Python 文本相似度分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 文本相似度分析相关的知识,希望对你有一定的参考价值。
- 环境
Anaconda3 Python 3.6, Window 64bit
- 目的
利用 jieba 进行分词,关键词提取
利用gensim下面的corpora,models,similarities 进行语料库建立,模型tfidf算法,稀疏矩阵相似度分析
- 代码


# -*- coding: utf-8 -*- import jieba from gensim import corpora, models, similarities from collections import defaultdict # 定义文件目录 work_dir = "D:/workspace/PythonSdy/data" f1 = work_dir + "/t1.txt" f2 = work_dir + "/t2.txt" # 读取文件内容 c1 = open(f1, encoding=‘utf-8‘).read() c2 = open(f2, encoding=‘utf-8‘).read() # jieba 进行分词 data1 = jieba.cut(c1) data2 = jieba.cut(c2) data11 = "" # 获取分词内容 for i in data1: data11 += i + " " data21 = "" # 获取分词内容 for i in data2: data21 += i + " " doc1 = [data11, data21] # print(doc1) t1 = [[word for word in doc.split()] for doc in doc1] # print(t1) # # frequence频率 freq = defaultdict(int) for i in t1: for j in i: freq[j] += 1 # print(freq) # 限制词频 t2 = [[token for token in k if freq[j] >= 3] for k in t1] print(t2) # corpora语料库建立字典 dic1 = corpora.Dictionary(t2) dic1.save(work_dir + "/yuliaoku.txt") # 对比文件 f3 = work_dir + "/t3.txt" c3 = open(f3, encoding=‘utf-8‘).read() # jieba 进行分词 data3 = jieba.cut(c3) data31 = "" for i in data3: data31 += i + " " new_doc = data31 print(new_doc) # doc2bow把文件变成一个稀疏向量 new_vec = dic1.doc2bow(new_doc.split()) # 对字典进行doc2bow处理,得到新语料库 new_corpor = [dic1.doc2bow(t3) for t3 in t2] tfidf = models.TfidfModel(new_corpor) # 特征数 featurenum = len(dic1.token2id.keys()) # similarities 相似之处 # SparseMatrixSimilarity 稀疏矩阵相似度 idx = similarities.SparseMatrixSimilarity(tfidf[new_corpor], num_features=featurenum) sims = idx[tfidf[new_vec]] print(sims)
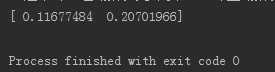
- 结果展示
从结果可以得出:被对比的文件3 和文件2内容更相近。
以上是关于Python 文本相似度分析的主要内容,如果未能解决你的问题,请参考以下文章