不同品种猫猫有多相似呢,Python 文本相似度计算
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不同品种猫猫有多相似呢,Python 文本相似度计算相关的知识,希望对你有一定的参考价值。
????????关注后回复 “进群” ,拉你进程序员交流群????????
作者丨木下瞳
来源丨木下学Python


前言
之前小编呢爬过猫猫 20w 的交易数据,做了一个简单的数据分析最近碰到了文本相似度的问题,想到了猫猫数据中有品种的相关描述,于是用品种描述文本来研究一下文本相似度计算的。
查找了一下资料找到了几种实现方法,实现的目的都一样,小编就做了一个对比。
数据处理

数据原始有很多列,我们需要把 O 列直至末尾的这些描述每个品种猫猫的文本合为一列:


以此计算每个品种的描述与其他品种描述的相似度,把“描述”列作为文本列表,“品种”作为索引,两两计算。
合并后的文本指数其实是挺多的,这样便于对比出那种方法更快。
difflib
difflib 是 Python 的内置库,基于 Ratcliff-Obershelp 算法(格式塔模式匹配)。

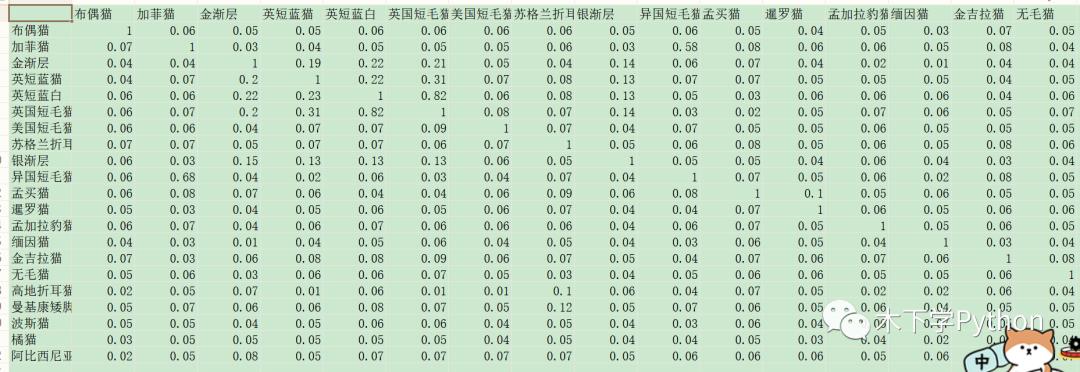
计算值是 0-1 之间的,越接近 1 说明文本越相似。
fuzzywuzzy
fuzzywuzzy 是一个第三方库,基于莱文斯坦距离,需要安装 python-Levenshtein,fuzzywuzzy,直接 pip 即可。
这个原理最容易说明,莱文斯坦距离一个字符串变为另外一个字符串经过删除,插入,替换的编辑距离。

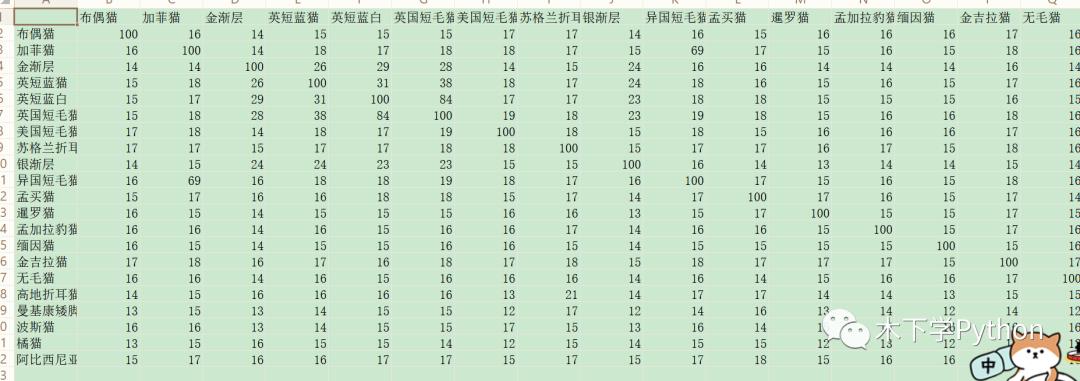
计算的值介于 0-100,值越大说明两文本越相似。
余弦距离
接下来介绍的集中距离都是需要先将文本进行向量化的,通过向量化计算显示距离。
文本向量化必须两个对比的文本同时向量化操作,确保两文本向量化的长度一样才可进行计算,部分代码:

两对比文本向量化后,再进行相似度计算:

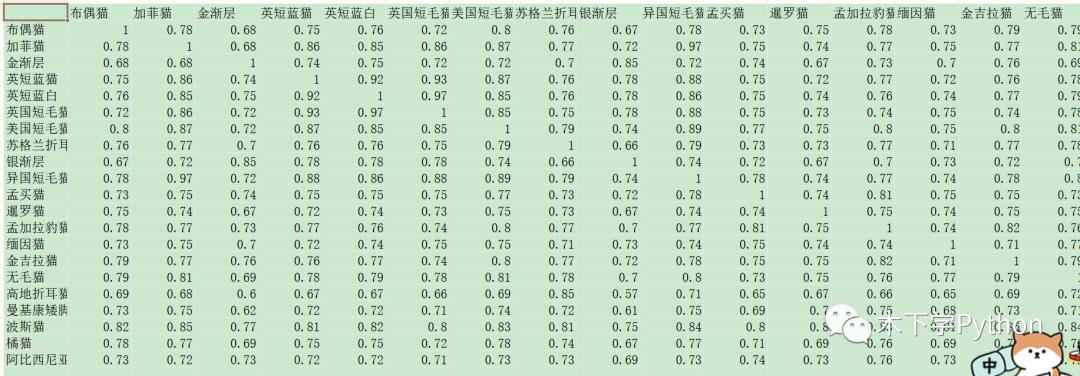
余弦相似度,值介于 0-1,越大说明两文本越相似。
从结果上看对比前两个,值要大于 0.9 才相当于有 60% 以上的相似度,前两种方法更为直观。
其他距离
其他距离的计算方法还有欧式距离,曼哈顿距离,切比雪夫距离,杰尔德距离,汉明距离,这些值的范围没有上限,越小说明文本越相似。
还有皮尔逊相关系数,这个计算的值介于 0-1,值越大说明文本越相似。
它们的实现方式都与余弦相似,详细可查看源代码。
结果

小编使用了所有方法计算相似度,fuzzywuzz 方法计算的时间最快,其次是 difflib,且结果比较直观,其他方法都需要文本向量化在比较,所以在文本较长时,时间有点久。
最后使用 fuzzywuzz 计算的相似度,绘制热力相关图直观的展示猫猫品种哪些描述较为相似:
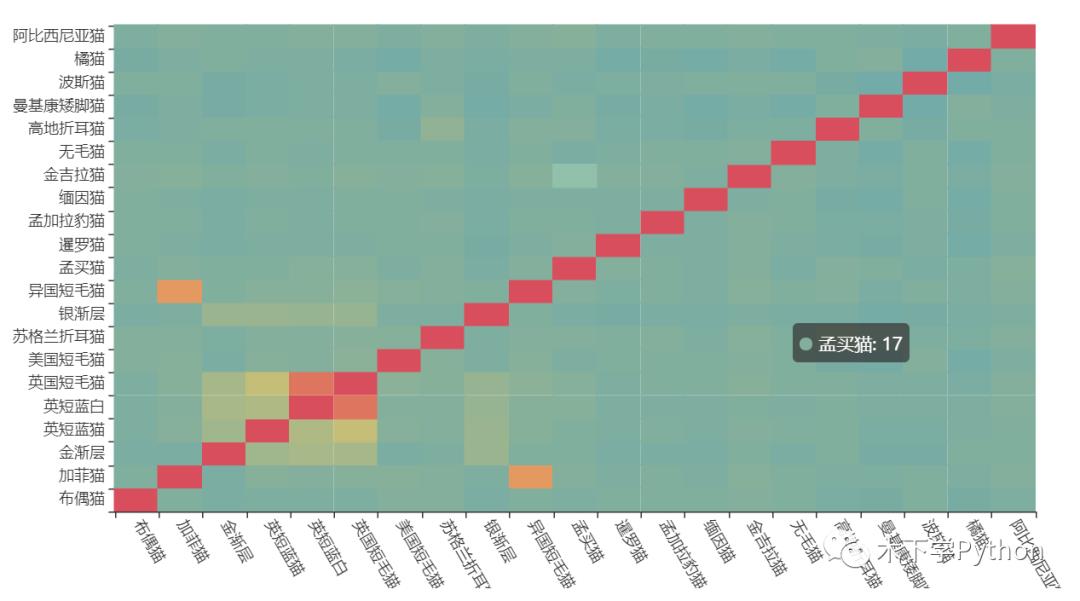
异国短毛猫与加菲猫描述相似度较高,英囯蓝白与英国短毛猫相似度也较高。
这样一个文本相似度计算就完成了。
源码:
https://github.com/5zjk5/text_similarity
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击????卡片,关注后回复【面试题】即可获取
在看点这里![]() 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于不同品种猫猫有多相似呢,Python 文本相似度计算的主要内容,如果未能解决你的问题,请参考以下文章