1 #保存文件到给定的save_url book.save(saveurl) print(f\'写入文件成功,地址为{saveurl}\')
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
通过对主体数据的提取分析,可以清楚地知道歌手陈奕迅自出道以来大部分的曲目专辑,一目了然。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过对数据的爬取,基本掌握了来龙去脉。但是在进行具体的数据清洗时有些不够熟练,希望可以更深入地掌握。
以上是关于Python高级应用程序设计任务的主要内容,如果未能解决你的问题,请参考以下文章